SAS 对数据的拼接与串接
Posted suolilian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SAS 对数据的拼接与串接相关的知识,希望对你有一定的参考价值。
SAS 对数据的拼接与串接
使用SAS对数据进行串接、合并、更新与修改。
1. 数据集的纵向串接
数据集的纵向串接指的是,将两个或者多个数据集首尾相连,形成 一个新的数据集。
对数据集的纵向串接可以通过以下两种方法实现:
- ·使用SAS DATA步的SET语句。
- ·使用SAS过程步的APPEND过程。
1.1 使用SET语句实现纵向串接
1.基本形式
使用SET语句实现纵向串接的基本形式如下:
DATA 新数据集; SET 数据集1 数据集2 <数据集3 数据集4 …>; RUN;
其中:
- ·SET语句中的数据集1、数据集2都为输入数据集。
- ·串接后的数据存储在DATA语句的新数据集中。
- ·SET语句可以同时读入多个数据集,新数据集将包含各输入数据集 中的所有变量。
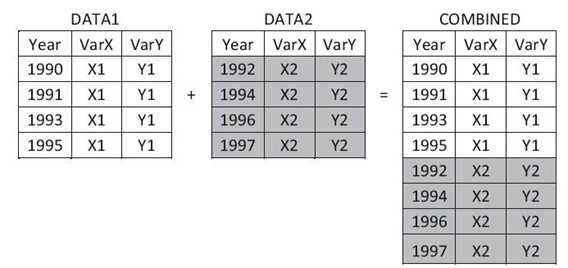
对数据集Work.New_Emloyee和Work.Old_Emplyee进行串 接。
以下代码创建了数据集:
data work.New_Employee;
input Emp_ID $ Emp_Name $ @@;
datalines;
ET001 Jimmy ED003 Emy EC002 Alfred EQ004 Kim
;
run;
data work.Old_Employee;
input Emp_ID $ Emp_Name $ @@;
datalines;
EQ122 Molly ET121 Dillon ET123 Helen ED124 John
;
run
数据集Work.New_Emloyee和Work.Old_Emplyee含有相同的变量Emp_ID和Emp_Name。串接两个数据集的示例代码如下:
data work.Employee; set work.Old_Employee work.New_employee ; run; proc print data=work.Old_Employee; title ‘Old Employee‘; run; proc print data=work.New_Employee; title ‘New Employee‘; run; proc print data=work.Employee; title ‘All Employee‘; run;
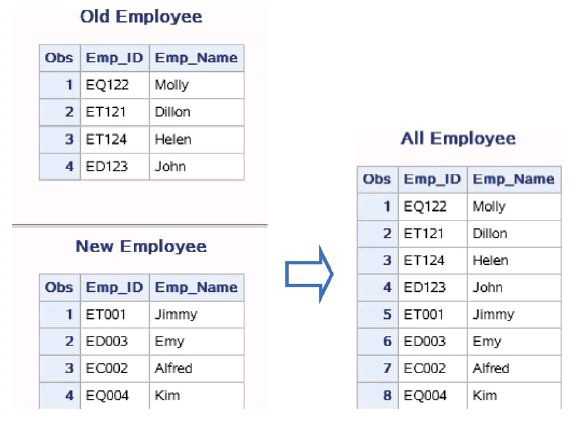
从输出内容中可以观察到新数据集work.Employee包含了2个变量和8条观测,work.Old_Employee的观测直接加在了work.New_Employee的 后面,名称相同的字段放在同一变量下。
如果Work.New_Employee和Work.Old_Emplyee中含有的变量不全一 致,将这两个数据集进行串接时,情况会是如何呢?
以下代码在 Work.New_Emloyee和Work.Old_Emplyee中分别用IF语句创建了新变量 Dept和Gender。
data work.New_Employee_Dept; set work.New_Employee; if substr(Emp_ID,2,1)="T" then Dept="TSG"; else if substr(Emp_ID,2,1)="Q" then Dept="QSG"; else if substr(Emp_ID,2,1)="D" then Dept="DSG"; else if substr(Emp_ID,2,1)="C" then Dept="CSG"; run; data work.Old_Employee_Gen; set work.Old_Employee; if mod(substr(Emp_ID,length((trim(Emp_ID))),1),2)=0 then Gender="F"; else Gender="M"; run;
对数据集Work.New_Emloyee_Dept和Work.Old_Emplyee_Gen进行串接。 示例代码如下:
data work.Employee_Update; set work.Old_Employee_Gen work.New_employee_Dept; run; proc print data=work.Employee_Update; title ‘All Employee Update‘; run;
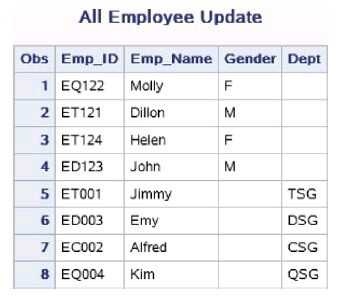
新数据集work.Employee_Update和work.Employee一样含有8条观 测,但是work.Employee_Update含有4个变量,依次为Emp_ID、 Emp_Name、Gender和Dept。由于work.Old_Employee_Gen中不含有 Dept,因此串接后前4条观测的Dept都为缺失值,同样Gender在 work.New_Employee_Dept中不存在,串接后的后4条观测其Gender都为 缺失值。
1.2 使用BY语句进行穿插串接
在例4.2中,如果要让串接后的新数据集中的8条观测按照Emp_ID的 升序排列,该如何操作呢?这时需要引入穿插串接的概念。穿插串接就是使得新数据集的观测按照一定顺序排列的串接方法。
基本形式如下:
DATA 新数据集; SET 数据集1 数据集2 <数据集3 数据集4 … >; BY 变量1 <变量2 变量3 变量4 … >; RUN;
BY语句在处理多个数据集时经常使用,为了更好地理解本章后面 的内容,这里需要引入BY变量、BY变量组、BY变量值和BY组合的概 念。
- ·BY语句中的变量称为BY变量,一个BY语句中可以有多个BY变量。
- ·当BY语句中有多个变量时,称这些变量为BY变量组。
- ·BY变量值指的是BY变量的取值。
- ·BY组合指的是具有相同BY变量值的观测的集合。当有多个BY变量时,BY组合就是使得所有BY变量的取值完全相同的观测的集合。
为了便于理解,在本章后面的阐述中,BY变量既代表一个BY变 量,也可以是多个BY变量。
在使用BY语句时,所有输入数据集都必须是按BY变量排过序,或 者有基于BY变量建立的索引(在以后的所有代码中,使用BY语句都有 这样的要求)。串接完毕后,新数据集中的观测也将按照BY变量排 序。
对数据集Work.New_Emloyee_Dept和Work.Old_Emplyee_Gen进行穿插串接。
由于work.New_Employee_Dept和work.Old_Employee_Gen都没有按 照Emp_ID排序,在对这两个数据集进行穿插串接时,首先必须对其按 Emp_ID排序。
proc sort data=work.New_Employee_Dept; by Emp_ID; run; proc sort data=work.Old_Employee_Gen; by Emp_ID; run; data work.Employee_Int; set work.Old_Employee_Gen work.New_Employee_Dept; by Emp_ID; run; proc print data=work.Employee_Int; title ‘All Employee Interleaving by ID‘; run;
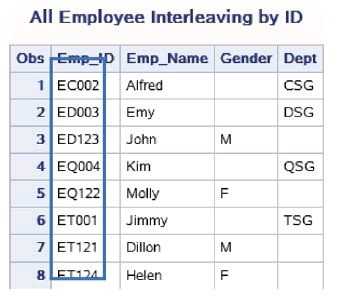
1.3.使用LENGTH语句
当输入数据集中同名变量的长度不一样时,新数据集中该变量的长度等于SET语句中第一个数据集中对应变量的长度。在对多个数据集进 行串接时,最好先检查字符型变量的长度,避免在读取变量值时造成截 断。如有需要,可以在使用SET语句之前使用LENGTH语句来定义变量 的长度。
使用LENGTH语句定义变量长度的基本形式如下:
LENGTH 变量1 < $ >长度 <变量2 < $ >长度 …>;
在定义字符型变量的长度时,需在长度前面加上$符号。
使用LENGTH语句将数据集work.Employee中Emp_ID的长度定义为15。 示例代码如下:
data work.Employee; length Emp_ID $15; set work.New_Employee work.Old_employee; by Emp_ID; run;
1.4 使用选项RENAME=
在上面的例子中,输入数据集中相同含义的字段正好同名,但是在很多情况下,由于数据来自于不同的部门系统和时期,输入数据集中相 同含义的变量往往不具有相同的变量名。例如,在一个数据集中表示员 工ID的变量名叫ID,在另一个数据集中表示员工ID的变量名叫 Emp_ID,在进行数据拼接的时候,如果不做另外的处理,这两个变量 将会被SAS认为是两个不同的字段,并分别存储在两个不同的变量下。 这时可以使用RENAME=选项将两个数据集中的变量名改成一致的名 称,避免出现前面描述的问题。
使用RENAME=选项的基本形式如下:
数据集(RENAME= (原变量名1 = 新变量名1 <原变量名2 = 新变量名2 … >));
2 使用APPEND过程实现纵向串接
使用APPEND过程进行数据集串接的基本形式如下:
PROC APPEND BASE=主数据集 <DATA=追加数据集> <FORCE>;
其中:
- ·主数据集表示需要增加观测的数据集。该主数据集可以是已经存 在的数据集,也可以是不存在的数据集。当主数据集不存在时,在执行完APPEND过程后,将生成主数据集,并将追加数据集的观测复制到主数据集中。
- ·追加数据集中包含了需要被添加到主数据集中的观测。这个语句可以是默认的,此时,SAS会将当前数据集的观测添加到主数据集的后 面。当前数据集指的是SAS系统最近一次生成的数据集。通常情况下, 为了保证程序的可读性,不建议默认。
- ·FORCE选项会强制将追加数据集中的观测添加到主数据集中。后面将会介绍需要使用FORCE选项的3种情况及其结果。
使用APPEND过程进行串接时,SAS不会处理主数据集中的观测, 而是直接将追加数据集的观测添加到主数据集最后一条观测的后面,且 变量仅包含主数据集中的变量。
运用APPEND过程将work.New_Employee_Dept和 work.Old_employee_Gen两个数据集进行纵向串接,并将串接后的数据 集保存在work.Old_employee_Gen中(前面在介绍SET语句的时候,已经 介绍并操作过这两个数据集)。
两个数据集的基本情况如图所示。 两个数据集所含的变量不全一致,需要使用FORCE语句来进行串接,代码如下:
proc append base=work.Old_Employee_Gen data=work.New_Employee_Dept FORCE; run;
串接后的数据集work.Old_Employee_Gen如图所示。
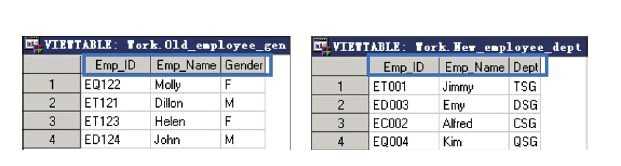
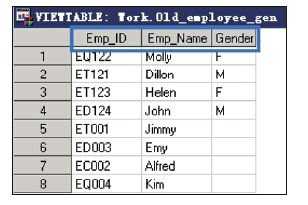
从上面的例子可以观察到,串接后work.Old_Employee_Gen中仅包含原来含有的变量,观测数为两个数据集中的观测之和。这里使用了 FORCE选项,如果去掉FORCE选项,串接将失败,这是因为追加数据 集work.New_employee_dept中含有主数据集没有的变量。
使用APPEND过程时特别需要注意FORCE选项的使用,下面介绍需要使用FORCE选项的3种情况,以及使用FORCE选项后的结果。
·第一种情况,如果追加的数据集中存在不包含在主数据集中的变量,使用FORCE选项将会使得串接成功,但仅存在于追加数据集中的变量不会被添加到主数据集中。
·第二种情况,如果同名变量在主数据集和追加数据集中的类型不一样,那么需要使用FORCE选项,但是追加进主数据集的观测对应的这个变量的值为缺失。
·第三种情况,如果同名变量在追加数据集中的长度大于主数据集中的长度,那么需要使用FORCE选项,在执行过程中,追加数据集中的变量值可能会被截断。
当主数据集中包含追加数据集中不含有的变量时,串接成功,同时 系统会在日志中生成警告,并且追加数据集中不含有的变量之值都为缺 失。另外,当两个数据集中同名变量的属性不一致时,将沿用主数据集 中变量的属性。
在企业交易系统数据的维护过程中可以使用APPEND过程,例如主 数据集可以表示历年的交易记录,追加数据集可以表示每年新增的交易 记录,使用APPEND过程可以将每年新增的销售记录方便快速地串接到 历年的销售记录中。
注意 在使用APPEND过程时,一定要注意观察日志信息,避免产生数据缺失、截断等异常结果。
1. SET语句与APPEND过程的比较
对两个数据集进行纵向串接时,如果两个数据集中的变量名称和属性都相同,使用SET语句和APPEND过程,可以得到完全一样的结果。 但是使用APPEND过程的效率比使用SET语句高,尤其是当主数据集的观测量很大时,这是因为APPEND过程不对主数据集的观测进行操作, 而是直接把追加数据集的观测加到主数据集的后面。
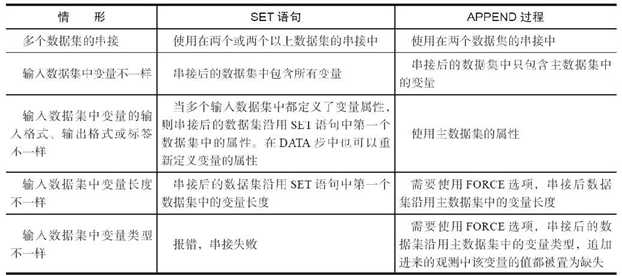
当输入数据集的个数、所包含的变量或者变量属性不一致时,两种 方法有较大差别,如表4.1所示。
2表4.1 SET语句和APPEND过程比较
2 数据集的横向合并
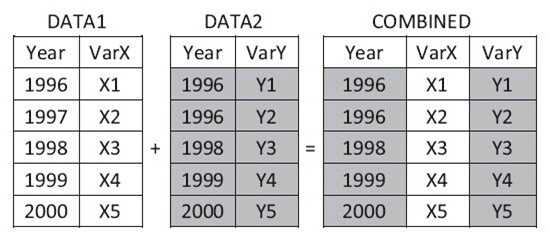
数据集的横向合并,指的是将两个或多个数据集根据某种原则横向 合并起来,形成新的数据集。SAS提供了MERGE语句来实现两个或多 个数据集的横向合并。数据的横向合并主要分为以下两种情况:
- ·不使用BY语句合并,也称为一对一合并(左图)。
- ·使用BY语句合并,也称为匹配合并(右图)。
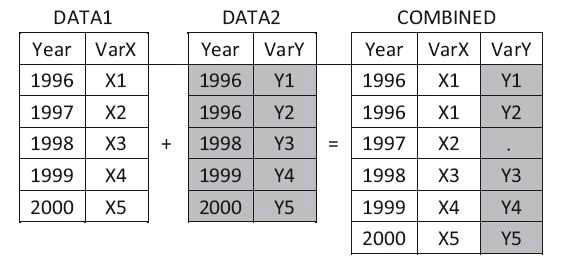
1. 不适用by语句实例代码
代码如下:
DATA WORK.COMBINED;
MERGE WORK.DATA1 WORK.DATA2;
RUN;
2. 使用by语句实例代码
DATA WORK.COMBINED;
MERGE WORK.DATA1 WORK.DATA2;
BY Year;
RUN;
2.1 不使用BY语句实现横向合并
不使用BY语句进行数据集横向合并的基本形式如下:
DATA 新数据集; MERGE 数据集1 数据集2 <数据集3 数据集4 … >; RUN;
不使用BY语句进行数据集横向合并时,对输入数据集的排序没有要求。
某部门的主管决定在年终的时候对本部门的员工进行考 核,数据集work.staff中包含了员工的基本信息,而另一个数据集 work.schedule中包含了考核时间和地点。现在需要给每位员工分配考核 时间和地点。
以下代码创建了数据集。
data work.staff; infile datalines dsd; length emp_name $20 title $15; input emp_name $ title $ ; datalines; Jacob Adams,Analyst Emily Anderson,Analyst Michael Arnold,Senior Analyst Hannah Baker,Manager Joshua Carter,Senior Analyst ; run; data work.time; input time date9. room $11-24; format time date9.; datalines; 01Dec2013 Meeting Room 1 02Dec2013 Meeting Room 2 03Dec2013 Meeting Room 1 03Dec2013 Meeting Room 2 04Dec2013 Meeting Room 3 04Dec2013 Meeting Room 1 ; run;
其中,Emp_name表示员工姓名,title表示员工的职位,time表示考核时间,room表示和时间对应的会议室。现在将时间和会议室分配给各 员工,示例代码如下:
data work.schedule; merge staff time; run; proc print data= work.schedule; title "Schedule for Performance Management"; run;
2.2 使用BY语句实现横向合并
使用BY语句进行数据集横向合并的基本形式如下:
DATA 新数据集; MERGE 数据集1 数据集2 <数据集3 数据集4 … >; BY 变量名1 <变量名2 变量名3 … >; RUN;
和之前介绍SET语句时提及的一样,当使用BY语句时,输入数据集必须按BY变量排序。
SAS在处理匹配合并的DATA步程序时,主要分以下两个阶段:
- ·编译阶段,SAS在辨识出MERGE语句后,将按照其中数据集的排列顺序,依次读入所有数据集中变量的描述部分,包括DATA步中新创建变量的描述部分,并将所有变量置于PDV中。若不同的数据集中有同名的变量,则要求它们的数据类型必须相同,长度以第一次出现的变量为准。
- ·执行阶段,各输入数据集中的观测按BY变量进行匹配,在DATA 步的每次循环中依次读入BY组合的每条观测。如果遇到同名的变量,后读入的变量值将覆盖先读入的变量值。由数据集中读入的变量值,会自动地保留到BY变量值在所有输入数据集中都改变为止。由DATA步新 创建的变量,其变量值在每次循环中都不能在PDV中自动保留,也就是说,在处理下一条数据之前它将被置为缺失值。
1.BY变量值在所有数据集中唯一
BY变量值在所有数据集中都是唯一的,即在任一输入数据集中, 没有两条或两条以上的观测具有相同的BY变量值,这是最简单的一种 情景。
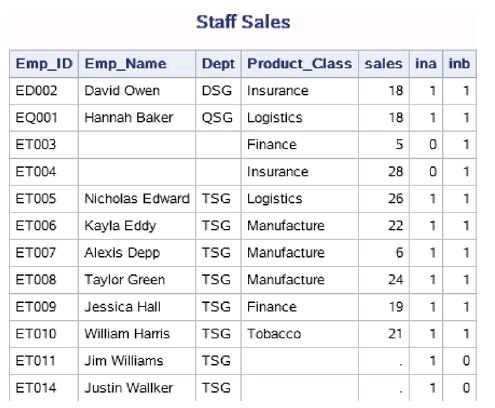
据集ex.staff_personel中包含了员工的基本信息,如Emp_ID、姓名、部门,另一个数据集ex.sales_current_month包含了员工本月的业绩信息,如Emp_ID、产品种类和销售额,但是不含有员工姓名。现在欲制作一张报表展现员工本月业绩,并在报表中包含员工姓名 和部门数据。
首先得对ex.staff_personel和ex.sales_current_month按照Emp_ID进行排序,代码如下:
proc sort data=ex.staff_personel out=work.staff_personel; by Emp_ID; run; proc sort data=ex.sales_current_month out=work.sales_current_month; by Emp_ID; run;
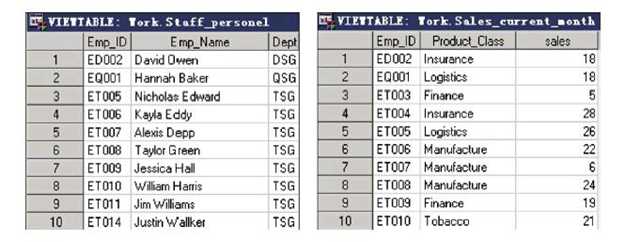
以下代码实现了合并操作:
data work.Staff_sales; merge work.staff_personel work.sales_current_month; by Emp_ID; run; proc print data=work.Staff_sales noobs; title‘Staff Sales‘; run;
2.BY变量值在某一数据集中存在重复
BY变量值在某一输入数据集中存在重复值,即在其中一个输入数据集中,含有两条或两条以上的观测具有相同的BY变量值,也称为一对多合并。在匹配过程中会遵循如下原则:由输入数据集读入的变量 值,会保留在PDV中,直到被下一个读入的观测值覆盖或该BY组合处 理完毕被重置为缺失值为止。接下来通过一个简单的例子来具体讲解这一原则。
数据集ex.sales_three_month中包含了最近3个月 的绩效信息,每个员工每个月都有一条记录,现在欲制作一个报告显示 员工最近3个月的绩效信息,并显示员工的姓名和部门。
这里Emp_ID变量值在输入数据集中不再是唯一的。以下代码可以 实现员工信息和最近3个月绩效信息的匹配:
proc sort data=ex.staff_personel out=work.staff_personel; by Emp_id; run; proc sort data=ex.sales_three_month out=work.sales_three_month; by Emp_id; run; data work.staff_report; merge work.staff_personel work.sales_three_month; by Emp_id; run; proc print data=work.staff_personel noobs; title "Staff Information"; run; proc print data=work.sales_three_month noobs; title "Sales For Three Months"; run; proc print data=work.staff_report noobs; title "Staff Report"; run;
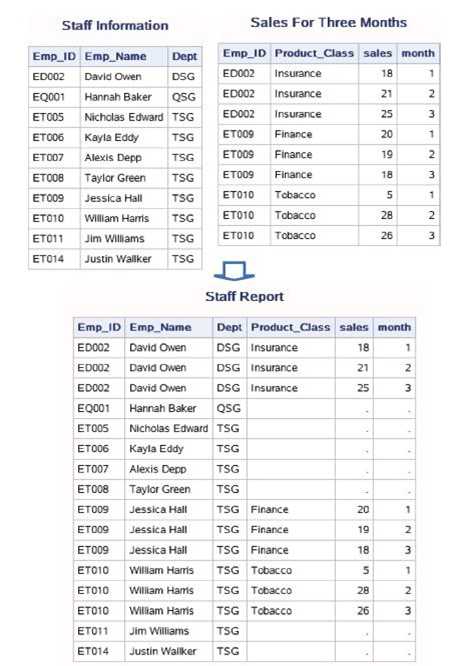
3.BY变量值在多个数据集中存在重复
虽然在匹配合并时,一般情况下BY变量值至多在某一个数据集中有重复,但并不代表匹配合并只能处理这一种情况,它同样可以处理两个或两个以上输入数据集中的BY变量值重复的情况,也就是实现多对多合并。SAS的匹配原则和一对多合并时一样,并且新数据集中每一个 BY变量值重复的次数和输入数据集中重复次数最多的一样。
运用MERGE语句进行多对多合并在实际应用中并不常见,但是理 解了SAS的匹配原则在实际应用中有助于开发人员进行程序调试和质量 控制。这里用一个简单的例子帮助读者理解。
data work.schedule; merge work.staff work.time; run; proc print data=work.schedule; run; data work.test1; input x y; datalines; 1 2 1 3 2 2 2 4 ; run; data work.test2; input x z; datalines; 1 4 1 9 2 3 2 9 3 4 ; run; proc sort data= work.test1 out=work.merge1; by x; run; proc sort data=work.test2 out=work.merge2; by x; run; proc print data=work.merge1; run; proc print data=work.merge2; run; data work.merge_all; merge work.merge1 work.merge2; by x; run; proc print data=work.merge_all; run;
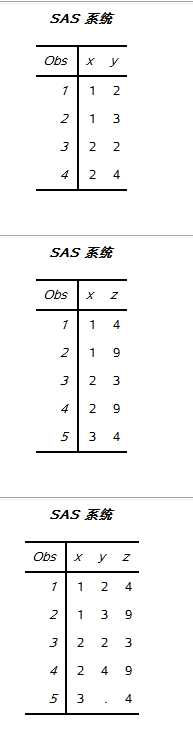
3 使用数据集选项IN=操作观测
在上例中,work.staff_personel数据集中有一部分员工没有业绩信息,如果不想将这些员工的信息包含在新生成的数据集中,就需要确定数据集work.staff_personel与work.sales_current_month是否分别输出了它 们的观测值到输出数据集中。使用数据集选项IN=可以帮助实现这一功能。
数据集选项IN=的基本形式如下:
数据集(IN= 变量)
数据集选项IN=可以运用在SET、MERGE、MODIFY、UPDATE语 句中的任何数据集后面。变量是数值型临时变量,不同的数据集应定义 不同的临时变量名称,临时变量可以在DATA步中使用,但是不会在数 据集中输出。在某一数据集后面使用(IN=变量)时,如果PDV中对应 的变量值是来自于这一数据集的观测,临时变量将被赋值为1,否则临 时变量的值为0。特别是,当和BY语句一起使用时,可以通过判断PDV 中BY变量的值是否来自于这一数据集来确定临时变量的值。
以下程序对例4.8的数据集进行匹配合并时使用了数据集选项IN=。
由于选项IN=指定的只是临时变量,为了在输出数据集中能看到变量的
值,因此在程序中又将这些临时变量的值赋给了新变量INA和INB。从 输出结果可以看出,在合并以后的数据集中,来自work.staff_personel的 观测的INA为1,来自sales_current_month的观测的INB为1。
data work.Staff_sales; merge work.staff_personel (IN=a) work.sales_current_month (IN=b); by Emp_ID; ina=a; inb=b; run; proc print data=work.Staff_sales noobs; title ‘Staff Sales‘; run;
如果只想将既存在于work.staff_personel又存在于 work.sales_current_month中的员工记录写入新数据集中,可以通过IF语 句实现。
data Staff_sales; merge staff_personel (IN=a) sales_current_month (IN=b); by Emp_ID; if a and b; run;
其中“if a and b;”是“if a and b then output;”的一种省略形式。
4. 数据集的更新
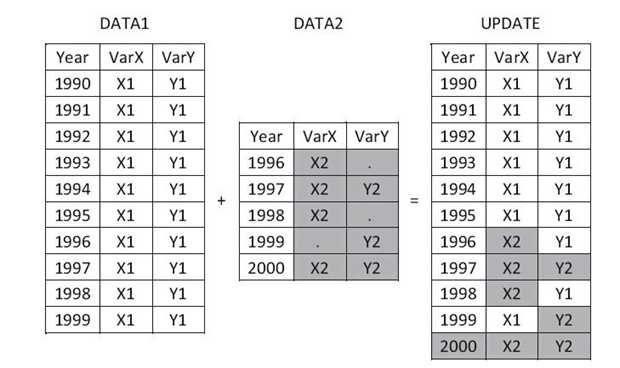
数据集的更新,指的是用一个数据集中的数据来替换另一个数据集 中的数据。SAS提供了UPDATE语句来实现数据集的更新
UPDATE语句如下:
DATA WORK.DATA1;
UPDATE WORK.DATA1 WORK.DATA2;
BY Year;
RUN;
在运用UPDATE语句进行数据集更新时,通常称DATA1为主数据集,DATA2为更新数据集。在上述示例中,主数据集和更新数据集通 过BY变量Year联系起来,更新数据集中的非缺失的变量值替换了主数 据集中的变量值。对于更新数据集中存在缺失值的情况,在UPDATE语 句中可以运用选项UPDATEMODE=来控制是否用缺失值替换主数据集 中的变量值,系统默认UPDATEMODE=MISSINGCHECK,也就是不替 换;如果设置UPDATEMODE=NOMISSINGCHECK,则不管更新数据 集中的变量值是否是缺失值,都将替换。
使用UPDATE语句进行数据集更新的基本形式如下:
DATA 新数据集; UPDATE 主数据集 更新数据集 <UPDATEMODE = MISSINGCHECK|NOMISSINGCHECK>; BY 变量1 <变量2 变量3 …>; RUN;
更新后数据集的名称可以是新的数据集名称,不需要和主数据集同 名。新数据集中包含主数据集和更新数据集中的所有变量。
主数据集和更新数据集都必须按照BY变量排序。通常要求BY变量值在主数据集中必须是唯一的,且不需要进行更新,例如BY变量可以 是员工号或交易号。运用UPDATE语句时,如果SAS发现主数据集中BY 变量值有重复,SAS会在日志中输出警告,此时虽然可更新成功,但是所有的更新只会作用在主数据集中BY组合的第一条观测上。
某公司的市场部门将所有的客户信息都存储在数据集
work.Customer中,但是每年都需要对这些客户信息进行及时更新,更新信息存储在数据集work.UpdateInfo中。
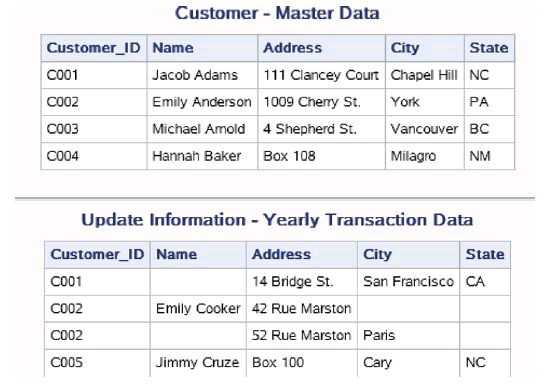
以下代码创建了数据集work.Customer和work.UpdateInfo。 work.Customer和work.UpdateInfo中包含了客户编号、姓名、地址、联系 方式等数据。
data work.Customer; input Customer_ID $1-4 Name $ 6-19 Address $ 21-37 City $ 39-51 State $ 53-54; datalines; C001 Jacob Adams 111 Clancey Court Chapel Hill NC C002 Emily Anderson 1009 Cherry St. York PA C003 Michael Arnold 4 Shepherd St. Vancouver BC C004 Hannah Baker Box 108 Milagro NM ; run; proc print data=work.Customer noobs; title "Customer - Master Data"; run; data work.UpdateInfo; infile datalines missover; input Customer_ID $1-4 Name $ 6-19 Address $ 21-37 City $ 39-51 State $ 53-54 ; datalines; C001 14 Bridge St. San Francisco CA C002 Emily Cooker 42 Rue Marston C002 52 Rue Marston Paris C005 Jimmy Cruze Box 100 Cary NC ; run; proc print data=work.UpdateInfo noobs; title "Update Information - Yearly Transaction Data"; run;
Customer_ID是客户的注册号,对于客户来说,这个注册号是唯一的。由于work.Customer和work.UpdateInfo都已经按照 Customer_ID排过序,因此在更新前不需要重新排序。接下来用 UPDATE语句对数据集work.Customer进行更新。示例代码如下:
data work.Customer_update; update work.Customer work.UpdateInfo; by Customer_ID; run; proc print data=work.Customer noobs; title "Customer- Master Data Update"; run;
在上例中,主数据集中的BY变量是唯一的,更新数据集中的BY变 量值存在重复值,我们可以有如下发现:
- ·当更新数据集中BY变量值存在重复值时,BY组合中的后一条观测 会覆盖前一条观测。例如Customer_ID为C002的更新信息分别记录在 work.UpdateInfo的两条观测中,更新后的数据集中Customer_ID为C002 的观测是唯一的,并且Address为work.UpdateInfo中后一条观测的值。
- ·当更新数据集中的某一条观测在主数据集没有对应的观测时,SAS 会直接将这条观测作为更新的基础,然后结合更新数据集中剩余的观测 继续处理该观测。如上例中Customer_ID为C005的观测在主数据集中不 存在,SAS将其作为了更新的基础,由于更新数据集中不含有其他 Customer_ID为C005的观测,所以该条观测被直接加入新数据集中。
UPDATE语句和MERGE语句都可以对两个数据集进行匹配合并,但是存在比较大的区别,如下:
- ·UPDATE语句只能操作两个数据集;MERGE语句可以对两个或两 个以上数据集进行操作。
- ·使用UPDATE语句时必须使用BY语句;MERGE语句在不使用BY语句的时候也可以按观测号进行一对一合并。
- ·在处理缺失值时,UPDATE语句可以控制是否用缺失值对主数据 集进行替换;MERGE语句中后一数据集中的缺失值一定会覆盖前一数 据集中的值。
- ·当BY变量值在后一数据集或者更新数据集中不唯一时,UPDATE 语句和MERGE语句的处理方式不一样,详见上一章节中MERGE语句的 多种情形和本节前面部分的介绍。
data work.Customer; input Customer_ID $1-4 Name $ 6-19 Address $ 21-37 City $ 39-51 State $ 53-54; datalines; C001 Jacob Adams 111 Clancey Court Chapel Hill NC C002 Emily Anderson 1009 Cherry St. York PA C003 Michael Arnold 4 Shepherd St. Vancouver BC C004 Hannah Baker Box 108 Milagro NM ; run; proc print data=work.Customer noobs; title "Customer - Master Data"; run; data work.UpdateInfo; infile datalines missover; input Customer_ID $1-4 Name $6-19 Address $21-37 City $39-51 State $53-54 ; datalines; C001 14 Bridge St. San Francisco CA C002 Emily Cooker 42 Rue Marston C002 52 Rue Marston Paris C005 Jimmy Cruze Box 100 Cary NC ; run; proc print data=work.UpdateInfo noobs; title "Update Information-Yearly Transaction Data"; run; data work.Customer_update; update work.Customer work.UpdateInfo; by Customer_ID; run; proc print data=work.Customer noobs; title "Customer- Master Data Update"; run;
5. 数据集的更改
SAS提供了MODIFY语句进一步扩充了DATA步的功能,它可以在 原数据集上直接进行替代、删除或添加观测的操作。
5.1 单个数据集的更改
运用MODIFY语句进行单个数据集更改的基本形式如下:
DATA 原数据集;
MODIFY 原数据集;
RUN;
运用MODIFY语句,可以更改原数据集中任何变量的值,但是由于 该语句不能够更改原数据集的描述部分,因此不能在原数据集中添加或 者删除变量。以下通过一个销售管理系统的例子来讲解MODIFY语句的 运用。
数据集work.inventory中包含产品、库存和价格的信息,以下代码创 建了数据集work.inventory。
data work.inventory; input Product_ID $ Instock Price; datalines; P001R 12 125.00 P003T 34 40.00 P301M 23 500.00 PC02M 12 100.00; proc print data=work.inventory noobs; title "Warehouse Inventory"; run;
数据集work.inventory内容如图4.19所示。 例4.11:由于物价上涨导致成本上升,公司决定将每种产品的销售价格提高15%。 示例代码如下:
data work.inventory; modify work.Inventory; price=price*1.15; run; proc print data=work.inventory noobs; title ‘Price reflects 15% increase‘; run;
4.4.2 两个数据集的更改
使用MODIFY语句可以实现通过一个数据集对另一个数据集中的数 据进行更改,基本形式如下:
DATA 主数据集; MODIFY 主数据集 修改数据集; BY 变量1 <变量2 变量3 …>; RUN;
其中,主数据集表示需要更改的数据集,修改数据集中包含了用于更改的数据,此时必须使用BY语句。在使用MODIFY时,主数据集和 修改数据集中的BY变量不需要事先排序或索引,但是按BY变量排序或 索引可以提高运行效率,特别是在观测量很大的情况下。
在使用MODIFY更改数据集时,需要注意以下两点:
- ·当主数据集中的BY变量值有重复值时,只有每个BY变量值的第一条观测会被更改;当修改数据集中的BY变量值有重复值时,系统会依次读入修改数据集中的每一条观测,并应用到主数据集,且后读入的观 测会覆盖前一次读入的观测;当主数据集和修改数据集中的BY变量值都有重复值时,系统会依次操作修改数据集中BY组合中的每一条观测,并且应用到主数据集中对应BY组合的第一条观测中。
- ·如果在修改数据集中存在缺失值,系统默认不用缺失值更改主数据集中的数据。如果需要用缺失值更改主数据集,可以仿照在UPDATE 语句中使用选项UPDATEMODE=实现操作。
实际上,在主数据集或修改数据集中BY变量值有重复值时,MODIFY语句的处理逻辑和UPDATE语句一样。
例4.12:接着例4.11继续操作,数据集work.inventory2中保存了公司 产品在海外仓库的库存信息,现在公司财务欲根据work.inventory和 work.inventory2中的数据计算公司各产品的总库存,并制作报告。
以下代码创建数据集work.inventory2。
data work.inventory2; input Product_ID $ Outstock ; datalines; P001R 12 P001R 30 P001R 25 P003T 34 P301M 23 ; proc print data=work.inventory noobs; title "Warehouse Inventory Inhouse"; run; proc print data=work.inventory2 noobs; title ‘Warehouse Inventory Overseas‘; run;
两个数据集work.inventory和work.inventory2的内容如图4.21所示。 需要注意的是,在work.inventory2中,产品P001R有三条观测。 计算各产品总库存的程序如下:
data work.inventory; modify work.inventory work.inventory2; by product_id; instock=instock+Outstock; run; proc print data=work.inventory noobs; title ‘Total Inventory‘; run;
程序中加入“instock=instock+Outstock;”用来计算instock并输出到数据集work.inventory中,产品P001R的instock的值等于原work.inventory 数据集中P001R的instock值加上work.inventory2中P001R的3条观测的 instock值。
以上例子中,修改数据集中的所有观测在主数据集中都可以找到对 应的观测,当修改数据集中含有一些新观测时,可以使用OUTPUT语句 将新观测添加到主数据集中,具体使用方法请查询SAS帮助文档。
6. 数据集处理的一点补充
1 使用数据集选项END=
很多情况下,在进行数据操作时需要知道SAS在什么时候处理输入 数据集的最后一条观测,这时可以使用SAS提供的数据集选项END=来 帮助辨识。使用数据集选项END=的基本形式如下:
SET 数据集1 <数据集2 数据集3… >END=变量;
在使用SET、MERGE、MODIFY、UPDATE语句时,都可以使用该 选项。这里语句中的变量是数值型的临时变量,当DATA步在操作数据 集的最后一条观测时,该变量的取值为1,否则为0。临时变量可以在 DATA步中使用,但是不会在数据集中输出。需要特别注意的是,在使 用SET、MERGE、MODIFY、UPDATE语句进行多个数据集处理时,只有当DATA步处理所有输入数据集的最后一条观测时,该变量的取值才 会由0变成1。
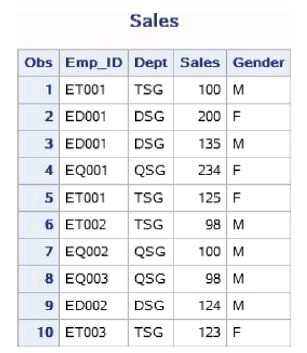
数据集work.Sales中记录了公司每位员工的全年的销售额, 现在欲计算全年公司的总销售额,并输出到报表中。
以下代码创建了work.Sales数据集,Emp_ID表示员工编号,Dept表示员工所属部门,Sales表示销售额。
data work.sales; input Emp_ID $ Dept $ Sales Gender$; datalines; ET001 TSG 100 M ED001 DSG 200 F ED001 DSG 135 M EQ001 QSG 234 F ET001 TSG 125 F ET002 TSG 98 M EQ002 QSG 100 M EQ003 QSG 98 M ED002 DSG 124 M ET003 TSG 123 F ; run; proc print data=work.sales; title ‘Sales‘; run;
现在运用END=选项计算公司全年的总销售额。
data work.total_sales; set work.sales END=last; total_sales+sales; if last then output; keep total_sales; run; proc print data=work.total_sales noobs; title ‘Total Sales in Million‘;run;
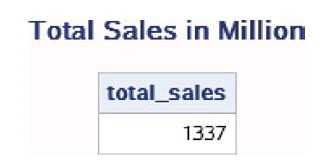
上面这段代码中有以下几个要点:
- ·END=last定义了临时变量last,当SAS在处理最后一条观测时,last的取值将变为1。
- ·“total_sales+sales;”计算公司的全年销售 额。“total_sales+sales;”的作用和“retain total_sales 0; total_sales=total_sales+sales;”一样。
- ·IF语句和OUTPUT语句判断了最后一条观测,并将该观测输出到数据集中。
- ·KEEP语句仅将需要输出的total_sales变量保留在数据集中。 上面计算全年销售额的代码和下面的代码等价。
data work.total_sales; set work.sales END=last; retain total_sales 0; total_sales=total_sales+sales; if last then output; keep total_sales;
5.2 使用自动变量FIRST.与LAST.
在DATA步中若使用了BY语句,SAS要求读入的数据集必须按BY 变量排序(MODIFY语句除外),同时,SAS在程序执行过程中会自动 生成两个数值型临时变量:FIRST.变量和LAST.变量,它们分别用来辨 识BY组合的第一条观测和最后一条观测。当只有一个BY变量时,很容 易理解它的取值。
·当DATA步正在处理该BY变量值的第一条观测时,FIRST.变量为1,否则为0。
·当DATA步正在处理该BY变量值的最后一条观测时,LAST.变量为1,否则为0。
当有多个BY变量时,系统会自动生成多对FIRST.变量和LAST.变 量。例如,SAS在执行如下代码时,会自动生成临时变量FIRST.x和 LAST.x,以及FIRST.y和LAST.y。
data work.test; input x y $ @@; datalines; 1 A 1 A 1 B 2 B 2 C ; run; data work.try; set work.test; by x y; firstx=first.x; lastx=last.x; firsty=first.y; lasty=last.y; run;
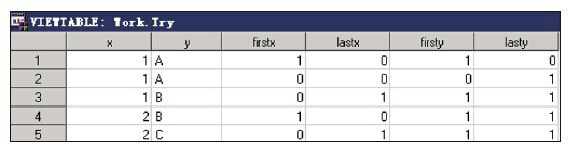
当SAS处理第一条x=1的观测时,first.x=1;当SAS处理最后一条 x=1的观测时,last.x=1;当SAS处理第一条x=1并且y=“A”的观测时, first.y=1;当SAS处理最后一条x=1并且y=“A”的观测时,last.y=1。
据集work.Sales中包含了每位员工的销售额和员工所属部
门及性别数据,现在公司欲统计各部门男员工和女员工的总销售额,并 制成报表。
首先将work.Sales数据集按Dept和Gender进行排序,然后再运用选 项FIRST.与LAST.计算各部门男女员工的总销售额。
proc sort data=work.sales; by Dept Gender; run; data work.sales_dept; set work.sales; by Dept Gender; retain sales_by_dept; if first.Gender then sales_by_dept=0; sales_by_dept=sales_by_dept+sales; if last.Gender; keep Dept Gender sales_by_dept; run; proc print data=work.sales_dept noobs; title ‘Sales by Department by Gender‘; run;
“if last.gender;”是“if last.gender then output;”的省略写法。这里使用了RETAIN语句,使得在DATA步的循环中sales_by_dept的值可以保留 在PDV中。BY语句创建的这两个临时变量不仅可在SET语句读入单个数据集时 使用,在进行多个数据集的拼接时也常使用。
5.3 使用SET语句中的选项POINT=和NOBS=
在DATA步使用SET语句读入数据集时,可使用选项POINT=指明要 读入的观测序号。使用选项POINT=的基本语法如下:
SET 数据集POINT=指针变量;
其中指针变量用来指明要读入特定序号的观测,必须在SET语句执 行前对它赋值。在有SET语句的DATA步程序中,系统将反复执行 DATA步的语句,直到遇到数据中的文件结束标志。但是在使用选项 POINT=时,系统会直接读入指针指向的记录,这就很可能导致系统不 会遇到文件结束标志,容易陷入死循环。因而在按指针读入数据的程序 中,经常会用到STOP语句。
如果要取得数据集中观测的个数,可以使用SET语句中的选项
NOBS=,语法如下:
NOBS=变量;
其中,变量同样是临时变量,在DATA步的编译阶段赋值。
例4.15:现有一个数据集work.Whole,欲从其中随机抽取1/3的观测
用来建立模型。
示例代码如下:
data work.sample;
do i=1 to total by 3;
set work.whole point=i nobs=total;
output;
end;
stop;
run;
运行这个代码,系统将从数据集work.sample中依次抽出第1条观 测、第4条观测…,并存储到数据集work.sample,直到系统处理完数据 集中的全部观测。
5.4 使用多个SET语句
在SAS中实现同一个操作,往往可以有多种方法。作为补充,这里 将介绍如何运用SET语句进行数据集横向合并。使用SET进行横向合并 的一个好处是,在合并之前不需要将输入数据集进行排序。
例 下是使用多个SET语句的一个简单例子。
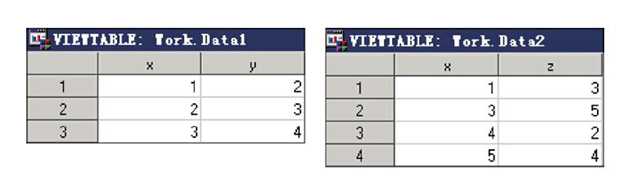
data work.data1; input x y @@; datalines; 1 2 2 3 3 4 ; run; data work.data2; input x z @@; datalines; 1 3 3 5 4 2 5 4 ; run; data work.combined; set work.data1; set work.data2; run; proc print data=work.Combined; title ‘Using Two Set in Data Step‘; run;
数据集work.data1和数据集work.data2的内容如所示。 合并后的数据集work.combined如图所示。
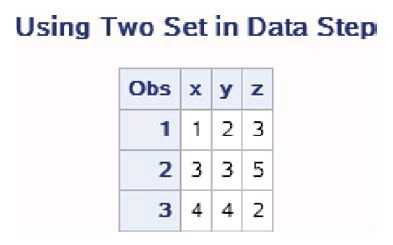
在使用多个SET语句时,PDV中的变量是读入数据集的并集。首 先,DATA步从第一个SET语句中读入第一条观测,并复制到PDV中; 然后从第二个SET语句中读入第一条观测,并复制到PDV中。当输入数 据集中有同名变量时,后读入的数据集的变量值覆盖前一个数据集中同 名变量的值。新数据集中的观测数是所有输入数据集中的观测数的最小 值,因为当DATA步遇到第一个文件结束标志时,DATA步就结束执 行。
5.5 使用HASH对象处理多个数据集
前面部分已经介绍了运用SET语句和MERGE语句进行数据集之间的拼接,这里将通过实例介绍如何运用HASH对象实现这类操作。相较于SET语句和MERGE语句,使用HASH对象有两个优点,第一,它对数据集的排序没有要求;第二,由于HASH对象是放入内存中的数据集,因此在内存允许的情况下,运用HASH对象进行数据集之间 的关联时其效率更高。
一般在观测数很多的数据集与观测数较少的数据集进行匹配时,运用HASH对象将较小的数据集加载到内存中,可以非常快速地完成匹 配。
接下来首先介绍在DATA步中如何定义HASH对象。
1.定义HASH对象
使用HASH对象时,首先要定义HASH对象,基本形式如下:
DECLARE object HASH对象名(<主题1: 内容1 <, 主题2: 内容2, …>>); HASH对象名.DEFINEKEY(<主题1: 内容1 <, 主题2: 内容2, …>>); HASH对象名.DEFINEDATA(<主题1: 内容1 <, 主题2: 内容2, …>>); HASH对象名.DEFINEDONE();
这里第一行定义了HASH对象名称,object可以是HASH或HITER,HASH对象名由编程者定义。
第二行和第三行分别通过HASH对象名.method的语法定义了HASH对象的KEY变量和DATA变量,这些变量都是DATA步中的变量。 第四行表明HASH对象定义结束。
现在有一个数据集work.Sales,其中包含了员工编号 Emp_ID、员工部门Dept、销量Sales、产品编号Product_id,另一个数据 集work.Product中包含了Product_id、Product_name和Description 3个变 量,现在欲将Product_name和Description加到数据集Sales中。
以下代码生成Sales和Product中的部分数据。
data work.sales; input Emp_ID $ Dept $ Sales Product_ID $; datalines; ET001 TSG 100 P001 ED001 DSG 120 P001 ET001 TSG 50 P002 EC001 CSG 230 P004 EQ001 QSG 150 P003 ET001 TSG 210 P004 ET002 TSG 40 P002 ET003 TSG 150 P003 ; run; data work.product; infile datalines dsd; length Product_ID $4 Product_Name Description $35; input Product_ID $ Product_Name $ Description $;
datalines; P001,ManufacturingIndustry Solutions,ManufacturingIndustry Solutions V2 P002,Logistics Solutions,Logistics Solutions V1 P003,Financial Service Solutions,Financial Service Solutions V3 P004,Insurance Solutions,Insurance Solutions V2 ; run;
以下是通过HASH对象实现匹配的完整代码。
data work.sales_description(drop=ErrorDesc) work.exception; length Product_ID $8 Product_Name Description $35; if _N_=1 then do; /*Define hash objective*/ Declare hash product_desc(dataset:"work.product"); product_desc.definekey(‘Product_ID‘); product_desc.definedata(‘Product_Name‘,‘Description‘); product_desc.definedone(); call missing(Product_ID,Product_Name,Description); end; set work.sales; /*Retrieve matching data*/ rc=product_desc.find(); if rc = 0 then output sales_description; else do; ErrorDesc="No Product Description"; output exception; end; drop rc; run;
以上是关于SAS 对数据的拼接与串接的主要内容,如果未能解决你的问题,请参考以下文章