协议缓冲区(Protocol Buffers)
Posted 森明帮大于黑虎帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了协议缓冲区(Protocol Buffers)相关的知识,希望对你有一定的参考价值。
一、概述
协议缓冲区提供了一种语言中立、平台中立、可扩展的机制,用于以向前兼容和向后兼容的方式序列化结构化数据。它类似于 JSON,只是它更小更快,并且生成本地语言绑定。
协议缓冲区是定义语言(在 .proto文件中创建)、proto 编译器生成的与数据接口的代码、特定于语言的运行时库以及写入文件(或通过网络连接)。
二、协议缓冲区解决了哪些问题
协议缓冲区为大小高达几兆字节的类型化结构化数据包提供了一种序列化格式。该格式适用于临时网络流量和长期数据存储。可以使用新信息扩展协议缓冲区,而无需使现有数据无效或需要更新代码。
协议缓冲区是 Google 最常用的数据格式。它们广泛用于服务器间通信以及磁盘上数据的归档存储。协议缓冲区消息和服务由工程师编写的.proto文件描述。下面显示了一个示例message:
message Person
optional string name = 1;
optional int32 id = 2;
optional string email = 3;
在构建.proto文件时调用 proto 编译器以生成各种编程语言的代码( 在本主题后面的跨语言兼容性中介绍)来操作相应的协议缓冲区。每个生成的类都包含每个字段的简单访问器和方法,用于序列化和解析整个结构与原始字节之间的关系。下面向您展示了一个使用这些生成方法的示例:
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.build();
output = new FileOutputStream(args[0]);
john.writeTo(output);
由于协议缓冲区在 Google 的各种服务中广泛使用,并且其中的数据可能会保留一段时间,因此保持向后兼容性至关重要。协议缓冲区允许无缝支持对任何协议缓冲区的更改,包括添加新字段和删除现有字段,而不会破坏现有服务。 有关此主题的更多信息,请参阅本主题后面的在不更新代码的情况下更新原型定义。
三、使用协议缓冲区有什么好处
协议缓冲区非常适合任何需要以语言中立、平台中立、可扩展的方式序列化结构化、类似记录、类型化数据的情况。它们最常用于定义通信协议(与 gRPC 一起)和数据存储。
使用协议缓冲区的一些优点包括:
- 紧凑的数据存储。
- 快速解析。
- 许多编程语言的可用性。
- 通过自动生成的类优化功能。
四、跨语言兼容性
以任何受支持的编程语言编写的代码都可以读取相同的消息。您可以让一个平台上的 Java 程序从一个软件系统捕获数据,根据.proto定义对其进行序列化,然后在另一个平台上运行的单独 Python 应用程序中从序列化数据中提取特定值。
协议缓冲区编译器 protoc 直接支持以下语言:
- C++。
- C#。
- Java。
- Kotlin。
- Objective-C。
- php。
- Python。
- Ruby。
Google 支持以下语言,但项目的源代码位于 GitHub 存储库中。protoc 编译器使用这些语言的插件:
- Dart。
- Go。
其他语言不直接由 Google 支持,而是由其他 GitHub 项目支持。这些语言包含在Protocol Buffers 的第三方插件中。
五、跨项目支持
您可以通过在驻留在特定项目代码库之外的文件中定义message类型来 跨项目使用协议缓冲区。.proto如果您正在定义message您预计将在您的直接团队之外广泛使用的类型或枚举,您可以将它们放在自己的文件中而没有依赖关系。
在 Google 中广泛使用的几个原型定义示例是 timestamp.proto 和 status.proto。
六、在不更新代码的情况下更新原型定义
软件产品向后兼容是标准,但向前兼容却不太常见。只要您 在更新定义时遵循一些简单的做法.proto ,旧代码将毫无问题地读取新消息,而忽略任何新添加的字段。对于旧代码,删除的字段将具有默认值,删除的重复字段将为空。有关什么是“重复”字段的信息,请参阅本主题后面的协议缓冲区定义语法。
新代码也将透明地读取旧消息。旧消息中不会出现新字段;在这些情况下,协议缓冲区提供了一个合理的默认值。
七、什么时候协议缓冲区不适合
协议缓冲区并不适合所有数据。尤其是:
- 协议缓冲区倾向于假设整个消息可以一次加载到内存中并且不大于对象图。对于超过几兆字节的数据,考虑不同的解决方案;在处理较大的数据时,由于序列化副本,您可能会有效地获得多个数据副本,这可能会导致内存使用量出现惊人的峰值。
- 当协议缓冲区被序列化时,相同的数据可以有许多不同的二进制序列化。如果不完全解析它们,就无法比较两条消息的相等性。
- 消息未压缩。虽然消息可以像任何其他文件一样被压缩或 gzip 压缩,但专用压缩算法(如 JPEG 和 PNG 使用的压缩算法)将为适当类型的数据生成小得多的文件。
- 对于涉及大型多维浮点数数组的许多科学和工程用途,协议缓冲区消息在大小和速度方面都没有达到最大效率。对于这些应用程序, FITS和类似格式的开销较小。
- 协议缓冲区在科学计算中流行的非面向对象语言(例如 Fortran 和 IDL)中没有得到很好的支持。
- 协议缓冲区消息本身并不自我描述其数据,但它们具有完全反射的模式,您可以使用它来实现自我描述。也就是说,如果不访问其相应的.proto文件,您将无法完全解释它。
- 协议缓冲区不是任何组织的正式标准。这使得它们不适合在具有法律或其他要求以建立在标准之上的环境中使用。
八、谁使用协议缓冲区
许多外部可用的项目使用协议缓冲区,包括以下内容:
-
gRPC。
-
谷歌云。
-
特使代理。
九、协议缓冲区如何工作
下图显示了如何使用协议缓冲区来处理数据。
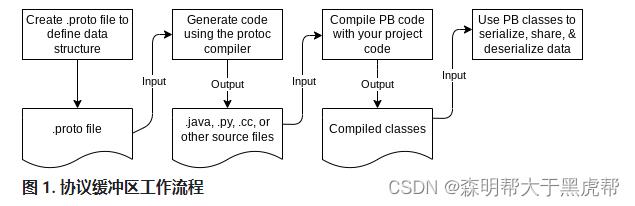
协议缓冲区生成的代码提供了从文件和流中检索数据、从数据中提取单个值、检查数据是否存在、将数据序列化回文件或流以及其他有用功能的实用方法。
以下代码示例向您展示了 Java 中此流程的示例。如前所述,这是一个.proto定义:
message Person
optional string name = 1;
optional int32 id = 2;
optional string email = 3;
编译此.proto文件会创建一个Builder类,您可以使用它来创建新实例,如以下 Java 代码所示:
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.build();
output = new FileOutputStream(args[0]);
john.writeTo(output);
然后,您可以使用 protocol buffers 在其他语言(如 C++)中创建的方法反序列化数据:
Person john;
fstream input(argv[1], ios::in | ios::binary);
john.ParseFromIstream(&input);
int id = john.id();
std::string name = john.name();
std::string email = john.email();
十、协议缓冲区定义语法
定义.proto文件时,您可以指定字段为optional or repeated(proto2 and proto3) or singular(proto3)。(将字段设置为的选项required在 proto3 中不存在,并且在 proto2 中强烈建议不要使用。有关此内容的更多信息,请参阅“指定字段规则”中的“必填项” 。)
设置字段的可选性/可重复性后,指定数据类型。协议缓冲区支持通常的原始数据类型,例如整数、布尔值和浮点数。有关完整列表,请参阅 标量值类型。
一个字段也可以是:
- 一种message类型,以便您可以嵌套部分定义,例如用于重复数据集。
- 一种enum类型,因此您可以指定一组值以供选择。
- 一种oneof类型,当消息有许多可选字段并且最多同时设置一个字段时可以使用该类型。
- 一种map类型,用于将键值对添加到您的定义中。
在 proto2 中,消息可以允许扩展定义消息本身之外的字段。例如,protobuf 库的内部消息模式允许扩展自定义的、特定于使用的选项。
有关可用选项的更多信息,请参阅 proto2或 proto3的语言指南。
在设置可选性和字段类型后,您分配一个字段编号。字段编号不能改变用途或重复使用。如果您删除一个字段,您应该保留其字段编号,以防止有人意外重复使用该编号。
十一、额外的数据类型支持
协议缓冲区支持许多标量值类型,包括使用可变长度编码和固定大小的整数。您还可以通过定义消息来创建自己的复合数据类型,这些消息本身就是可以分配给字段的数据类型。除了简单和复合值类型之外,还发布了几种常见类型。
常见类型:
- Duration 是有符号的、固定长度的时间跨度,例如 42 秒。
- Timestamp 是独立于任何时区或日历的时间点,例如 2017-01-15T01:30:15.01Z。
- Interval 是独立于时区或日历的时间间隔,例如 2017-01-15T01:30:15.01Z - 2017-01-16T02:30:15.01Z。
- Date 是一个完整的日历日期,例如 2025-09-19。
- DayOfWeek 是一周中的某一天,例如星期一。
- TimeOfDay 是一天中的某个时间,例如 10:42:23。
- LatLng 是一个纬度/经度对,例如 37.386051 纬度和 -122.083855 经度。
- Money 是具有货币类型的金额,例如 42 美元。
- PostalAddress 是邮政地址,例如 1600 Amphitheatre Parkway Mountain View, CA 94043 USA。
- Color 是 RGBA 颜色空间中的一种颜色。
- Month 是一年中的一个月,例如四月。
十二、协议缓冲区开源哲学
协议缓冲区于 2008 年开源,旨在为 Google 以外的开发人员提供与我们在内部从中获得的相同好处的一种方式。我们通过定期更新语言来支持开源社区,因为我们进行这些更改以支持我们的内部需求。虽然我们接受来自外部开发人员的精选拉取请求,但我们不能始终优先考虑不符合 Google 特定需求的功能请求和错误修复。
以上是关于协议缓冲区(Protocol Buffers)的主要内容,如果未能解决你的问题,请参考以下文章