tensorflow serving初体验
Posted 中移苏研大数据博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow serving初体验相关的知识,希望对你有一定的参考价值。
1. tensorflow serving 介绍
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习开发框架,tensorflow serving则是一个用于机器学习模型 serving 的高性能开源项目,TensorFlow Serving帮助开发者把他们TensorFlow训练的模型(甚至可以扩展到其它类型的模型)部署到生产环境中。TensorFlow Serving是一个基于Apache 2.0协议的C++开源系统,目前可通过github获得。
通过TensorFlow,开发者可以很容易的建立机器学习算法并通过一定格式的数据输入进行训练模型。TensorFlow Serving则专注于使得这些模型在生产环境中使用。设计目的是开发者通过TensroFlow训练模型,使用TensorFlow Serving的API响应客户端的外部请求。这使得开发者可以基于随着时间变化的真实数据对不同模型进行实验,原地得到一个稳定的架构与API。TensorflowServing能够简化并加速从模型到生产应用的过程。
TensorFlow Serving的典型的流程如上:学习者(Learner,比如TensorFlow)根据输入数据进行模型训练。等模型训练完成、验证之后,模型会被发布到TensorFlow Serving系统服务器端。客户端提交请求,由服务端返回预测结果。客户端和服务端之间的通信采用的是grpc(一种高性能、google开源的RPC框架)。下面将通过实例为大家介绍tensorflow serving的使用。
2. tensorflow serving 实践
本节将为大家介绍实际使用中tensorflow serving的使用,以及在使用过程中遇到的一些坑(此处已经默认完成了tensorflow serving相关服务的部署),以逻辑回归为例。
2.1 模型准备
线性回归的计算公式为y = wx + b,而逻辑回归则是在线性回归的外面套了一层sigmoid函数y = sigmoid (wx + b),而多分类的逻辑回归则是将sigmoid函数替换为softmax,总体实现较为简单。
在tensorflow中,模型包含2个部分:参数&图
在这里参数为w和b,图为y=softmax(wx+b)的计算结构。
(1) 导入checkpoint模型文件中的参数以及图模型:
一般情况下,tensorflow存储的模型格式如下:
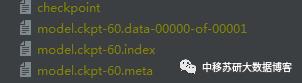
在checkpoint文件中存储的为最近的几次迭代保存的模型名称以及路径
在index文件中保存的为模型参数的名称以及具体属性
在data文件中保存的为模型参数的数值
在meta文件中保存的为模型的图
通过如下方式我们可以将模型重新导入(包括图以及参数)
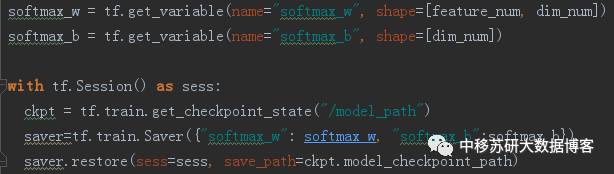 在算法中我们采用softmax_w以及softmax_b来命名w,b这两个参数。
在算法中我们采用softmax_w以及softmax_b来命名w,b这两个参数。
(2) 构建模型的输入输出以及调用方式
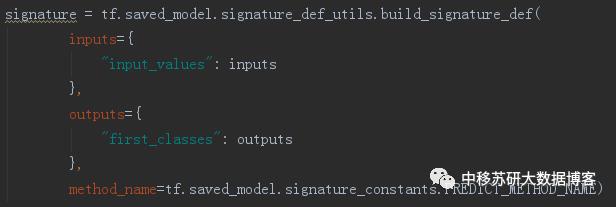
此处method_name的调用方式设置与客户端的调用方式必须一致
在tensorflow1.1的API中主要提供了三种类型的调用,分别为:
分类问题对应客户端中的classify方法
CLASSIFY_METHOD_NAME
回归问题对于客户端中的regress方法
REGRESS_METHOD_NAME
预测问题对应客户端中的predict方法(基本与分类问题相同,分类问题可以多一个参数“classes”)
PREDICT_METHOD_NAME
(3) 在准备工作全部完成后,就可以导入算法模型了。
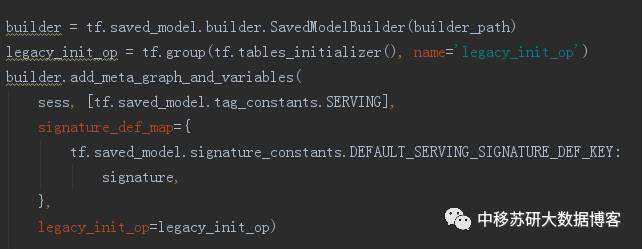
其中signature即刚刚定义的输入输出,legacy_init_op即图(即图中定义的算法操作)。tf.saved_model.tag_constants.SERVING表示默认服务。
最后使用builder.save(save_path)完成模型的准备,此时就可以将这个模型导入到任何一个tensorflow serving中提供相应的算法服务了。
2.2 服务调用
此处服务调用以java客户端调用举例为主(舆情中内容过滤使用的为java客户端,python调用会更加简单一些。)
2.2.1 客户端
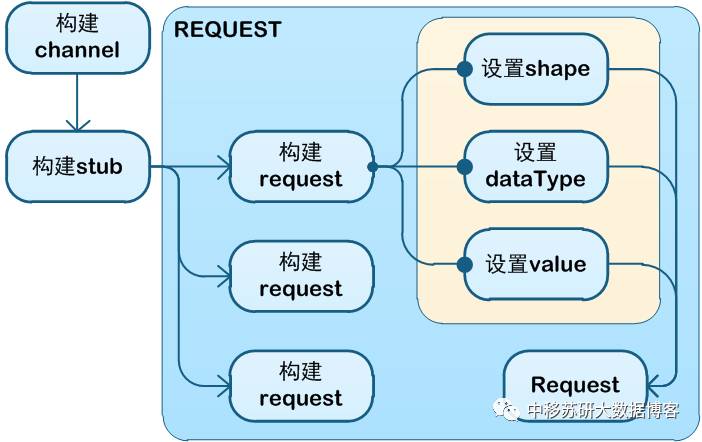
tensorflow客户端整体流程如上。
其中构建channel与stub在初始化阶段完成。
channel可以使用自动选择channelBuilder的ManagedChannelBuilder,或者是自定义的选择NettyChannelBuilder或者OkHttpChannelBuilder,需要注意的是,自定义的builder需要定制nameResolverFactory(比如常用的DnsNameResolverProvider)下面是一个简单的例子:

stub可以构建阻塞式的newBlockingStub以及非阻塞式的newFutureStub。
request阶段可以分为request准备以及request发送两个部分,其中request准备主要是构建符合在模型准备阶段设置的数据的类型、值以及形状。在发送阶段则是使用classify等方式进行rpc报文发送并接收相关结果。(支持批量计算【由模型准备阶段的输入是否支持有关】)
注意:此处使用的protobuf版本为3.X及以上,且与2.X不兼容,这也意味着,TF客户端无法与现有的Hadoop平台兼容(现有hadoop平台基本都是基于protobuf 2.5)。
解决方案:
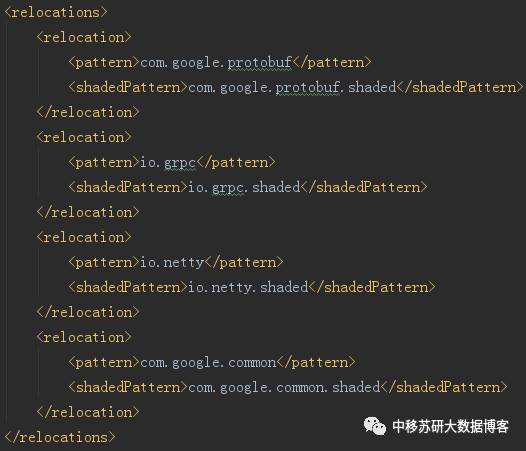
1、在客户端使用maven-shade-plugin。并且将protobuf、grpc、netty、guava相关jar包进行重定向。如下:
2、进行自定义channel构建:其原因是如果采用自动channel构建,会自动调用平台依赖包中的channel(低版本),无法定向到已经重定向的channel。
2.2.2 服务端
服务端使用非常方便,一条命令就能直接搞定。
bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server--port=10086 --model_name=wxfilter --model_base_path=/home/sycmss/filter_model/
以下列举了一些在serving时经常用得到的参数进行说明。
参数名 |
类型 |
说明 |
--port=8500 |
int32 |
监听端口 |
--model_config_file="" |
String |
配置文件位置,如果使用了model_name, model_base_path以及model_version_policy那么这个参数会被忽略。当需要一次性导入多个参数时可以使用该参数。 |
--model_name="default" |
String |
模型名称,在客户端需要指定调用的是哪个模型,否则调用default。 |
--model_base_path="" |
String |
模型存储位置 |
--model_version_policy=“LAST_VERSION” |
String |
默认动态载入最新版本的模型,可以指定载入版本。 |
--file_system_poll_wait_seconds |
int64 |
动态扫描载入最新版本模型的时间。(单位:秒) |
其中config_file的配置如下(可以一次在一个端口导入多个模型):
model_config_list: {
config: {
name: "mnist",
base_path: "/tmp/mnist_model",
model_platform: "tensorflow"
},
config: {
name: "inception",
base_path: "/tmp/inception_model",
model_platform: "tensorflow"
}
}
2.3 测试效果
测试环境: Tensorflow服务器:物理机,内存128G+8核CPU
(相对于简单的logistic regression + softmax来说,GPU并没有太大的优势)
客户端接口测试工具(笔记本):idea+testing
单次接口Query时间小于10ms。
2.4 效果对比
使用tensorflow serving调用算法与传统使用jar包方式调用算法接口相比,采用前者具有如下优势:
松耦合:
算法不再和语言以及程序捆绑,只需在客户端中定义符合条件的输入输出,任何客户端都可以使用该服务。此外,只要是相同的输入与输出,不论算法怎么变,都可以使用同一个服务(对于后续算法的优化极为有利)。
高扩展性:
一个进程即一个TF serving服务,相互之间无影响。可以在多个节点,甚至在同一个节点上部署多个服务,可以通过负载均衡将它们串起来,提供分布式的多节点的服务。
更高效与安全的上线流程:
模型更新迭代非常方便,只需要将模型文件放置入模型文件夹即可自动完成最新版本模型的上线。此外,可以通过测试客户端随时检查服务的效果(与其他程序不捆绑),还可以随时进行历史模型版本的回滚。
3. tensorflow serving 适用场景
以下列举了一些场景,这些情况下tensorflowserving的这种服务模式可能会比较适用。
3.1 算法模型(参数)过大
例如,自然语言处理中使用到的词向量(word embedding),可将单词转换为向量表示。一般会作为深度神经网络的输入使用。
假设单词表为30万,维度为1024,数据格式为float。
300000 * 1024 * 4 = 1171875kb = 1172mb
那么在java中就需要1.1G左右的空间来对该模型进行存储,如果词表变为300万,特征变为10240呢,这个存储代价将变得很难接受。
在spark-streaming中,由于不同服务器之间的内存在使用上无法直接共享,使用算法模型时,需要将算法的模型导入到不同的extractor中,模型过大会导致巨大的资源浪费。而使用tensorflow serving则只需加载一次模型。
3.2 模型参数不适宜泄露
在某些情况下,由于模型参数比较简单,在对方拿到模型参数后能够毫不费力的模仿出相同的算法,且能够省去了巨量的人力成本(调试参数,训练数据)。对于这种情况,以tensorflow serving的方式提供算法服务能够预防模型的泄露。
3.3 模型更新(优化)频繁
在算法优化频繁的情况下,我们需要不停的进行算法的集成,以及集成测试。如果直接提供tensorflow serving式的服务的话,可以直接跳过算法集成与集成测试。
此外tensorflow seving提供了版本管理,如果对现有优化的算法不满意的话,还可以对算法版本进行回滚。
3.4 算法开发的语言与后台不一致
一般来说,因为相关组件比较完善,实现起来较为方便,python是深度学习算法实现的主流语言,而像舆情项目等后台使用java,scala作为主要开发语言。对于跨语言的调用接口实现较为复杂,且调试相对比较难。
在这种情况下,将算法与后台处理分离不失为一种非常有效的解决办法。
4. tensorflow serving 的问题与不足
在使用tensorflow serving的过程中也发现了一些不足:
1. tensorflow serving目前对分布式的支持不是很好,没有原生态的分布式部署,且目前没有统一的模型管理,只能通过第三方进行负载均衡。
2. tensorflow serving 相关组件较新,对现有平台支持不是很好,比如protobuf版本只支持3.0及以上版本。
3. tensorflow serving目前不支持自定义数据的输入,不支持自定义数据的预处理。只能提供纯粹的计算,需要在客户端进行数据预处理。
5. 总结
Tensorflow Serving补全了tensorflow从算法开发到部署上线的最后一块短板,完善了tensorflow的生态圈,简化加速了从模型到生产应用的过程。在提供算法微服务的时候,不妨考虑下使用Tensorflow Serving,这可以让算法开发与上线更加便捷。
虽然目前来看Tensorflow Serving还存在这样那样的不足,但是我们知道tensorflow是github上目前最热门的开源项目之一(到2017年9月25号为止tensoflow已经有1000+的贡献者,22000+的commit,70000+的star),tensorflowserving在其带动下,必然会日趋完善,给我们的模型应用上线带来便利。
以上是关于tensorflow serving初体验的主要内容,如果未能解决你的问题,请参考以下文章