论文速读(Yongchao Xu——2018TextField_Learning A Deep Direction Field for Irregular Scene Text)
Posted lillylin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文速读(Yongchao Xu——2018TextField_Learning A Deep Direction Field for Irregular Scene Text)相关的知识,希望对你有一定的参考价值。
Yongchao Xu——【2018】TextField_Learning A Deep Direction Field for Irregular Scene Text Detection
论文
Yongchao Xu——【2018】TextField_Learning A Deep Direction Field for Irregular Scene Text Detection
作者
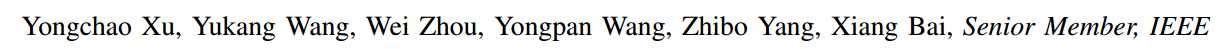
亮点
- 提出的TextField方法非常新颖,用点到最近boundary点的向量来区分不同instance
方法概述
针对曲文检测,采用Instance-segmentation思路,提出一种对于分割点的新的表示方法TextField,旨在解决text instance的黏连问题。
TextField是一个二维的向量v,用来表示分割score map上的每一个点,它的含义是:每个text像素点到离自己最近的boundary点的向量。它的属性包括:
- 非text像素点=(0, 0),text像素点 $ e$ (0,0)
- 向量的magnitude,可以用来区分是文字/非文字像素点
- 向量的direction,可以用来进行后处理帮助形成文本块
具体检测流程是:用一个VGG+FPN网络学习TextField的两张score map图,然后这两张图上做关于超像素、合并、形态学等后处理来得到text instance。
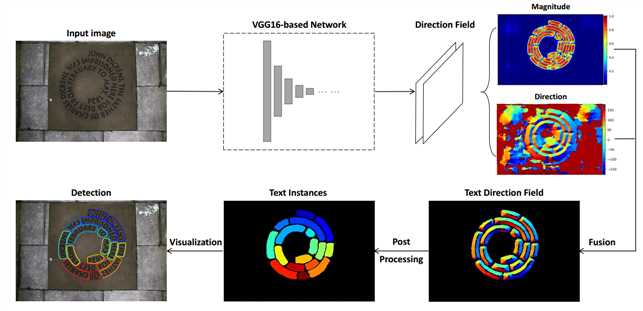
Fig. 3: Pipeline of the proposed method. Given an image, the network learns a novel direction field in terms of a two-channel map, which can be regarded as an image of two-dimensional vectors. To better show the predicted direction field, we calculate and visualize its magnitude and direction information. Text instances are then obtained based on these information via the proposed post-processing using some morphological tools.
方法细节
- Direction Field示例图
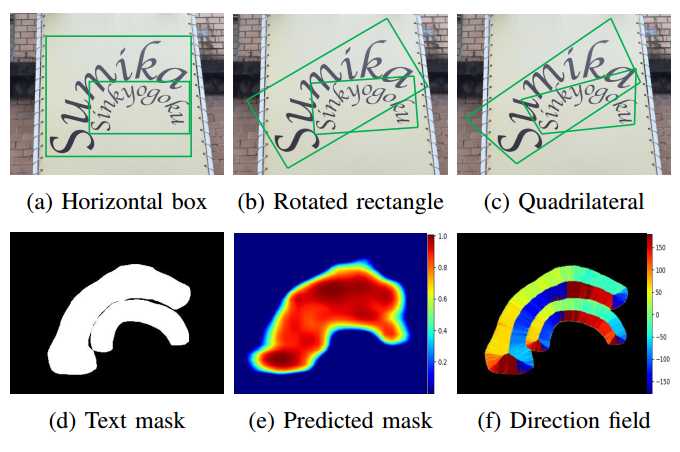
Fig. 1: Different text representations. Classical relatively simple text representations in (a-c) fail to accurately delimit irregular texts. The text instances in (e) stick together using binary text mask representation in (d), requiring heavy postprocessing to extract text instances. The proposed direction field in (f) is able to precisely describe irregular text instances.
网络结构
VGG16+FPN
Fig. 5: Network architecture. We adopt the pre-trained VGG16 [52] as the backbone network and multi-level feature fusion to capture multi-scale text instances. The network is trained to predict dense per-pixel direction field
- TextField向量定义
For each pixel p inside a text instance T , let Np be the nearest pixel to p lying outside the text instance T , we then define a two-dimensional unit vector Vgt(p) that points away from Np to the underlying text pixel p. This unit vector Vgt(p) directly encodes approximately relative location of p inside T and highlights the boundary between adjacent text instances.
where |NpP| denotes length of the vector starting from pixel Np to p, and T stands for all the text instances in an image. In practice, for each text pixel p, it is simple to compute its nearest pixel Np outside the text instance containing p by distance transform algorithm.
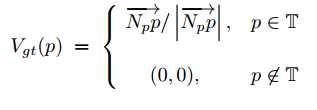
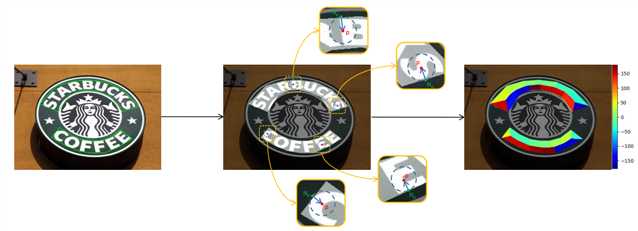
Fig. 4: Illustration of the proposed direction field. Given an image and its text annotation, a binary text mask can be easily generated. For each text pixel p, we find its nearest non-text pixel Np. Then, a two-dimensional unit vector that points away from N p to p is defined as the direction field on p. For non-text pixels, the direction field is set to (0;0). On the right, we visualize the direction information of the text direction field.
损失函数
欧式距离+带权(按text instance的面积)
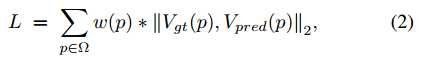
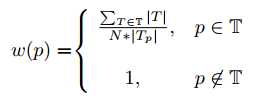
- 后处理流程
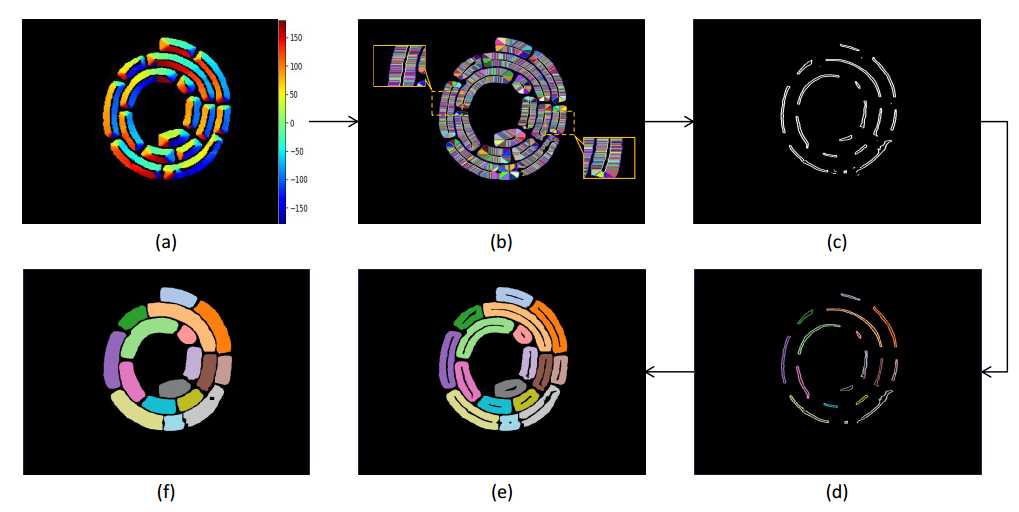
Fig. 6: Illustration of the proposed post-processing. (a): Directions on candidate text pixels; (b): Text superpixels (in different color) and their representatives (in white); (c): Dilated and grouped representatives of text superpixels; (d): Labels of filtered representatives; (e): Candidate text instances; (f) Final segmented text instances.

实验结果
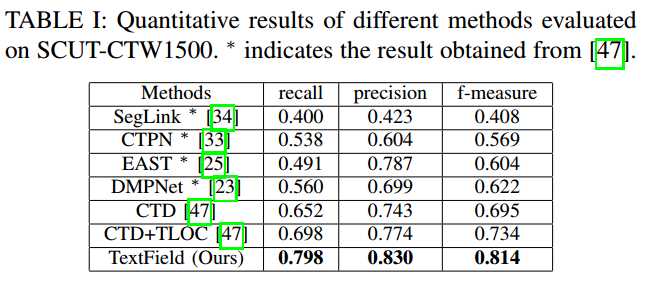
- SCUT-CTW1500
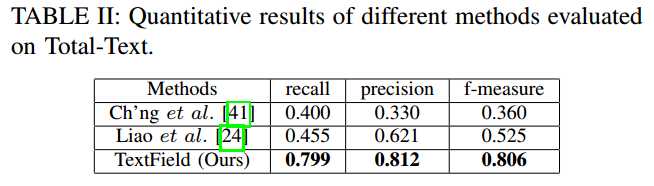
- Total-Text
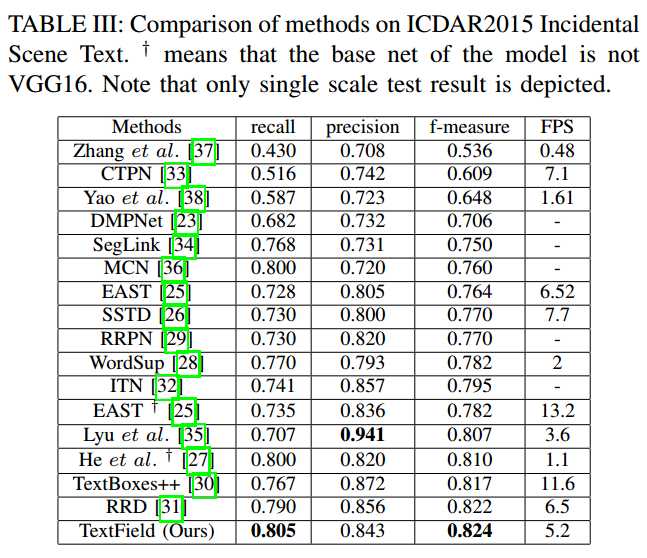
- ICDAR2015
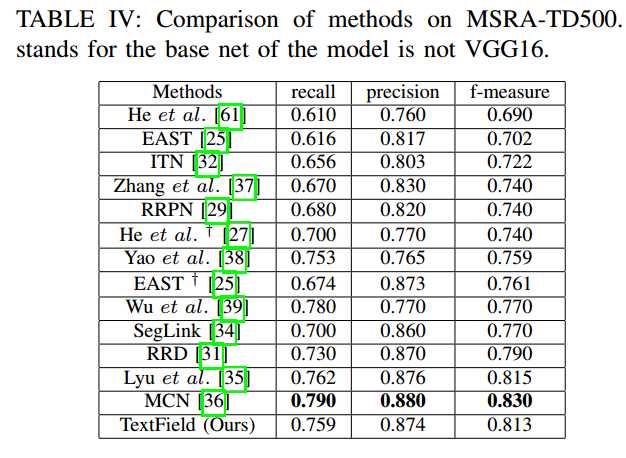
- MSRA-TD500
收获点与问题
- 没有说清楚的点:怎么算最近boundary点距离,还有后处理的那么多方法都没办法说清
- 方法非常新颖,但是,后处理太复杂了,速度上就占了1/4,向量表示方法也不太直观,不是特别通用的方法。
以上是关于论文速读(Yongchao Xu——2018TextField_Learning A Deep Direction Field for Irregular Scene Text)的主要内容,如果未能解决你的问题,请参考以下文章
[论文速读] StrokeGAN Reducing Mode Collapse in Chinese Font Generation via Stroke Encoding
《Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information》DRCN 论文速读(