彻底取代Redis+数据库架构,京东618稳了!
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了彻底取代Redis+数据库架构,京东618稳了!相关的知识,希望对你有一定的参考价值。
作者介绍
京东零售在线存储部,致力于分布式系统、开源数据库技术的研究,主要负责数据库性能调优、监控和架构设计。
过去十年,随着移动互联网指数级的增长,企业和用户对应用程序的响应性能要求越来越高, 如何在完美应对海量用户规模和海量数据的同时保证优秀的产品体验,是数据库面临的挑战。无论是机械硬盘还是SSD存储介质,企业都需要缓存技术加速数据的访问、支撑高并发和大吞吐,通过引入分布式缓存方案,提升应用程序性能,消除数据库热点。
但是,缓存技术的引入增加了业务架构的复杂度,降低了开发效率,同时还面临着缓存一致性、击穿、雪崩等挑战。因此,我们基于线上运营多年的KV存储引擎JIMDB,重新打造了JIMKV分布式数据库,融合缓存与存储的统一架构,解决了缓存难题,帮助研发人员聚焦业务逻辑,降低硬件成本,提升生产效率。
一、早期架构及功能实现
早期,我们主要使用基于Redis客户端集群方案自研的JIMDB来加速业务的访问,主要解决了自动故障检测恢复、自动弹性调度等问题。架构图如下:
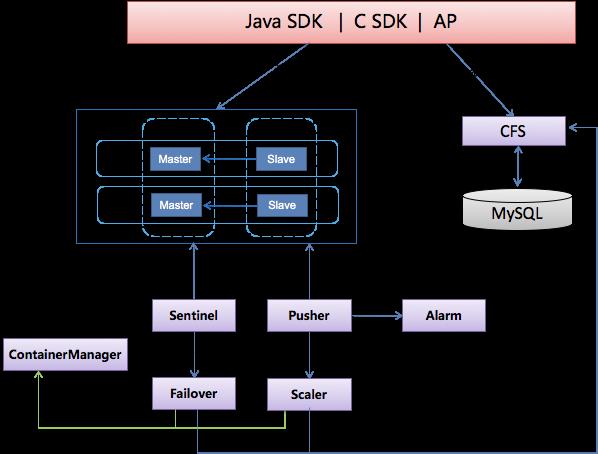
在故障检测和故障切换的方案中,比较容易想到的就是引入Zookeeper。通过Zookeeper的临时节点探测不存活的服务,但是由于服务端代码需要修改、跨机房部署不方便、watch数目和连接数过多存在性能问题等原因,这个方案最终没有被采用。
于是我们决定自己写探测程序,这个探测程序主要是检测JIMDB实例的存活状态,但是它需要尽可能地解决由于部分网络不通时导致的误判问题。采用的方案是,对探测程序部署多个,每个部署在机房的不同机架下。多个探测实例同时对同一个JIMDB实例进行探测,只要有一个探测实例检测到服务端实例是存活的,那么该实例就被认为是存活状态;当没有人反馈其为存活状态,且超过半数的探测实例认为该实例死亡时,则通知故障恢复程序进行主从切换,变更集群拓扑结构,并把新的拓扑结构通知给所有的客户端。由此,故障检测和恢复的问题基本算是解决了。
业务流量突然飙升,容量不足等问题都需要运维通过管理工具进行扩容增加实例数,另外也有一部分业务申请了集群空间。由于业务调整等原因,访问量变小了或者停用了,平台管理人员比较难发现。为了提高平台自动化的能力,减少运维人员的工作量,需要让平台动起来,所以弹性伸缩的需求摆在了开发人员的面前。
为了让平台弹性伸缩起来,需要对集群的各项指标进行监控,比如对OPS、内存使用率、网络流量等进行监控,统计这些指标一段时间内是否达到了设置的阈值,当超过扩容的阈值时自动触发扩容,当低于缩容的阈值时自动进行缩容释放资源。
缩容的过程和扩容的过程基本一致,扩容是把一个实例上的部分slot迁移到新的实例上,缩容是把一个shard实例上的所有slot迁移到另一个实例上进行合并。
扩容时由于需要增加实例,增加的实例应该部署在哪台机器上才合适呢?为了选择出最优的机器,有一个采集程序会定期进行信息收集,然后根据CPU繁忙情况、网络流量、OPS、内存剩余空间、机器上的实例数等进行综合打分,各项指标都比较空闲的得高分,如果有一项指标不符合部署要求则直接淘汰,然后再从得分高的机器中选择一台机器进行部署。
由于扩容在集群中是并发进行的,因此有可能多个处理线程会同时把实例部署到同一台物理机上,当大家部署完成后可能实例数等指标就不符合要求了。因此需要有一个预分配资源的计算,对未使用的资源进行预占并被计算在内,如果部署失败就需要把这些资源值做相应的扣除,避免并发部署出现使用资源超限的情况。对同一个集群还需要控制每台物理机上最大可部署的实例数,避免同一个物理机部署实例数过多,导致机器故障时对同一个集群影响过大。为了防止同一个机房路由器故障或者断电等情况的出现,同一个shard的主从实例应该跨机架,对有跨机房需求的应用,同一个shard的主从实例还应该部署在不同的机房。
二、大促挑战及行业发展趋势
随着近些年京东618、双11大促的火热,业务增长远超预期,资源紧缺成为一种常态。虽然JIMDB在性能方案满足了当前的业务需求,但是服务器内存成本压力与日俱增,所有业务数据全放内存太浪费,某些业务对数据持久化、一致性也提出了要求。
JIMDB在某些极端情况下容易引发全量复制进而影响请求,宕机风险越来越高,由于JIMDB架构上采用了单线程多进程架构,导致CPU成为瓶颈。同时服务器不断扩容带来运维的难度,数据量不断增加导致纯内存存储的成本加大,服务器投入边际效应显现。
另一面随着Google发布Spanner论文后,国内外像TiDB、CRDB相继推出相关数据库产品或服务来解决数据库的可扩展问题。2017年Google将Spanner商业化,也进一步验证了NewSQL作为未来数据库发展方向的正确性。
2014年,Gartner的一份报告中使用“混合事务分析处理(HTAP)”一词描述新型的应用程序架构,以打破OLTP和OLAP之间的隔阂,实现实时业务决策。这种架构具备显而易见的优势——不但避免了繁琐且昂贵的ETL操作,而且可以更快地对最新数据进行分析。这种快速分析数据的能力将成为未来企业的核心竞争力之一。
就当前的用户需求和软硬件技术发展状况来看,集成数据平台将能满足绝大数用户的场景,古人说“天下大势,分久必合、合久必分”,这句话用在数据处理领域也不为过。需求和技术是一对矛盾,当这对矛盾缓和时,数据处理领域将更趋向于整合;而当这对矛盾尖锐时,数据处理领域将趋于分散。
一方面是传统的OLTP数据库慢慢向NoSQL靠拢,一方面是像TiDB由KV向SQL靠拢,未来整合的趋势更为明显。我们详细调研了开源的TiDB与CRDB,发现并不适合我们的业务,TiDB用rust开发底层采用RocksDB磁盘存储,满足不了我们的高性能读写要求,电商大促的场景对性能延时有极致的要求;而CRDB上层SQL协议是采用PG,也不符合我们的业务,我们业务大量还是mysql生态。所以我们决定自研,彻底取代Redis+数据库架构,解决数据强一致的问题,当然我们也不是从0开始,而是参考借鉴了Spanner的论文、TiDB、RocksDB、Redis、Raft论文等。
三、架构设计及应用场景
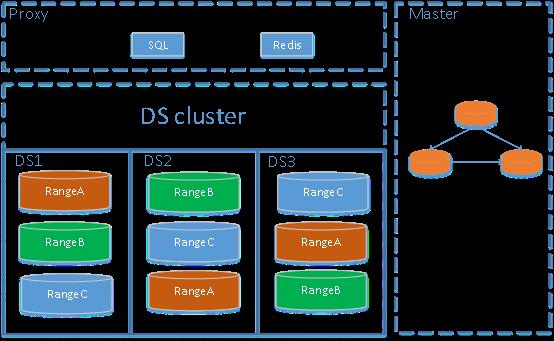
Master:
集群部署,一般线上推荐至少部署3个节点,是整个集群的管理模块,其主要工作有三个:
存储集群的元信息(某个Key存储在哪个DS节点);
对DS集群进行调度和负载均衡(如数据的迁移、Raft group leader的迁移等);
分配全局唯一且递增的事务ID。
DS cluster:
存储层DS负责存储数据,从外部看DS是一个分布式的提供事务的Key-Value存储引擎。存储数据的基本单位是Range,每个Region负责存储一个Key Range (从StartKey到EndKey的左闭右开区间)的数据,每个DS节点会负责多个。DS使用Raft协议做复制,保持数据的一致性和容灾。副本以Range为单位进行管理,不同节点上的多个Range构成一个Raft Group,互为副本。数据在多个DS之间的负载均衡由Master调度,这里也是以Range为单位进行调度。
Proxy:
JIMKV具备高吞吐、低延迟、高可用、强一致、可扩展、高可靠、多协议支持、可插拔存储引擎设计、智能分层存储、分布式事务等关键特性,因此适用于我们以下这些应用场景:
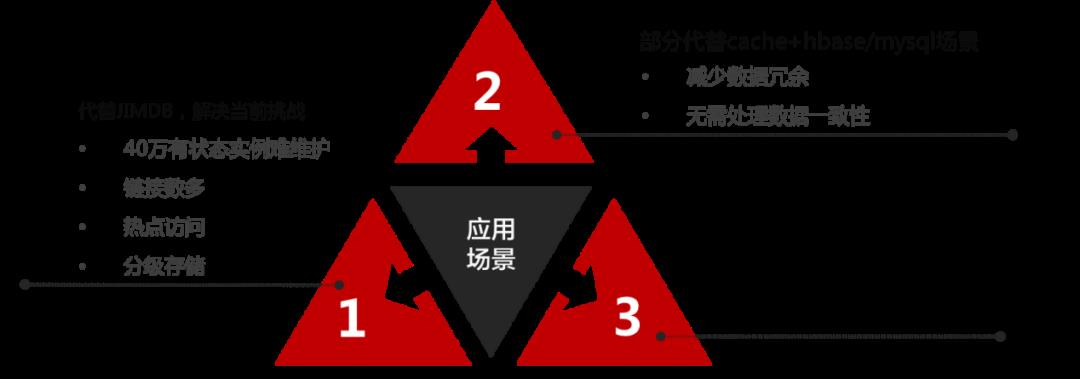
数据仓库:可以存储和处理海量数据,支持高并发的实时读写,比如订单数据库、交易数据库、存储数据库、信息采集数据库等等;
替换MySQL数据仓库:大数据量下,数据增长很快,接近单机处理大极限,不想分库分表或者使用数据库中间件等对业务侵入性较大、对业务有约束的Sharding方案,而JIMKV新一代业务层则支持MySQL协议,并提供迁移工具;
缓存加速数据仓库:JIMKV的多线程架构使得低延迟、点读性能媲美Redis,单实例支持更大的吞吐、在需要提供缓存进行系统加速的场景;
金融级OLTP业务:JIMKV具备金融级安全保证,支持金融级OLTP业务(交易、支付、账单、结算、金融等等)。
四、京东商品详情业务库应用实践
目前JIMKV作为京东下一代分布式数据库,内部许多原JIMDB客户开始陆续迁移业务到JIMKV上,在成本与性能方面取得了很好的效果。下面我们以商品详情业务库为例,介绍我们内部JIMKV实践的收益。
商品详情页在缓存数据中属于实时性要求不高的数据,但是流量特别大,单个KV比较大,促销某些爆款商品容易形成热点数据。冷热分层存储在保证性能的同时最大节省用户成本。所谓冷热数据分层存储,就是根据数据的使用频率、value大小、最后访问时间等特征将数据进行冷热分层后,再采用相应适配的物理存储介质进行存储,并通过不同存储介质之间优势互补,达到延长保存期限、降低存储成本、提高存储效率、增进安全可靠性的海量数据存储要求。
简单来说,经常被访问的数据称为热数据,而较少被访问的数据称为冷数据。其中热数据适合内存存储,实现高性能访问;而冷数据,则适合使用安全可靠性高、存储寿命长、单位存储成本低的磁盘存储介质。冷热数据之间随着访问是可以进行动态平衡的。JIMKV采用灵活的可插拔多存储引擎支持,比如磁盘我们支持RocksDB、LevelDB、WiscKeyDB等,而内存我们支持Bw-tree、masstree等,用户可根据自己的业务场景灵活配置。
众所周知,传统的KV持久化存储一般都采用基于LSM-Tree的LevelDB或RocksDB,能将离散的随机写请求都转换成批量的顺序写请求,以此提高写性能。但是传统在的LSM-Tree很难避免读写放大的问题。
读放大(Read Amplification)。LSM-Tree的读操作需要从新到旧(从上到下)一层一层查找,直到找到想要的数据。这个过程可能需要不止一次I/O。特别是range query的情况,影响很明显;
空间放大(Space Amplification)。因为所有的写入都是顺序写(append-only)的,不是in-place update,所以过期数据不会马上被清理掉。RocksDB和LevelDB通过后台的compaction来减少读放大(减少SST文件数量)和空间放大(清理过期数据),但也因此带来了写放大(Write Amplification)的问题;
写放大。实际写入磁盘的数据大小和程序要求写入数据大小之比。正常情况下,HDD/SSD观察到的写入数据多于上层程序写入的数据。原因是在compact的过程中,我需要额外的进行写操作以便能够将数据从一个level写入到另一个level,所以这个过程就增加了写入量。
现在SSD逐渐成为主流存储,但compacion带来的写放大问题显得越来越严重:
SSD顺序读写性能比随机读写性能好一些,但是差距并没有HDD那么大。所以,顺序写相比随机写带来的好处,能不能抵消写放大带来的开销,这是个问题;
SSD的使用寿命和其写入量有关,写放大太严重会大大缩短SSD的使用寿命。因为SSD不支持覆盖写,必须先擦除(erase)再写入。而每个SSD block(block是SSD擦除操作的基本单位)的平均擦除次数是有限的。
写放大在两个level之间能够达到10以上。又因为这里有7个level,所以从level 1~level 6,可能会使写放大达到50。
WiscKeyDB通过以下四点解决读写放大的问题:
键值分开存储,Key仍然存在LSM-tree中,Value存在额外的日志文件(vLog)中;
对于无序的值数据,利用SSD并行随机读以加速读取速度;
使用独特的崩溃一致性和垃圾回收策略以高效的管理Value日志文件;
去除WAL并且不影响一致性,提升小数据流量的写入性能。
配置参数maxmemory,maxdisksize
Maxmemory > 0默认开启masstree引擎(内存数据库)。
maxmemory = 0默认开启RocksDB引擎(磁盘数据库)。
1)热→冷:使用内存>maxmemory
根据客户端命令(比如set sk svalue),来计算是否需要增加字节,判断内存使用量如果>maxmemory,就启动RocksDB引擎,按照配置的策略进行尾淘汰,淘汰任务加入异步IO任务队列,不影响主线程其他命令的执行,IO线程取出异步任务,将key value存储到RocksDB,通知主线程。主线程收到完成的通知后释放masstree中value的内存,在元数据中标记此value在冷存储中。
2)冷→热:使用内存<maxmemory*70%
用户访问的key如果在RocksDB,且当前value大小+使用内存<maxmemory开始进行首淘汰,访问的key的value不在内存中,但是客户端命令类型(比如exist,ttl之类的)不需要查询原有value,正常执行;访问的key的value在冷,就加入异步IO任务,不阻塞主线程其他命令执行。IO线程取出异步任务,从RocksDB中查询对应的value,通知主线程,将value返回给客户端,将value插入masstree中,更新key中元数据中的冷热标志,删除RocksDB里的冷key。
我们根据详情页的数据特点磁盘采用WiscKeyDB存储引擎,内存采用masstree存储引擎,masstree结合了trie与b+tree的特点,节省内存性能上由于RCU细粒度的锁机制比b+tree性能好很多,而WiscKeyDB是在RocksDB基础上大大减少了读写放大。针对热点数据我们sdk也是支持客户端缓存进行优化,采用新的混合存储以后我们在满足客户性能要求的同时,降低了75%左右的存储成本。
五、后续规划
目前我们通过高可用架构的master来调度、balance、迁移、故障恢复等,能否结合机器学习让数据库能否拥有真正的智能,能够自我维护、自我修复以及自我性能调优等在未来是一个好的思路。
目前我们针对MySQL兼容程度还不是很够,只能满足普通的增删改查以及ddl操作,针对聚合、join等分析功能还未完全实现,这是我们下一步的工作重点。
随着硬件性能的提升,内核中的网络栈和存储栈带来的性能瓶颈越来越明显,为缩短IO路径、解决NVMe SSD在传统IO栈上的性能问题,Linux内核从4.x开始引入了新的NVMe IO栈,新的IO子系统完全摈弃了传统的通用块层和SCSI子系统,而kernel bypass(绕过内核)是解决系统网络栈和存储栈性能瓶颈的另外一种方式,并辅以各种性能调优手段(CPU pin、无锁队列),从而达到更高的性能。
目前市场上也有多种类似的技术,如DPDK、NETMAP、SPDK、PF_RING、RDMA等,如何利用新的硬件(Nvme SSD、Persistent Memory、Kernel bypass GPU、FPGA)结合JIMKV来提高稳定性与性能也是我们未来的规划。
《All in Cloud时代,下一代云原生数据库技术与趋势(拟)》阿里巴巴 集团副总裁 李飞飞(飞刀)
《从自研演进看分布式数据库》中国银联 云计算中心团队主管 周家晶
《开源数据库MySQL在民生银行的应用实践》民生银行 项目经理 徐春阳
《TDSQL在金融行业数据库上云实战》腾讯云 高级经理 陈琢
以上是关于彻底取代Redis+数据库架构,京东618稳了!的主要内容,如果未能解决你的问题,请参考以下文章