spark记录spark算子之Transformation
Posted kpsmile
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark记录spark算子之Transformation相关的知识,希望对你有一定的参考价值。
一、map、flatMap、mapParations、mapPartitionsWithIndex
1.1 map
map十分容易理解,他是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的JavaRDD。
(1) 使用Java进行编写
public static void map() { List<String> list = Arrays.asList("李光洙","刘在石","哈哈","宋智孝"); JavaRDD<String> rdd = jsc.parallelize(list); JavaRDD<String> map = rdd.map(new Function<String, String>() { private static final long serialVersionUID = 1L; @Override public String call(String name) throws Exception { return "hello,"+name; } }); map.foreach(new VoidFunction<String>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(String msg) throws Exception { System.out.println(msg); } }); }
(2) 使用scala进行编写
def map(): Unit = { val list = List("李光洙","刘在石","哈哈","宋智孝"); val rdd = sc.parallelize(list) val map = rdd.map(s => "hello," + s).foreach(println) }
(3)运行结果
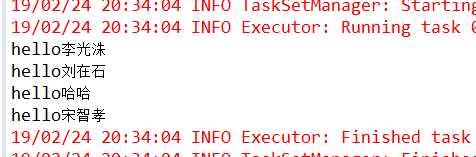
(4) 总结
可以看出,对于map算子,源JavaRDD的每个元素都会进行计算,由于是依次进行传参,所以他是有序的,新RDD的元素顺序与源RDD是相同的。而由有序又引出接下来的flatMap。
1.2 flatMap
flatMap与map一样,是将RDD中的元素依次的传入call方法,他比map多的功能是能在任何一个传入call方法的元素后面添加任意多元素,而能达到这一点,正是因为其进行传参是依次进行的。
(1) 使用Java进行编写
public static void flatmap() { List<String> list = Arrays.asList("李光洙 刘在石","哈哈 宋智孝"); JavaRDD<String> rdd = jsc.parallelize(list); JavaRDD<String> map = rdd.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }).map(new Function<String, String>() { private static final long serialVersionUID = 1L; @Override public String call(String s) throws Exception { return "你好," + s; } }); map.foreach(new VoidFunction<String>() { @Override public void call(String s) throws Exception { System.out.println(s); } }); }
(2) 使用scala进行编写
def flatmap(): Unit = { val list = List("李光洙 刘在石","哈哈 宋智孝"); val rdd = sc.parallelize(list) rdd.flatMap(_.split(" ")).map("你好,"+_).foreach(println) }
(3) 运行结果
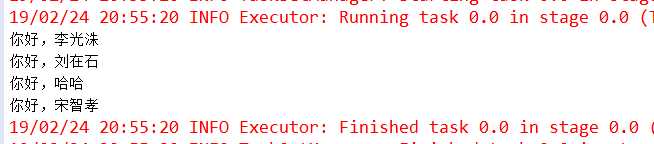
(4) 总结
flatMap的特性决定了这个算子在对需要随时增加元素的时候十分好用,比如在对源RDD查漏补缺时。
map和flatMap都是依次进行参数传递的,但有时候需要RDD中的两个元素进行相应操作时(例如:算存款所得时,下一个月所得的利息是要原本金加上上一个月所得的本金的),这两个算子便无法达到目的了,这是便需要mapPartitions算子,他传参的方式是将整个RDD传入,然后将一个迭代器传出生成一个新的RDD,由于整个RDD都传入了,所以便能完成前面说的业务。
map是对RDD中元素逐一进行函数操作映射为另外一个RDD,而flatMap操作是将函数应用于RDD之中的每一个元素,将返回的迭代器的所有内容构成新的RDD。而flatMap操作是将函数应用于RDD中每一个元素,将返回的迭代器的所有内容构成RDD。
flatMap与map区别在于map为“映射”,而flatMap“先映射,后扁平化”,map对每一次(func)都产生一个元素,返回一个对象,而flatMap多一步就是将所有对象合并为一个对象。
1.3 mapPartitions
与map方法类似,map是对rdd中的每一个元素进行操作,而mapPartitions(foreachPartition)则是对rdd中的每个分区的迭代器进行操作。如果在map过程中需要频繁创建额外的对象(例如将rdd中的数据通过jdbc写入数据库,map需要为每个元素创建一个链接而mapPartition为每个partition创建一个链接),则mapPartitions效率比map高的多。
(1) 使用Java进行编写
public static void mapPartitions() { JavaRDD<String> textFile = jsc.textFile("words",3); textFile.mapPartitions(new FlatMapFunction<Iterator<String>, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(Iterator<String> is) throws Exception { System.out.println("创建数据库连接。。。。"); List<String> list = new ArrayList<String>(); while(is.hasNext()) { list.add(is.next()); System.out.println("模拟向数据库插入批量数据。。。"); } System.out.println("关闭数据库连接。。。"); return list; } }).collect(); }
(2) 使用scala进行编写
def mapPartitions: Unit = { val rdd1 = sc.textFile("words") val mapResult = rdd1.mapPartitions(iter =>{ println("打开数据库。。。") val list = List() while(iter.hasNext){ list.addString(new StringBuilder(iter.next())) println("插入数据库。。。") } println("关闭数据库。。。") list.iterator }, false) mapResult.foreach(println) }
(3) 运行结果
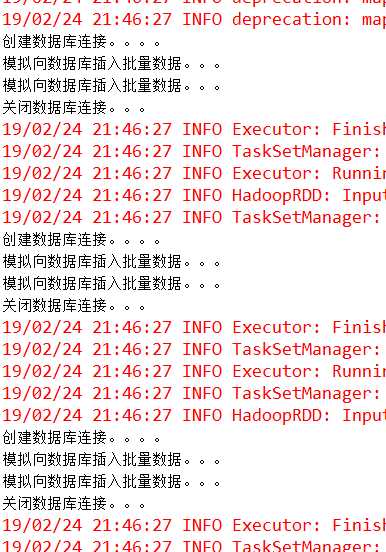
(4)总结
mapPartitions比较适合需要分批处理数据的情况,比如将数据插入某个表,每批数据只需要开启一次数据库连接,大大减少了连接开支。
1.4 mapPartitionsWithIndex
每次获取和处理的就是一个分区的数据,并且知道处理的分区的分区号是什么
(1)使用Java编写
public static void mapPartitionsWithIndex() { List<String> list = Arrays.asList("李光洙","刘在石","哈哈","宋智孝"); JavaRDD<String> rdd = jsc.parallelize(list,3); JavaRDD<String> rdd2 = rdd.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() { private static final long serialVersionUID = 1L; @Override public Iterator<String> call(Integer index, Iterator<String> iter) throws Exception { List<String> list = new ArrayList<String>(); while(iter.hasNext()) { list.add(index+"_"+iter.next()); } return list.iterator(); } }, true); rdd2.foreach(new VoidFunction<String>() { @Override public void call(String s) throws Exception { System.out.println(s); } }); }
(2)使用scala编写
def mapPartitionsWithIndex: Unit = { val list = List("李光洙","刘在石","哈哈","宋智孝") val rdd1 = sc.parallelize(list, 3) val rdd2 = rdd1.mapPartitionsWithIndex((index,iter)=>{ val l = ListBuffer[String]() while(iter.hasNext){ val v = iter.next() l.append(index+"_"+v) } l.iterator }, true).foreach(println) }
(3)结果
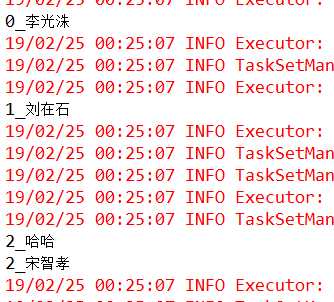
以上是关于spark记录spark算子之Transformation的主要内容,如果未能解决你的问题,请参考以下文章
Spark算子篇 --Spark算子之aggregateByKey详解