HashMap源码解读(jdk1.8)
Posted xuezhankui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap源码解读(jdk1.8)相关的知识,希望对你有一定的参考价值。
一般在工作中,只有出问题的时候才会看看源码,很少有时间去单独看一下源码。
正好还没找到工作,朋友提了一句看看HashMap,所以花了点时间看了看。
对于翻源码这件事情,如果没有使用过,自己会像无头苍蝇一样,不知道从哪里开始。
对于HashMap,常用作key value容器,基本的使用方式,就是new 一个实例,put、get,或者通过keyset、entry遍历。
Map map = new HashMap();
map.put(XX,XX); map.get(XX,XX);
map.keySet(); map.entrySet();
按照这个思路,我开始看源码了:
1.看构造函数
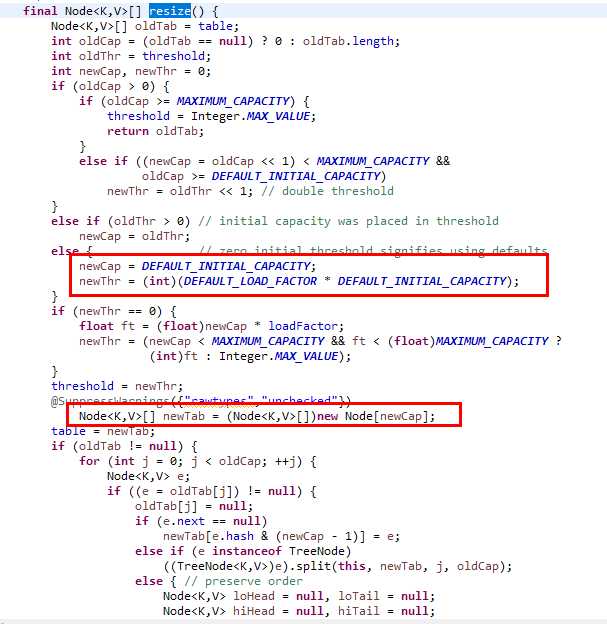
可入参的变量只有两个,中文翻译过来,一个是容量cap,一个是因子factor。
默认cap=16,factor=0.75。其实还有一个极限值,默认情况下是16*0.75=12,在resize()里面。
2.存储结构
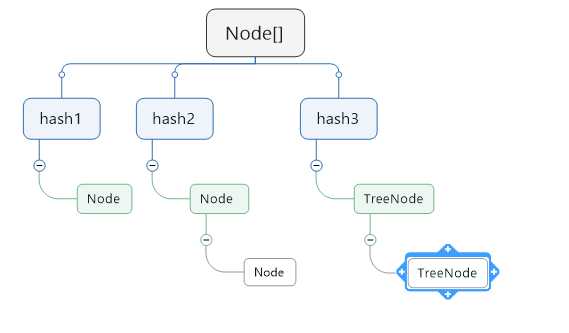
最外层是数组Node<K,V>[] table;
在put或get的时候,都会取key的hash值无符号右移做做异或预算,形成新的hash值,并用hash值作为数据下标,存入或者定位Node。

table数组中存放的不止是Node对象,还有TreeNode对象,TreeNode继承自LinkedMap.Entry<K,V>,LinkedMap.Entry<K,V>继承自Node。
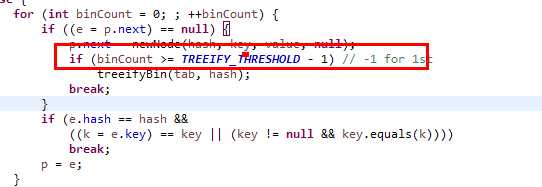
其中,使用Node或者TreeNode是有要求的,类中有TREEIFY_THRESHOLD和UNTREEIFY_THRESHOLD作为转化的数量参考。
Node本身是链表结构,当相同hash值的key被存入,会对比hash值大小,来决定Node.next的值。
TreeNode中,则是主要维护TreeNode.left和TreeNode.right.
就是说,虽然是数组,但数组中的每一个Node,不一定只存了一个key和value。
按照HashMap中hash方法的说明,已经尽量减少冲突了。
基本结构如图
3.容量变化
根据resize()方法,当size>极限值,就是第一条中说的,默认是16*0.75的,容量和极限值都会左移1位,即乘2。
当Node里面的数量>=TREEIFY_THRESHOLD-1的时候,该Node需要转化为TreeNode
4.额外说明
在HashMap中,设置初始容量之后,初始容量不一定等于你设置的数量。
只是16恰巧满足条件,计算初始容量的代码如下
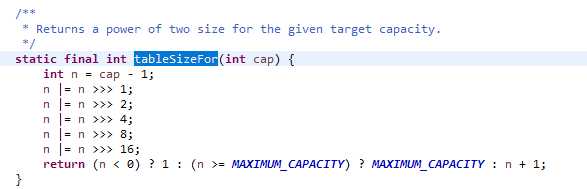
这个方法,我的结论是为了保证容量2的n次方。
减一是因为2进制从0开始,又因为int转2进制,打印出来一共32位,所以分别右移2、4、8、16,将设定的数值的2进制lowbit都变成1,这样最后加1后,得到的数字肯定是2的n次方。
我的猜测是,因为使用了TreeNode,所以极限情况下,就是数组中全是TreeNode,达到极限的数量时,能满足二叉树结构的数量。
以上是关于HashMap源码解读(jdk1.8)的主要内容,如果未能解决你的问题,请参考以下文章
HashMap底层原理及jdk1.8源码解读吐血整理1.3w字长文