京东618实践:一元抢宝系统的数据库架构优化
Posted z12568
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了京东618实践:一元抢宝系统的数据库架构优化相关的知识,希望对你有一定的参考价值。
最近接触到了一元抢宝系统,据了解一元抢宝系统是京东虚拟新兴的一个业务系统,上线以来订单量一直持续增长。在距离618前两个月时,京东商城商品虚拟研发部对系统做了整体预估,订单量快速增长及618大促的到来都将带来单量剧增,届时势必会对数据库容量和负载造成压力。
它的运行模式如下:假设一个商品项有100个库存,则会分100期次售卖,每期次一个售卖的是一个库存;总人次即设置的每一期抢宝商品价格,假设1000人次,则商品总价是1000元(每人1元);当剩余人次为0时,本期抢宝结束,然后按照相应算法产生抢宝者;然后进行下一期抢宝
通过技术改造,从整体上来说实现三个目标:
-
底层路由策略实现;
-
历史数据迁移;
-
业务改造。
下面详细介绍本次改造的过程
底层路由策略选择及实现
分库分表路由策略是基础,影响整个系统架构,后期业务需求是否满足和支持,使用是否方便都与此有关。路由策略设计合理,上层业务使用会很方便。一元抢宝项目的路由策略适配和实现是在DAO层实现,对上层业务层透明,可不用关心具体实现,并且路由策略不涉及结构上的改动,对上层不会产生影响。
我们知道常见的分表策略有两种:
-
hash路由
优点:可实现数据分散,热点分散;
不足:增加数据库节点时,会影响路由策略,需做数据迁移;
-
分区路由(增量区间路由)
优点:策略支持动态扩容,理论上可无限扩展;
不足:存在数据热点问题,新产生的表,读写频率较高;每次查询需要经过路由策略表。
当然每种策略都不是完美的,只有最适合业务场景的策略才是好的。该项目采用的是两种方式的结合。
首先按抢宝项hash分库,然后按抢宝期区间段分表,如下图所示:
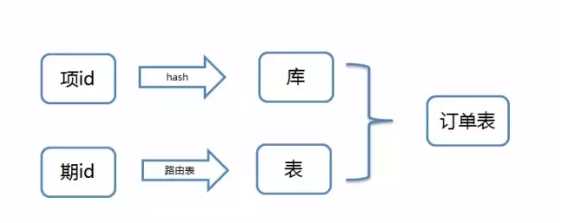
历史数据迁移
由于我们系统上线时是单库,分库是上线几个月后做的技改,所以数据需要迁移,主要迁移步骤如下:
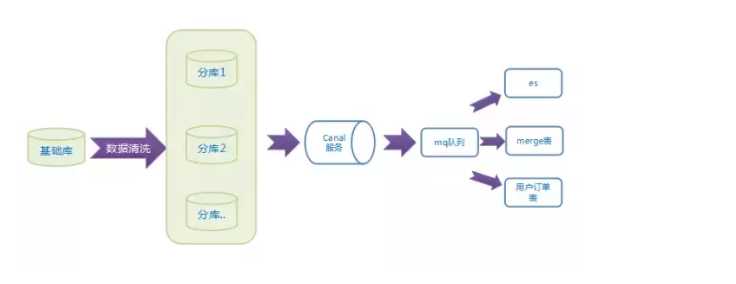
前半部分,从扫描到同步到分库是新代码,后面canal到同步ES、聚合表都是复用上面逻辑,这样设计,降低我们整体工作量,并且保证数据迁移完整。
具体迁移细节如下:
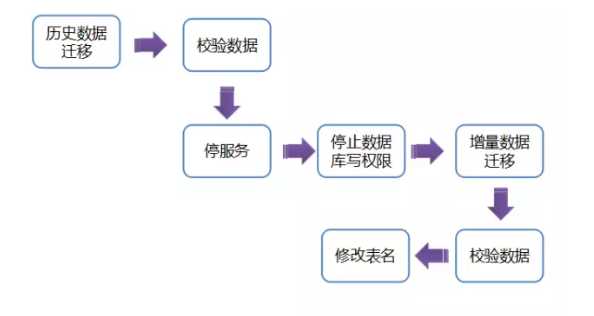
可以看出,主要分为两部分,停机前和停机后。停机前是迁移历史数据,支持重复迁移;停机后,只迁移增量部分,这样,大大缩短我们的上线时间。停机后只需要迁移很少的数据量。
迁移就涉及到数据校验,校验逻辑整体来说比较简单:
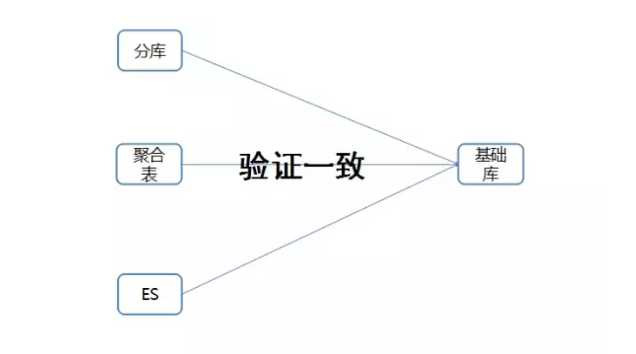
三个维度分别和基础库做对比,如果不同,重新迁移某一天数据。
关于业务改造就不用赘述
总结 :
一个系统从设计到最终完成,依赖于整个团队,每个人的想法、不同思路的碰撞和付出;再有前期合理细致的设计尤为重要,每个时间点和具体上线步骤和回滚方案做好详细计划;另外,就是细致深入测试,测试环境和线上多轮测试和回归,也是正常上线的重要保证。
以上就是京东一元抢宝项目分库分表的主要思想
以上是关于京东618实践:一元抢宝系统的数据库架构优化的主要内容,如果未能解决你的问题,请参考以下文章