(三十一)进程
Posted asia-yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(三十一)进程相关的知识,希望对你有一定的参考价值。
一、进程的其他方法
Process对象的其他方法或属性:name,pid,is_alive(),terminate().
from multiprocessing import Process,Queue import os import time # def f1(): # print(‘aaaalkalknflkanlnflalkam‘) # # def f2(): # print(111, os.getpid())#获取当前进程的id # print(222, os.getppid())#获取当前进程的父进程的id # print(‘bbb‘) # # if __name__ == ‘__main__‘: # p1 = Process(target=f1,name=‘hello‘)#给进程设置自己想要的名字name=’自己设置的进程名’ # p2 = Process(target=f2) # p1.start() # p2.start() # # print(p1.pid, p1.name)#获取进程对象的id和名字 # print(p2.pid, p2.name) # print(p1.is_alive())#查看进程是否还活跃 # p1.terminate()#向操作系统发布一个信号,让操作系统关闭进程,所以不会立马关闭,有个时间延迟,因此如果立马使用is_alive()查看,有可能还处于活跃状态 # time.sleep(0.1)#添加一旦延迟时间再去查看是否还活跃 # print(p1.is_alive())
二、僵尸进程和孤儿进程
1.僵尸进程(有害)
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。详解如下
我们知道在unix/linux中,正常情况下子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程到底什么时候结束,如果子进程一结束就立刻回收其全部资源,那么在父进程内将无法获取子进程的状态信息。
因此,UNⅨ提供了一种机制可以保证父进程可以在任意时刻获取子进程结束时的状态信息:
(1)在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)
(2)直到父进程通过wait / waitpid来取时才释放. 但这样就导致了问题,如果进程不调用wait / waitpid的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个子进程在结束时都要经过的阶段。如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是“Z”。如果父进程能及时 处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。 如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。
2.孤儿进程(无害)
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上。每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会出面处理它的一切善后工作,因此孤儿进程并不会有什么危害。
三、如何验证进程间是隔离的
看代码:
from multiprocessing import Process,Queue # a = 100 # def fn(): # global a # a = 200 # print(‘子进程中的a=‘,a) # if __name__ == ‘__main__‘: # p = Process(target=fn) # p.start() # p.join() # print(‘main-a=‘, a)
对代码做个解释:在当前主进程设置一个变量a = 100,假设如果在子进程中把a修改后,在主进程打印看一下,也是修改后的值,说明主进程和子进程没有隔离,相反的如果,在主进程打印的还是初始值,那么就可以说明,主进程和子进程是隔离开的,也就是进程间是隔离的。看下图:

为什么没有影响呢?因为在子进程创建的时候,把当前代码又复制了一份放进了自己所在的内存中,即便修改a的值,也只是修改的自己内存中值,二不会影响到主进程的里的a。
四、守护进程
上面说过的僵尸进程,对系统的内存是有害的,所以为了避免危害,可以在创建进程时,做一些操作,就是守护进程。守护进程,会跟随着,父进程的结束而结束。看代码:
# def fn(): # print(‘123456‘) # # if __name__ == ‘__main__‘: # p = Process(target=fn) # p.daemon = True#为进程对象的属性daemon设置为True # p.start() # print(‘789‘)
五、进程锁(同步锁/互斥锁)
通过刚刚的学习,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的运行没有顺序,一旦开启也不受我们控制。尽管并发编程让我们能更加充分的利用IO资源,但是也给我们带来了新的问题:进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理。
import os
import time
import random
from multiprocessing import Process
def work(n):
print(‘%s: %s is running‘ %(n,os.getpid()))
time.sleep(random.random())
print(‘%s:%s is done‘ %(n,os.getpid()))
if __name__ == ‘__main__‘:
for i in range(5):
p=Process(target=work,args=(i,))
p.start()
# 看结果:通过结果可以看出两个问题:问题一:每个进程中work函数的第一个打印就不是按照我们for循环的0-4的顺序来打印的
#问题二:我们发现,每个work进程中有两个打印,但是我们看到所有进程中第一个打印的顺序为0-2-1-4-3,但是第二个打印没有按照这个顺序,变成了2-1-0-3-4,说明我们一个进程中的程序的执行顺序都混乱了。
#问题的解决方法,第二个问题加锁来解决,第一个问题是没有办法解决的,因为进程开到了内核,有操作系统来决定进程的调度,我们自己控制不了
# 0: 9560 is running
# 2: 13824 is running
# 1: 7476 is running
# 4: 11296 is running
# 3: 14364 is running
# 2:13824 is done
# 1:7476 is done
# 0:9560 is done
# 3:14364 is done
# 4:11296 is done
再来看下面的代码,加了锁,并发变成了串行。牺牲了效果换来了安全。
#由并发变成了串行,牺牲了运行效率,但避免了竞争
from multiprocessing import Process,Lock
import os,time
def work(n,lock):
#加锁,保证每次只有一个进程在执行锁里面的程序,这一段程序对于所有写上这个锁的进程,大家都变成了串行
lock.acquire()
#加锁操作还可以使用,这种方式可以省略掉acquire()和release()两个方法
#with lock:
’’’需要加锁的代码’’’
print(‘%s: %s is running‘ %(n,os.getpid()))
time.sleep(1)
print(‘%s:%s is done‘ %(n,os.getpid()))
#解锁,解锁之后其他进程才能去执行自己的程序
lock.release()
if __name__ == ‘__main__‘:
lock=Lock()
for i in range(5):
p=Process(target=work,args=(i,lock))
p.start()
#打印结果:
# 2: 10968 is running
# 2:10968 is done
# 0: 7932 is running
# 0:7932 is done
# 4: 4404 is running
# 4:4404 is done
# 1: 12852 is running
# 1:12852 is done
# 3: 980 is running
# 3:980 is done
#结果分析:(自己去多次运行一下,看看结果,我拿出其中一个结果来看)通过结果我们可以看出,多进程刚开始去执行的时候,每次运行,首先打印出来哪个进程的程序是不固定的,但是我们解决了上面打印混乱示例代码的第二个问题,那就是同一个进程中的两次打印都是先完成的,然后才切换到下一个进程去,打印下一个进程中的两个打印结果,说明我们控制住了同一进程中的代码执行顺序,如果涉及到多个进程去操作同一个数据或者文件的时候,就不担心数据算错或者文件中的内容写入混乱了。
六、生产者和消费者模型
- 第一种方式,看下面代码
def producer(q):
for i in range(10):
time.sleep(0.5)
s = ‘大包子:‘+str(i)+‘号‘
print(‘大厨在做的包子是-->>>‘, s)
q.put(s)
q.put(100)#在这里做一个标志
def consumer(q):
while 1:
s = q.get()
time.sleep(1)
if s == 100:#当拿到了100时,代表里面的值都拿完了,所以可以跳出循环结束程序了
print(‘包子吃完了‘)
break
print(‘客官吃的包子是-->>>‘, s, q.qsize())
if __name__ == ‘__main__‘:
q = Queue(11)
p = Process(target=producer, args=(q,))
c = Process(target=consumer, args=(q,))
p.start()
c.start()
上面代码使用了一个multiprocessing模块中的Queue,这也是队列。看代码:
# from multiprocessing import Queue
# q = Queue(3)
# q.put(1)
# q.put(2)
# q.put(3)
# # q.put(4)
# # q.put_nowait(4)#如果前面已经放满了,这时再放就会报错,不像put()一样阻塞在这里不动
#print(q.full())#判断队列是否已满,多进程同时处理时,会不准确
# print(q.get())
# print(q.get())
# print(q.get())
# # print(q.get_nowait())#如果前面已经把队列取空了,那么这时就会报错,不像get()一样阻塞住不动
#print(q.empty())#判断队列是否为空,与q.full()类似有些不准确
# print(‘asd‘)
2.第二种方式,看下面的代码
def producer(q):
for i in range(10):
time.sleep(0.4)
s = ‘包子%s号‘%i
print(‘生产了‘ + s)
q.put(s)
q.join()
def consumer(q):
while 1:
s = q.get()
time.sleep(0.2)
print(‘客人吃了‘ + s)
q.task_done()
if __name__ == ‘__main__‘:
q = JoinableQueue(10)
pro_p = Process(target=producer,args=(q,))
con_p = Process(target=consumer, args=(q,))
con_p.daemon = True
pro_p.start()
con_p.start()
#让主线程等待生产者执行完毕后再执行
pro_p.join()
print(‘主进程走完了‘)
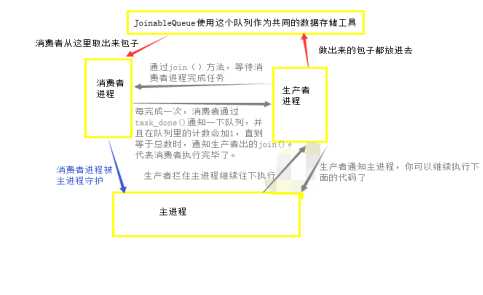
这种方式有点绕:首先,把消费者设置成主进程的守护进程;接着,生产者拦住了主进程不让他继续往下走了。生产者去做包子,做出一个时,消费者就可以开吃了。这时,task_done()会向队列中发送一个信号,这一次任务完成了,队列中会计数,当完成次数正好等于队列中元素的个数时,代表所有的元素都被取出来了。然后,就会执行JoinableQueue的join()方法,通知生产者进程任务完成了,做完了,也吃完了。然后,生产者进程执行的join()也不再等待,继续向下执行。这时,主进程就开始执行了,主进程执行的速度很快,瞬间完成,而被主进程守护的消费者进程也会被关闭。这样就完成了,整个过程。看张图:
以上是关于(三十一)进程的主要内容,如果未能解决你的问题,请参考以下文章
Linux CFS调度器之唤醒WAKE_AFFINE 机制--Linux进程的管理与调度(三十一)