一。概念
rdd.combineByKey(lambda x:"%d_" %x, lambda a,b:"%[email protected]%s" %(a,b), lambda a,b:"%s$%s" %(a,b))
三个参数(都是函数)
第一个参数:给定一个初始值,用函数生成初始值。
第二个参数:combinbe聚合逻辑。
第三个参数:reduce端聚合逻辑。
二。代码
from pyspark.conf import SparkConf from pyspark.context import SparkContext conf = SparkConf().setMaster("local").setAppName("CombineByKey") sc = SparkContext(conf = conf) rdd = sc.parallelize([("A",1),("B",2),("B",3),("B",4),("B",5),("C",1),("A",2)], 2) def f(index,items): print "partitionId:%d" %index for val in items: print val return items rdd.mapPartitionsWithIndex(f).count() combinerRDD = rdd.combineByKey(lambda x:"%d_" %x, lambda a,b:"%[email protected]%s" %(a,b), lambda a,b:"%s$%s" %(a,b)) combinerRDD.foreach(p) groupByKeyRDD.foreach(p) sc.stop()
三。解释
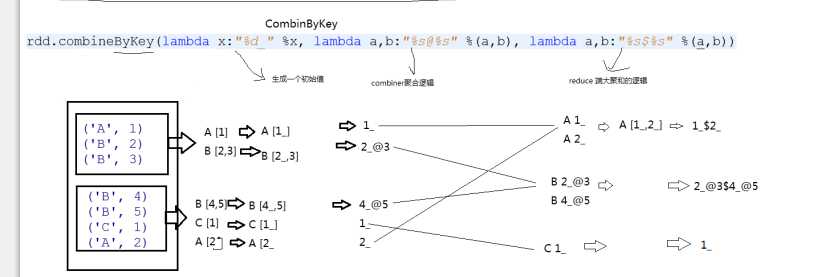
第一个函数作用于每一个组的第一个元素上,将其变为初始值
第二个函数:一开始a是初始值,b是分组内的元素值,比如A[1_],因为没有b值所以不能调用combine函数,第二组因为函数内元素值是[2_,3]调用combine函数后为[email protected],以此类推
第三个函数:reduce端大聚合,把相同的key的数据拉取到一个节点上,然后分组。
四。结果

五。拓展
1.用combinebykey实现groupbykey的逻辑
1.1 combinebykey的三个参数
第一个应该返回一个列表,初始值
第二个函数中的a依赖于第一个函数的返回值
第三个函数的a,b依赖于第二个函数的返回值
1.2 解释:

1.3 代码:
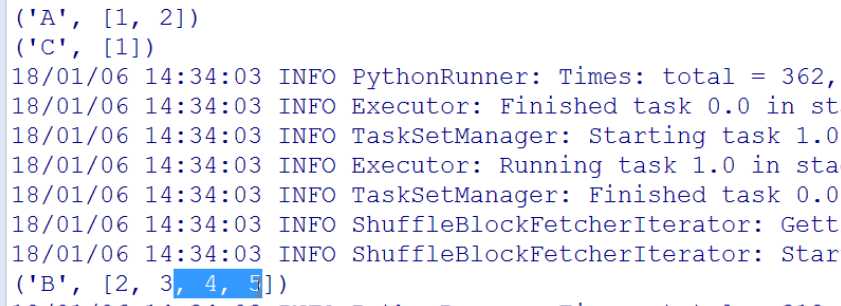
def mergeValue(list1,b): list1.append(b) return list1 def mergeCombiners(list1,list2): list1.extend(list2) return list1 groupByKeyRDD = rdd.combineByKey(lambda a:[a],mergeValue,mergeCombiners)
1.4结果
2.使用combineBykey把相同的key和对应的逻辑相加起来
代码:
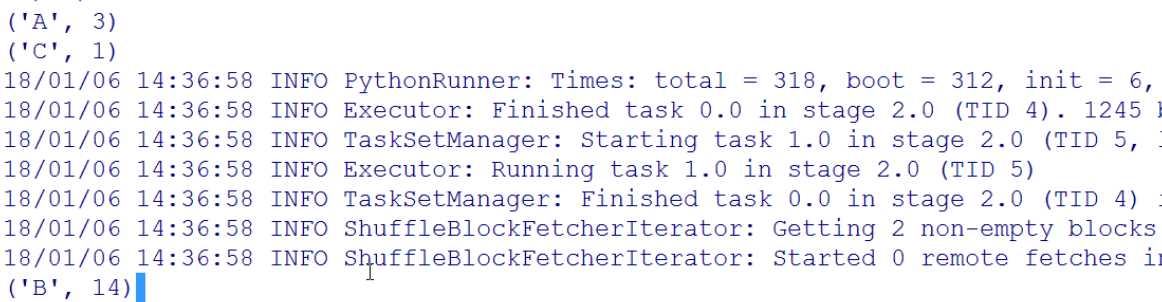
reduceByKeyRDD = rdd.combineByKey(lambda a:a,lambda a,b:a+b,lambda a,b:a+b)
结果:
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.
