Protocol Buffers:编码与解码
Posted shine-lee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Protocol Buffers:编码与解码相关的知识,希望对你有一定的参考价值。
博客:blog.shinelee.me | 博客园 | CSDN
Message Structure
在上一篇文章中我们提到,对于序列化后字节流,需要回答的一个重要问题是“从哪里到哪里是哪个数据成员”。
message中每一个field的格式为:
required/optional/repeated FieldType FieldName = FieldNumber(a unique number in current message)
在序列化时,一个field对应一个key-value对,整个二进制文件就是一连串紧密排列的key-value对,key也称为tag,先上图直观感受一下,图片来自Encoding and Evolution:
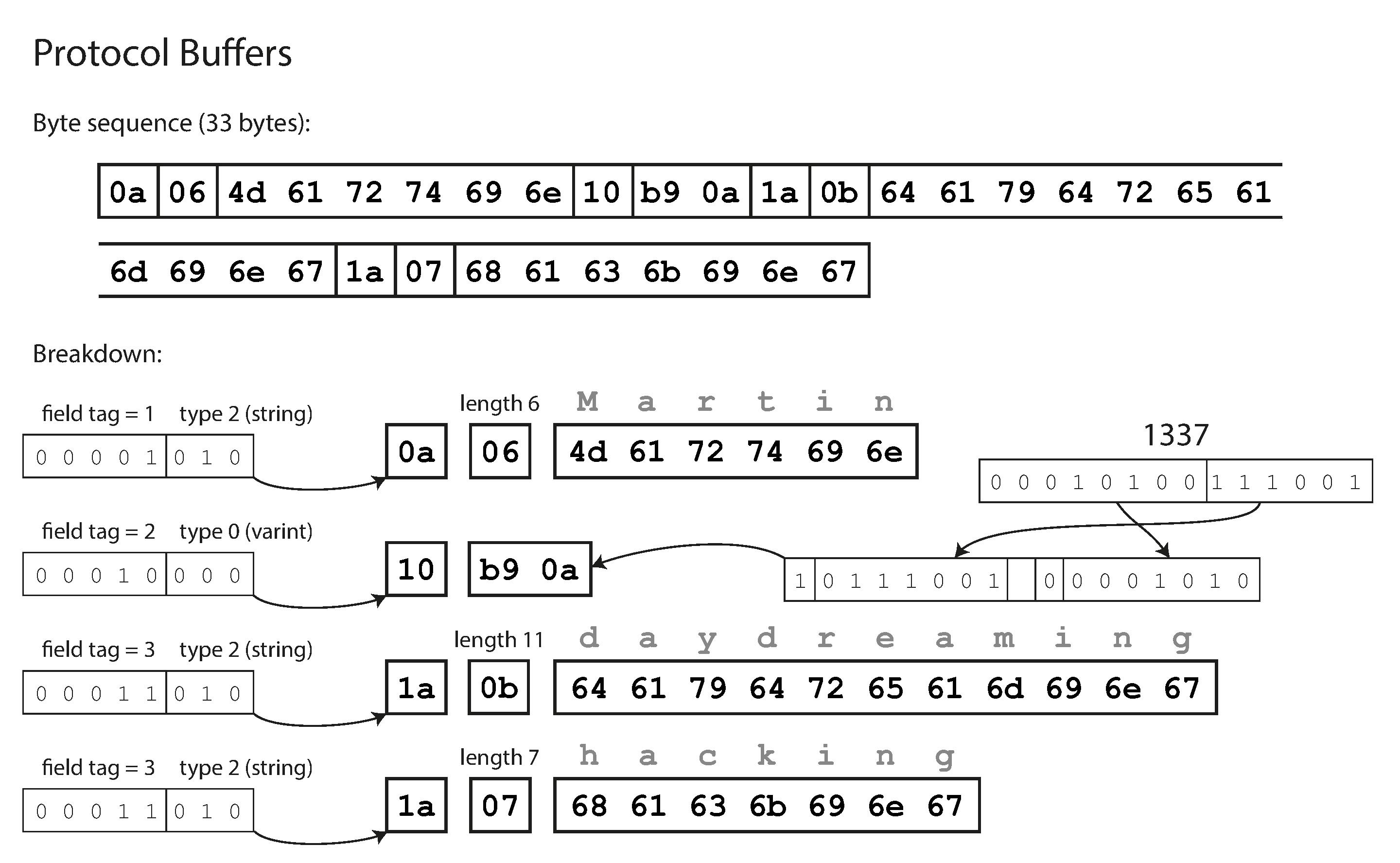
key由wire type和FieldNumber两部分编码而成, 具体地key = (field_number << 3) | wire_type,field_number 部分指示了当前是哪个数据成员,通过它将cc和h文件中的数据成员与当前的key-value对应起来。
key的最低3个bit为wire type,什么是wire type?如下表所示:
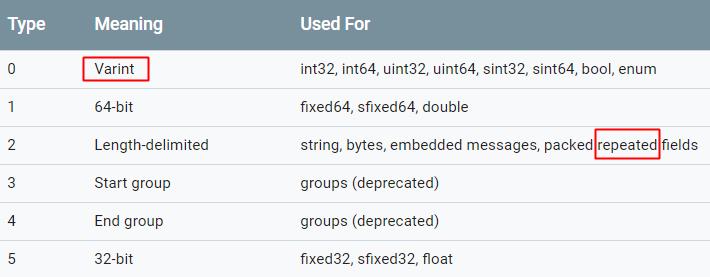
wire type被如此设计,主要是为了解决一个问题,如何知道接下来value部分的长度(字节数),如果
- wire type = 0、1、5,编码为 key + 数据,只有一个数据,可能占数个字节,数据在编码时自带终止标记
- wire type = 2,编码为 key + length + 数据,length指示了数据长度,可能有多个数据,顺序排在length后
解码代码一窥
接下来,我们直接看一下example.pb.cc及相关的源码,看下key-value对是如何解析的。解码过程相对简单,理解了解码过程,编码也就比较显然了。
// example.proto
package example;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
}// in example.pb.cc
bool Person::MergePartialFromCodedStream(
::google::protobuf::io::CodedInputStream* input) {
#define DO_(EXPRESSION) if (!PROTOBUF_PREDICT_TRUE(EXPRESSION)) goto failure
::google::protobuf::uint32 tag;
// @@protoc_insertion_point(parse_start:example.Person)
for (;;) {
::std::pair<::google::protobuf::uint32, bool> p = input->ReadTagWithCutoffNoLastTag(127u);
tag = p.first;
if (!p.second) goto handle_unusual;
switch (::google::protobuf::internal::WireFormatLite::GetTagFieldNumber(tag)) {
// required string name = 1;
case 1: {
if (static_cast< ::google::protobuf::uint8>(tag) == (10 & 0xFF)) { // 10 = (1 << 3) + 2
DO_(::google::protobuf::internal::WireFormatLite::ReadString(
input, this->mutable_name()));
::google::protobuf::internal::WireFormat::VerifyUTF8StringNamedField(
this->name().data(), static_cast<int>(this->name().length()),
::google::protobuf::internal::WireFormat::PARSE,
"example.Person.name");
} else {
goto handle_unusual;
}
break;
}
// required int32 id = 2;
case 2: {
if (static_cast< ::google::protobuf::uint8>(tag) == (16 & 0xFF)) { // 16 = (2 << 8) + 0
HasBitSetters::set_has_id(this);
DO_((::google::protobuf::internal::WireFormatLite::ReadPrimitive<
::google::protobuf::int32, ::google::protobuf::internal::WireFormatLite::TYPE_INT32>(
input, &id_)));
} else {
goto handle_unusual;
}
break;
}
// optional string email = 3;
case 3: {
if (static_cast< ::google::protobuf::uint8>(tag) == (26 & 0xFF)) {
DO_(::google::protobuf::internal::WireFormatLite::ReadString(
input, this->mutable_email()));
::google::protobuf::internal::WireFormat::VerifyUTF8StringNamedField(
this->email().data(), static_cast<int>(this->email().length()),
::google::protobuf::internal::WireFormat::PARSE,
"example.Person.email");
} else {
goto handle_unusual;
}
break;
}
default: {
handle_unusual:
if (tag == 0) {
goto success;
}
DO_(::google::protobuf::internal::WireFormat::SkipField(
input, tag, _internal_metadata_.mutable_unknown_fields()));
break;
}
}
}
success:
// @@protoc_insertion_point(parse_success:example.Person)
return true;
failure:
// @@protoc_insertion_point(parse_failure:example.Person)
return false;
#undef DO_
}整段代码在循环地解析input流,遇到1个tag(key),根据其wire type和数据类型调用相应的解析函数,如果是string,则调用ReadString,ReadString会一直调用到ReadBytesToString,如果是int32,则调用ReadPrimitive,ReadPrimitive中会进一步调用ReadVarint32。可以看到,生成的example.pb.cc决定了遇到哪个tag调用哪个解析函数,从输入流中解析出值,赋给对应的成员变量,而真正进行解析的代码实际上是Protobuf的源码,如下所示:
// in wire_format_lit.cc
inline static bool ReadBytesToString(io::CodedInputStream* input,
string* value) {
uint32 length;
return input->ReadVarint32(&length) &&
input->InternalReadStringInline(value, length);
}
// in wire_format_lit.h
template <>
inline bool WireFormatLite::ReadPrimitive<int32, WireFormatLite::TYPE_INT32>(
io::CodedInputStream* input,
int32* value) {
uint32 temp;
if (!input->ReadVarint32(&temp)) return false;
*value = static_cast<int32>(temp);
return true;
}
// in coded_stream.h
inline bool CodedInputStream::ReadVarint32(uint32* value) {
uint32 v = 0;
if (PROTOBUF_PREDICT_TRUE(buffer_ < buffer_end_)) {
v = *buffer_;
if (v < 0x80) {
*value = v;
Advance(1);
return true;
}
}
int64 result = ReadVarint32Fallback(v);
*value = static_cast<uint32>(result);
return result >= 0;
}可以看到,如果遇到int32的tag,直接读取接下来的数据,如果遇到string的tag,会先读一个Varint32的length,然后再读length个字节的数据。
这里频繁出现了varint,length是varint,存储的int32数据也是varint,那varint是什么?
varint
varint是一种可变长编码,使用1个或多个字节对整数进行编码,可编码任意大的整数,小整数占用的字节少,大整数占用的字节多,如果小整数更频繁出现,则通过varint可实现压缩存储。
varint中每个字节的最高位bit称之为most significant bit (MSB),如果该bit为0意味着这个字节为表示当前整数的最后一个字节,如果为1则表示后面还有至少1个字节,可见,varint的终止位置其实是自解释的。
在Protobuf中,tag和length都是使用varint编码的。length和tag中的field_number都是正整数int32,这里提一下tag,它的低3位bit为wire type,如果只用1个字节表示的话,最高位bit为0,则留给field_number只有4个bit位,1到15,如果field_number大于等于16,就需要用2个字节,所以对于频繁使用的field其field_number应设置为1到15。
比如正整数150,其使用varint编码如下(小端存储):
// proto file
message Test1 {
optional int32 a = 1;
}
// c++ file
// set a = 150
// binary file, in hex
// 08 96 01其中08为key, 96 01为150的varint编码,解释如下

有关varint的更多内容,可以参见wiki Variable-length quantity。
至此,key-value的编码方式我们已经解决了一半,还剩value部分没有解决,接下来看看Protobuf数据部分是如何编码的。
Protobuf中的整数和浮点数
Protobuf中整数也是通过varint进行编码,移除每个字节的MSB,然后拼接在一起,可以得到一个含有数个字节的buffer,这个buffer该怎么解释还需要参考具体的数据类型。
对于int32或int64,正数直接按varint编码,数据类型为int32或int64的负数统一被编码为10个字节长的varint(补码)。
如果是sint32或sint64,则采用ZigZag方式进行编码,如下表所示:
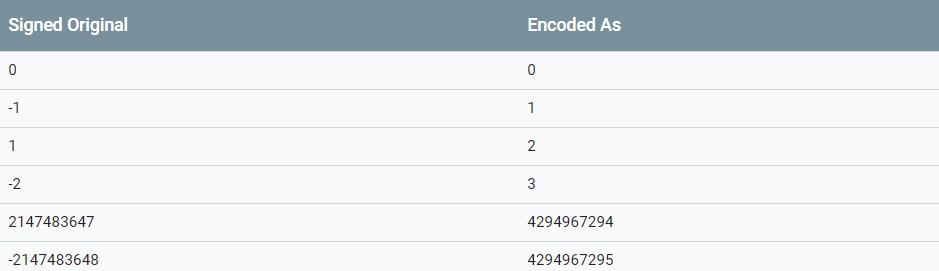
sint32 n被编码为 (n << 1) ^ (n >> 31)对应的varint,sint64 n被编码为 (n << 1) ^ (n >> 63)对应的varint,这样,绝对值较小的整数只需要较少的字节就可以表示。
至于浮点数,对应的wire type为1或5,直接按小端存储。
Length-delimited相关类型
主要有3类:string、嵌套message以及packed repeated fields。它们的编码方式统一为 tag + length + 数据,只是数据部分有所差异。
string的编码为 key + length + 字符,参看开篇的图片已经很清晰了。
嵌套message也很简单,直接将嵌套message部分的编码接在length后即可,如下所示:
// proto file
message Test1 {
optional int32 a = 1;
}
message Test3 {
optional Test1 c = 3;
}
// cpp file
// set a = 150
// message Test3 binary file, in hex
// 1a 03 08 96 01其中,1a为c的key,03为c的长度,接下来的08 96 01为a的key+value。
packed repeated fields,指的是proto2中声明了[packed=true]的repeated varint、32bit or 64bit数据,proto3中repeated默认packed,如下所示
// in proto2
message Test4 {
repeated int32 d = 4 [packed=true];
}
// in proto3
message Test4 {
repeated int32 d = 4;
}
// 3, 270, 86942压缩存储如下,in hex
22 // key (field number 4, wire type 2), 0x22 = 34 = (4 << 3) + 2
06 // payload size (6 bytes), length
03 // first element (varint 3)
8E 02 // second element (varint 270)
9E A7 05 // third element (varint 86942)6个字节根据varint的MSB可自动分割成3个数据。对这种packed repeated fields,在Protobuf中会以RepeatedField对象承载,支持get-by-index、set-by-index和add(添加元素)操作。
小结
至此,二进制文件中key-value对的编码方式已基本介绍完毕,后面将通过一个相对复杂的例子,将这些琐碎的编码方式串起来,以加深理解。
参考
- Protocol Buffers Encoding
- Variable-length quantity
- Chapter 4. Encoding and Evolution, Designing Data-Intensive Applications by Martin Kleppmann
以上是关于Protocol Buffers:编码与解码的主要内容,如果未能解决你的问题,请参考以下文章
Google Protocol Buffers - 对编码解码 base64 char * c 字符串协议缓冲区数据感到困惑