服务发现之三分天下
Posted lufeiludaima
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务发现之三分天下相关的知识,希望对你有一定的参考价值。
服务发现之来源
在云计算和容器化技术发展火热的当下,微服务的趋势逐渐流行。那什么是微服务架构?简单来说,微服务就是用一组小服务的方式来构建一个应用,服务独立运行在不同的进程中,服务之间通过轻量的通讯机制(如 RESTful 接口)来交互,并且服务可以通过自动化部署方式独立部署。
从定义中不难理解,微服务架构其实也就意味着更多的独立服务,并且这些服务之间需要频繁交互和通信。通讯可以使用 RESTful 的方式,但通讯之前服务和服务之间是如何知道彼此的地址的(类比打电话)?这个时候就需要引入服务发现的概念。简单来说,服务发现就是服务或者应用之间互相定位的过程,它也并不是什么新鲜的概念。对于微服务架构,服务注册与发现组件是必不可少的。在传统的服务架构中,服务的规模处于运维人员的可控范围内。当部署服务的多个节点时,一般使用静态配置的方式实现服务信息的设定。在微服务应用中,服务实例的数量和网络地址都是动态变化的,这对系统运维提出了巨大的挑战。因此,动态的服务注册与发现就显得尤为重要。
服务发现之作用
在一个分布式系统中,服务注册与发现组件主要解决两个问题:服务注册和服务发现。
- 服务注册:服务实例将自身服务信息注册到注册中心。这部分服务信息包括服务所在主机IP和提供服务的Port,以及暴露服务自身状态以及访问协议等信息。
- 服务发现:服务实例请求注册中心获取所依赖服务信息。服务实例通过注册中心,获取到注册到其中的服务实例的信息,通过这些信息去请求它们提供的服务。
除此之外,服务注册与发现需要关注监控服务实例运行状态、负载均衡等问题。
- 监控:微服务应用中,服务处于动态变化的情况,需要一定机制处理无效的服务实例。一般来讲,服务实例与注册中心在注册后通过心跳的方式维系联系,一旦心跳缺少,对应的服务实例会被注册中心剔除。
- 负载均衡:同一服务可能同时存在多个实例,需要正确处理对该服务的负载均衡。
大数据之CAP原则
CAP原则,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性),不能同时成立。
- 一致性:它要求在同一时刻点,分布式系统中的所有数据备份都处于同一状态。
- 可用性:在系统集群的一部分节点宕机后,系统依然能够响应用户的请求。
- 分区容错性:在网络区间通信出现失败,系统能够容忍。
一般来讲,基于网络的不稳定性,分布容错是不可避免的,所以我们默认CAP中的P总是成立的。
一致性的强制数据统一要求,必然会导致在更新数据时部分节点处于被锁定状态,此时不可对外提供服务,影响了服务的可用性,反之亦然。因此一致性和可用性不能同时满足。
我们接下来介绍的服务注册和发现组件中,Eureka满足了其中的AP,Consul和Zookeeper满足了其中的CP。
服务发现之Eureka,Consul,Zookeeper三分天下
Eureka原理
Eureka是在Java语言上,基于Restful Api开发的服务注册与发现组件,由Netflix开源。遗憾的是,目前Eureka仅开源到1.X版本,2.X版本已经宣布闭源。Eureka采用的是Server/Client的模式进行设计。Server扮演了服务注册中心的角色,为Client提供服务注册和发现的功能,维护着注册到自身的Client的相关信息,同时提供接口给Client获取到注册表中其他服务的信息。Client将有关自己的服务的信息通过一定的方式登记到Server上,并在正常范围内维护自己信息的一致性,方便其他服务发现自己,同时可以通过Server获取到自己的依赖的其他服务信息,从而完成服务调用。
它的架构图如下所示: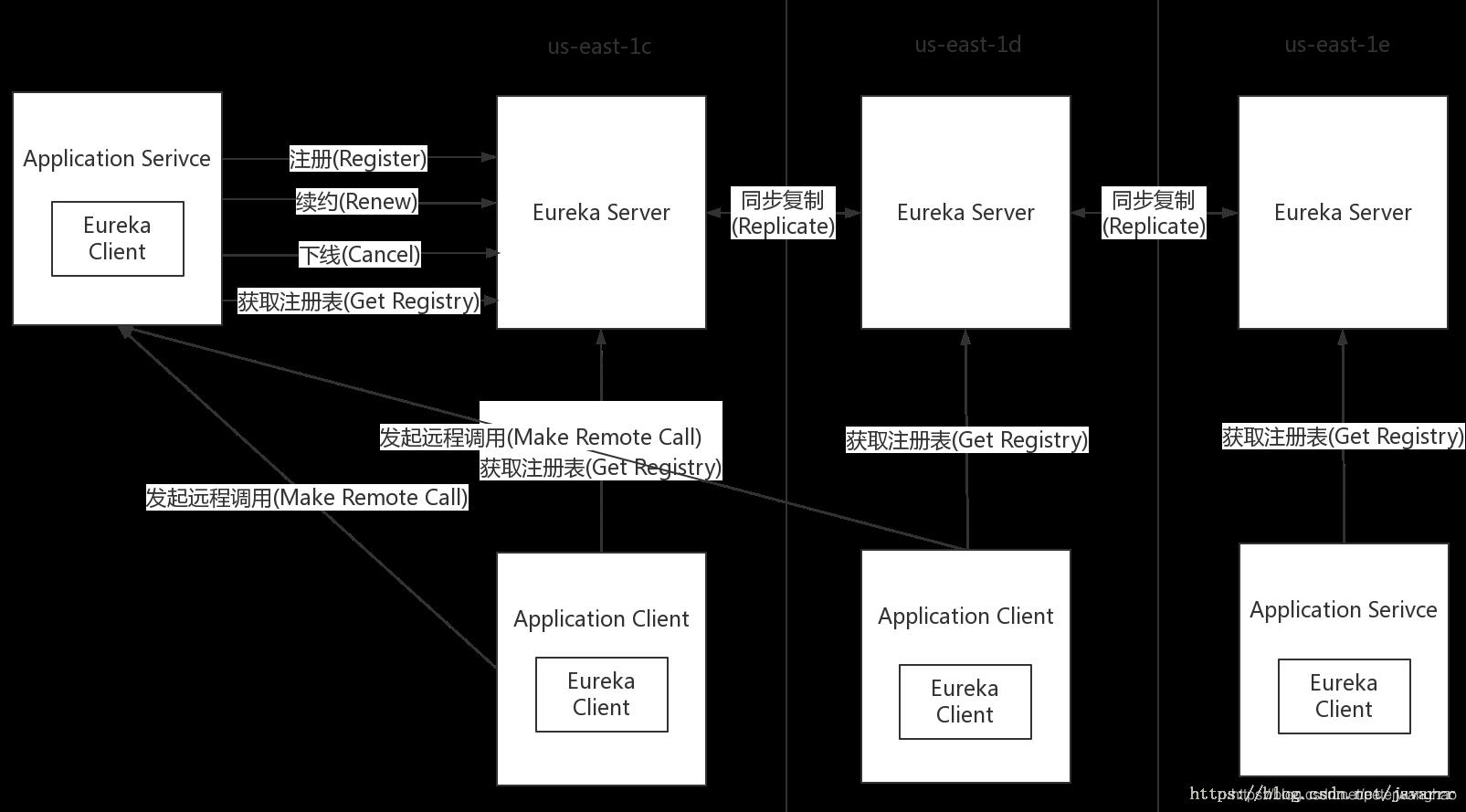
- Application Service: 作为Eureka Client,扮演了服务的提供者,提供业务服务,向Eureka Server注册和更新自己的信息,同时能从Eureka Server的注册表中获取到其他服务的信息。
- Eureka Server:扮演服务注册中心的角色,提供服务注册和发现的功能,每个Eureka Cient向Eureka Server注册自己的信息,也可以通过Eureka Server获取到其他服务的信息达到发现和调用其他服务的目的。
- Application Client:作为Eureka Client,扮演了服务消费者,通过Eureka Server获取到注册到上面的其他服务的信息,从而根据信息找到所需的服务发起远程调用。
- Replicate: Eureka Server中的注册表信息的同步拷贝,保持不同的Eureka Server集群中的注册表中的服务实例信息的一致性。提供了数据的最终一致性。
- Make Remote Call: 服务之间的远程调用。
- Register: 注册服务实例,Client端向Server端注册自身的元数据以进行服务发现。
- Renew:续约,通过发送心跳到Server维持和更新注册表中的服务实例元数据的有效性。当在一定时长内Server没有收到Client的心跳信息,将默认服务下线,将服务实例的信息从注册表中删除。
- Cancel:服务下线,Client在关闭时主动向Server注销服务实例元数据,这时Client的的服务实例数据将从Server的注册表中删除。
Eureka中没有使用任何的数据强一致性算法保证不同集群间的Server的数据一致,仅通过数据拷贝的方式争取注册中心数据的最终一致性,虽然放弃数据强一致性但是换来了Server的可用性,降低了注册的代价,提高了集群运行的健壮性。
Consul原理
Consul是由HashiCorp基于Go语言开发的支持多数据中心分布式高可用的服务发布和注册服务软件,采用Raft算法保证服务的一致性,且支持健康检查。Consul采用主从模式的设计,使得集群的数量可以大规模扩展,集群间通过RPC的方式调用(HTTP和DNS)。它的结构图如下所示:
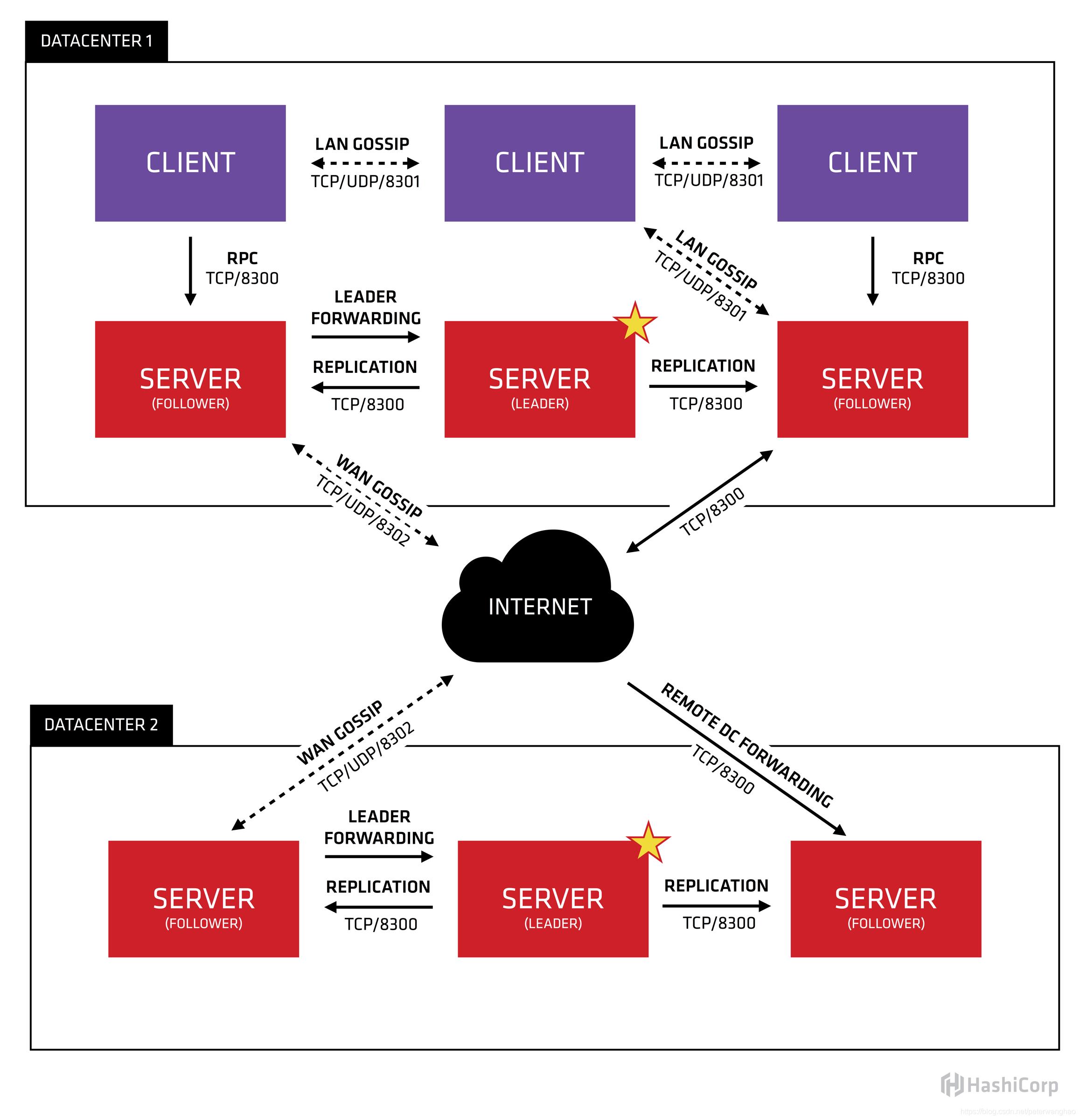
- Client:作为一个代理(非微服务实例),它将转发所有的RPC请求到Server中。作为相对无状态的服务,它不持有任何注册信息。
- Server:作为一个具备扩展功能的代理,它将响应RPC查询、参与Raft选举、维护集群状态和转发查询给Leader等。
- Leader-Server:一个数据中心的所有Server都作为Raft节点集合的一部分。其中Leader将负责所有的查询和事务(如服务注册),同时这些事务也会被复制到所有其他的节点。
- Data Center:数据中心作为一个私有的,低延迟和高带宽的一个网络环境。每个数据中心会存在Consul集群,一般建议Server是3-5台(考虑到Raft算法在可用性和性能上取舍),而Leader只能唯一,Client的数量没有限制,可以轻松扩展。
Raft算法
Raft算法将Server分为三种类型:Leader、Follower和Candidate。Leader处理所有的查询和事务,并向Follower同步事务。Follower会将所有的RPC查询和事务转发给Leader处理,它仅从Leader接受事务的同步。数据的一致性以Leader中的数据为准实现。
在节点初始启动时,节点的Raft状态机将处于Follower状态等待来来自Leader节点的心跳。如果在一定时间周期内没有收到Leader节点的心跳,节点将发起选举。
Follower节点选举时会将自己的状态切换为Candidate,然后向集群中其它Follower节点发送请求,询问其是否选举自己成为Leader。当收到来自集群中过半数节点的接受投票后,节点即成为Leader,开始接收Client的事务处理和查询并向其它的Follower节点同步事务。Leader节点会定时向Follower发送心跳来保持其地位。
Gossip协议
Gossip协议是为了解决分布式环境下监控和事件通知的瓶颈。Gossip协议中的每个Agent会利用Gossip协议互相检查在线状态,分担了服务器节点的心跳压力,通过Gossip广播的方式发送消息。
所有的Agent都运行着Gossip协议。服务器节点和普通Agent都会加入这个Gossip集群,收发Gossip消息。每隔一段时间,每个节点都会随机选择几个节点发送Gossip消息,其他节点会再次随机选择其他几个节点接力发送消息。这样一段时间过后,整个集群都能收到这条消息。
基于Raft算法,Consul提供强一致性的注册中心服务,但是由于Leader节点承担了所有的处理工作,势必加大了注册和发现的代价,降低了服务的可用性。通过Gossip协议,Consul可以很好地监控Consul集群的运行,同时可以方便通知各类事件,如Leader选择发生、Server地址变更等。
Zookeeper原理
Zookeeper是由Google开源的在Java语言上实现的分布式协调服务,是Hadoop和Hbase的重要组件,提供了数据/发布订阅、负载均衡、分布式同步等功能。Zookeeper也是基于主从架构,搭建了一个可高扩展的服务集群,其服务架构如下:
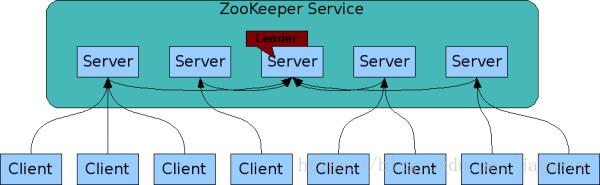
- Leader-Server:Leader负责进行投票的发起和决议,更新系统中的数据状态
- Server:Server中存在两种类型:Follower和Observer。其中Follower接受客户端的请求并返回结果(事务请求将转发给Leader处理),并在选举过程中参与投票;Observer与Follower功能一致,但是不参与投票过程,它的存在是为了提高系统的读取速度
- Client:请求发起方,Server和Client之间可以通过长连接的方式进行交互。如发起注册或者请求集群信息等。
Zab协议
ZooKeeper Atomic Broadcast protocol是专门设计给Zookeeper用于实现分布式系统数据的一致性,是在Paxos算法基础上发展而来。它使用了单一的Leader来接受和处理客户端的所有事务请求,并将服务器数据的状态变更以事务Proposal的形式广播到所有的Server中。同时它保证Leader出现异常时,集群依旧能够正常工作。Zab包含两种基本模式:崩溃恢复和消息广播。
- 崩溃恢复:Leader服务器出现宕机,或者因为网络原因导致Leader服务器失去了与过半 Follower的联系,那么就会进入崩溃恢复模式从而选举新的Leader。Leader选举算法不仅仅需要让Leader自己知道其自身已经被选举为Leader,同时还需要让集群中的所有其他服务器也能够快速地感知到选举产生的新的Leader。当选举产生了新的Leader,同时集群中有过半的服务器与该Leader完成了状态同步之后,Zab协议就会退出崩溃恢复模式,进入消息广播模式。
- 消息广播:Zab协议的消息广播过程类似二阶段提供过程,是一种原子广播的协议。当接受到来自Client的事务请求(如服务注册)(所有的事务请求都会转发给Leader),Leader会为事务生成对应的Proposal,并为其分配一个全局唯一的ZXID。Leader服务器与每个Follower之间都有一个单独的队列进行收发消息,Leader将生成的Proposal发送到队列中。Follower从队列中取出Proposal进行事务消费,消费完毕后发送一个ACK给Leader。当Leader接受到半数以上的Follower发送的ACK投票,它将发送Commit给所有Follower通知其对事务进行提交,Leader本身也会提交事务,并返回给处理成功给对应的客户端。Follower只有将队列中Proposal都同步消费后才可用。
基于Zab协议,Zookeeper可以用于构建具备数据强一致性的服务注册与发现中心,而与此相对地牺牲了服务的可用性和提高了注册需要的时间。
三分天下之异同点
最后我们通过一张表格大致了解Eureka、Consul、Zookeeper的异同点。选择什么类型的服务注册与发现组件可以根据自身项目要求决定。
| 组件名 | 语言 | CAP | 一致性算法 | 服务健康检查 | 对外暴露接口 | Spring Cloud集成 |
|---|---|---|---|---|---|---|
| Eureka | Java | AP | 无 | 可配支持 | HTTP | 已集成 |
| Consul | Go | CP | Raft | 支持 | HTTP/DNS | 已集成 |
| Zookeeper | Java | CP | Paxos | 支持 | 客户端 | 已集成 |

以上是关于服务发现之三分天下的主要内容,如果未能解决你的问题,请参考以下文章