Transformer中的Self-Attention
Posted yzykkpl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer中的Self-Attention相关的知识,希望对你有一定的参考价值。
Transformer
Transformer是Google的论文《Attention is All You Need》种提出的结构。读完论文之后对于Transformer的细节还是搞不清楚,查阅了很多解读文章,并结合代码终于算是弄得算比较清楚了。我现在尝试结合图片的方式对Transformer的工作流程进行梳理,图片基本上都来自于这个blog。我觉得这位大神讲得很好了,只是有些地方有点繁琐,而且是英文的,所以我用他的图片结合我自己的理解进行梳理。
Transformer是做什么的?
我认为Transformer的提出是为了用纯Attention的结构替代LSTM解决Seq2Seq任务,但是整体来说依然是Encoder-Decoder结构。用全Attention的结构可以进行并行计算(计算量其实很大,只是提高了并行计算效率,所以比LSTM快),加快训练速度。接下来从外到内逐渐深入Transformer看看是如何工作的。
典型任务--机器翻译
对于机器翻译这个典型的Seq2Seq任务,用来讲解Transformer再适合不过了。
![]()
Transformer由Encoder和Decoder组成,这和传统的Seq2Seq结构相同,Encoder将字符序列编码为向量,decoder将该向量解码为字符序列。Transformer的特点是有多个encoder和多个decoder,可以称他们为encoder栈和decoder栈。
![]()
这里值得说明的一点是每一个小的encoder之间是相互独立的,他们不共享参数,虽然图片上看起来和LSTM很想,但是不要和LSTM混淆,decoder也是一样。每一个encoder又包含两层——self-attention和feed-forward neural network。
![]()
self-attention:帮助Endcoder在编码单词的过程中查看输入序列中的其他单词,其实就是应用Attention机制的地方
feed-forward neural network 前馈神经网络,可以理解为全连接层
decoder的比encoder多一层

注意这个Encoder-Decoder Attention层,这里是在当前的输出字符和输入之间应用Attention,encoder的Self-Attention是输入的当前字符和输入之间应用Attention,这就是self的含义。Encoder-Decoder Attention和以前的Seq2Seq with Attention 是类似的。
工作流程
1.常规操作embbding,这个NLP的预备动作就不多说了。英文的可以用glove,中文的可以用腾讯AI Lab公开的词向量。这里假设词向量维度为512,但是我用4维向量省略表示,只要清楚每一个词被转换成相同维度的向量就行了。

最下面的一个encoder的输入就是一堆512的词向量组成的list,输出一堆512的向量(不再是词向量)的list,其余的encoder的输入是上一个encoder的输出。所以每一个encoder的输入输出都是一堆512向量的list,这个list的大小是超参数,通常取数据集中句子的最大长度,如果数据集中最长的句子有20个词,那么输入和输出就是20个512的向量。
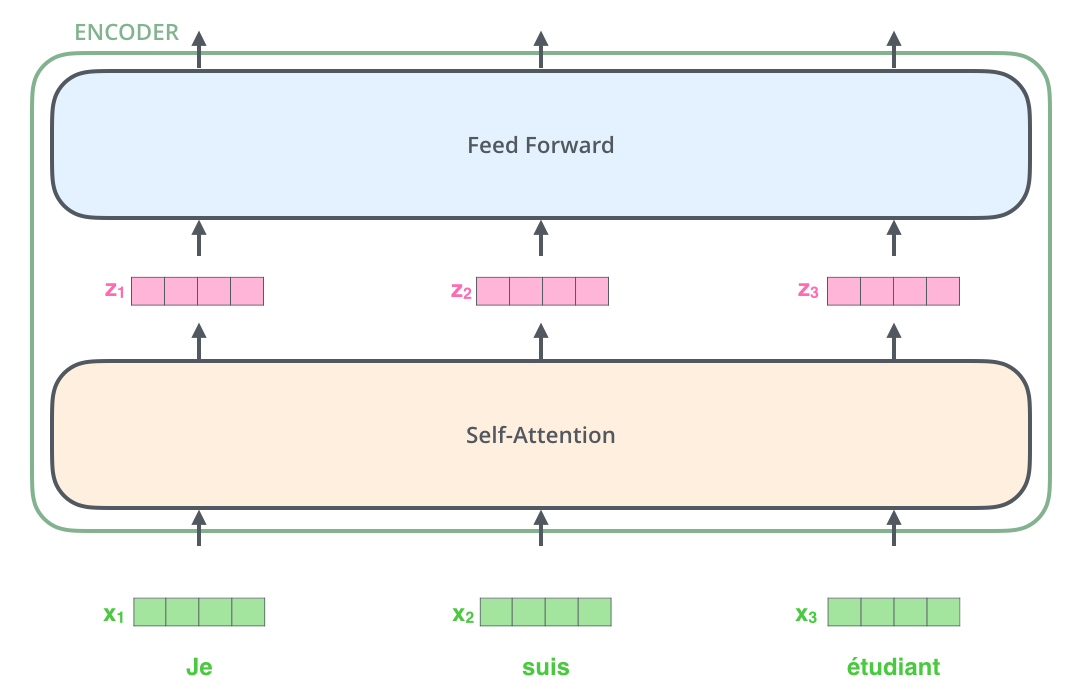
注意这里不是把20个512的向量拼在一起,而是每一个独立地通过encoder,每个单词进入Self-Attention层后都会有一个对应的输出。Self-Attention层中的输入和输出是存在依赖关系的,而前馈层则没有依赖,所以在前馈层,我们可以用到并行化来提升速率。接下来看看这两个子层内部地数据流动过程。
Encoder
Transformer中的每个Encoder接收一个512维度的向量的列表作为输入,然后将这些向量传递到Self-attention层,Self-attention层产生一个等量512维向量list,然后进入前馈神经网络,前馈神经网络的输出也为一个512维度的list,然后将输出向上传递到下一个encoder。就像这样:

虽然这个图片上的前馈神经网络是分开的,但其实他们的参数是一摸一样的(只是为了体现并行),我自己画图太丑所以直接用别人的图,如果有需要说明的地方我会提的。
Self-Attention
最常见的Attention机制的主要思想是对于当前输出的词,每一个输入的词对它的影响是不同的,即输入的权重对输出的影响。注意“Attention”完全可以就按“注意力”的字面意思直观理解,就是从当前词的角度来说,对于其他词分配的注意力是不同的。而在《Attention is All You Need》中所说的Self-Attention是对于输入中的某一个词,其他输入的词对它的影响是不同的,即输入的权重对其中一个输入的词影响,以此来寻找编码这个单词更好的线索。这也是Transformer的encoder产生的编码结果更好的原因,举个例子就清楚了。比如现在要翻译一句话:"The animal didn‘t cross the street because it was too tired", 这句话中的"it"指的是什么?它指的是“animal”还是“street”?对于人来说,这其实是一个很简单的问题,但是对于一个算法来说,处理这个问题其实并不容易。self attention的出现就是为了解决这个问题,通过self attention,我们能将“it”与“animal”联系起来,最终的编码结果就会包含这个信息,其实传统的用RNN处理时序信息的目的也是为了将各元素的相关性包含在编码结果中。

这是可视化的结果,可以在google的Tensor2Tensor上自己运行看一下。
看看Self-Attention是如何计算出来的
上面说到Attention简单来说就是每个词对于当前词的影响大小,即对于每个词我们给予多少的注意力。如何量化这个注意力的分配?我们要给每一个词一个“分数”或者“注意力值”,这个“分数”的计算过程是这样的:

我们以第一层encoder(即输入为单词的embedding),对于每一个单词:
- 1.计算Query,Key,Value三个向量,这三个向量由embedding与三个矩阵WQ、WK、WV相乘所得,在我们的例子中,这三个矩阵都是512x64的,q,k,v三个向量都是64维的。
- 2.设第i个词对应的向量是qi,ki,vi。图中当前词是第一个词Thinking,那么每个词的score就是q1点乘ki。
- 3.score除以8(可以是其他数,目的是减小score,论文里取q向量维数的开方,就是8)并将所有的score进行Softmax。Softmax是注意力机制都会做的,这个softmax score就是当在处理当前词时分配给每个词的注意力的百分比。
- 4.现在要用到value向量了,将上一步得到的softmax score乘以对应的vi,图上就是0.88乘以v1,0.12乘以v2,自然的经过这一步之后,score小的(相关性不强或者说注意力分配少的)词的value就会小,反之,score大的(需要特别注意的)词的value就会大。
- 5.把加工过后的所有value加在一起得到z向量,注意图上z1是针对“Thinking”计算出来的,z2是针对“Machines"计算出来的,计算z2的value不是图上的v1和v2,需要重新计算。
(注:上面这一整个过程只是计算一个词的z向量的过程。)
在实际的实现过程中,该计算会以矩阵的形式完成,以便更快地处理。
矩阵化
过程和单个向量相同:
1.计算Q/K/V矩阵,看图就清楚了:

X矩阵的每一行就是一个词的embedding,三个W参数矩阵与之前说的相同。
2.合并之前的2-5步,直接得到Z矩阵:

multi-headed
论文中在Self-Attention的基础上加入了multi-headed机制,在两个方面优化了attention:
1.它拓展了模型关注不同位置的能力。
2.它为attention层提供了多个“representation subspaces(表示子空间)”。由下图可以看到,在self attention中,我们有多个个Query / Key / Value权重矩阵(Transformer使用8个attention heads)。这些集合中的每个矩阵都是随机初始化生成的。然后通过训练,用于将词嵌入(或者来自较低Encoder/Decoder的矢量)投影到不同的“representation subspaces”中。
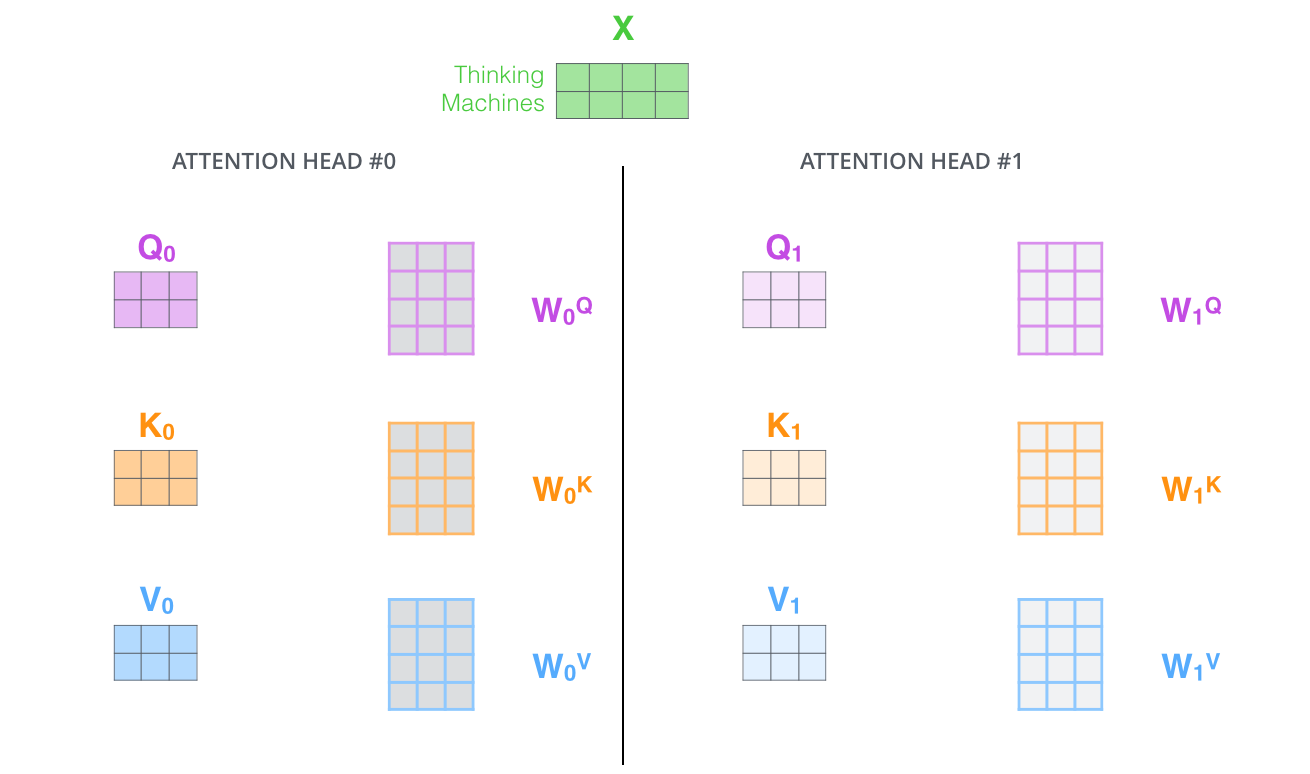
通过multi-headed attention,我们为每个“header”都独立维护一套Q/K/V的权值矩阵。然后我们还是如之前单词级别的计算过程一样处理这些数据。
如果对上面的例子做同样的self attention计算,而因为我们有8头attention,所以我们会分别计算这些不同的权值矩阵,但最后结束时,我们会得到8个不同的Z矩阵。如下图:
![]()
但是有一个问题,我们的前馈神经网络需要的是一个shape为(N,512)的矩阵(N是任意值,代表同时处理多少个词),而不是8个shape为(N,64)的矩阵,所以要把这8个Zi合成一个Z,怎么合?简单相加?取平均?这些粗暴的方法都不合适,正确的做法是让模型去学习怎么合!经过训练模型会学得比我们人工合并要好(这个思想其实可以用到以前的CNN处理NLP任务的模型中,过去大多数都是粗暴的人工合成多个embedding)。
![]()
先把8个Z按顺序拼接在一起,然后乘上一个大矩阵WO,shape是(64x8,512),可以自己结合上文各矩阵维度推一下。结果就是一个shape为(N,512)的Z。
至此multi-headed self-attention就介绍完了。放一个整体图感受一下:
![]()
如果是第一层encoder,输入就是embedding(图中X),其他encoder就是上一个encoder的输出(图中R)
让我们重新审视我们之前tensor2tensor的例子,看看例句中的“it”这个单词在不同的attention header情况下会有怎样不同的关注点。
![]()
关于“it”这个词,不同head的关注点不同,除了橙色的head好理解之外(关注在The animal是正确的),其他的说实话我看不懂,但是不影响模型效果好,不明觉厉?
Positional Encoding
除了注意力之外,还要关注序列问题自身的一个很重要的特点--顺序性,这也是为什么最初要用RNN处理序列问题的原因。为了解决顺序问题,Transformer为每个输入单词的embedding上添加了一个新向量-位置向量,关于如何生成这个位置向量可以看tensor2tensor源码。在上文提到的embedding上直接加上位置向量就行了,就像这样:
![]()
Residual connection(Shortcut)
在每一个self-attention和前馈神经网络层之后,都会将该层的输入与输出相加并进行LayerNormalization的操作,其实就是在每一个z层面的归一化,注意与BatchNormalization的区别。这里将输入与输出相加的形式其实就是Shortcut connection,不清楚的可以去看看ResNet的思想。
![]()
在decoder中也有这样的操作:
![]()
Decoder
Decoder的部分与常规seq2seq+Attention大致相同,其中的self-attention与encoder的相同,我就不多说了,放个示意图。其实最关键的是搞明白multi-headed self-attention是怎么编码序列信息的。
![]()
以上是关于Transformer中的Self-Attention的主要内容,如果未能解决你的问题,请参考以下文章