重学SpringCloud系列三之服务注册与发现---下
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重学SpringCloud系列三之服务注册与发现---下相关的知识,希望对你有一定的参考价值。
重学SpringCloud系列三之服务注册与发现---下
- 白话服务注册与发现
- DiscoveryClient服务发现
- Eureka集群环境构建(linux)
- Eureka集群多网卡环境ip设置
- Eureka集群服务注册与安全认证
- Eureka自我保护与健康检查
- 主流服务注册中心对比(含nacos)
- zookeeper概念及功能简介
- zookeeper-linux集群安装
- zookeeper服务注册与发现
- consul概念及功能介绍
- consul-linux集群安装
- consul服务注册与发现
- 通用-auatator导致401问题
白话服务注册与发现
公益图书馆例子
笔者不想直接用专业的术语来说明“微服务注册与发现”,所以我们来看生活中的一个案例:“公益图书馆”。
随着人们生活水平的不断提高,追求精神食粮的朋友也越来越多。笔者曾经在一些城市看见过公益图书馆,其运行逻辑是:一些公益组织和个人提供一块场所,然后由组织内的人向图书馆内捐书。捐出的书越多,一段时间内能够借阅的书也就越多。这种做法有助于大家分享图书、节约资金、交流读书心得。那我们来看一下几个关键环节:
- 捐书:组织内的人向公益图书馆捐书,是不是直接将书放到书架上就完事了呢?当然不是,是先向图书管理系统记录一下捐书的人、书名、捐书的时间等信息,再将书放到书架上。
- 借书:借书的人通常是通过图书管理系统的一个小程序查询图书,然后取书,全靠自觉。图书可能存在多个副本(多人捐的同一种书),借书的人会根据书籍状态择优选择。
- 这其中非常重要的一个角色就是图书管理系统,为大家捐书、借书提供了数据支持和集中管理功能。
- 兼职图书管理员定期维护图书,将破损图书从图书管理系统中下架维护。
其实上面的这个“公益图书馆的例子”就是典型的服务注册与发现:
- 每一本图书就是一个服务,捐书的过程就是“服务注册”的过程。
- 借书的查询图书的过程就是“服务发现”的过程。
- 其中最重要的角色:图书管理系统及管理员,就是服务注册中心或者服务注册平台。
- 捐书者可能同时是借书者。进行服务注册的微服务节点,同时可能也使用服务发现机制发现其他微服务。
- 捐书是主动行为,不是被动行为。这和微服务的注册是一样的,微服务必须在启动的时候向服务注册组件进行主动注册。这样做的目的就是降低数据维护成本,不需要专人维护注册数据。
- 图书下架是被动的,不是主动的,不是捐书的人将其下架。微服务也是一样,当服务出现故障发生问题,服务发现注册组件应具备将服务下线的能力。
- 图书管理员可以检查图书并下架,这过程在服务注册与发现中被称为:健康检查
- 对于同一种图书可能存在多个同样的副本,由使用者择优选择借哪一本书。对于服务发现获得的结果:同一种服务的多个副本的情况,由服务调用者择优决定使用哪一个服务副本。这种服务方式比较专业的说法是:客户端负载均衡。
与客户端负载均衡相对的方法就是服务端负载均衡,如果上面的例子中借书过程一本书有多个副本,由图书管理员或系统决定借书者借其中的哪一个副本,这个就是服务端负载均衡。如:nginx、haproxy等就是服务端负载均衡。
服务注册与发现
- 服务注册 -服务在中央注册表中注册其服务位置的过程。通常注册其主机和端口,有时还注册认证凭证,协议,版本号和或环境信息。
- 服务发现 -客户端应用程序查询中央注册表以了解服务位置的过程。
- 维护中央注册表的角色被称为服务注册平台或者服务注册中心
服务注册
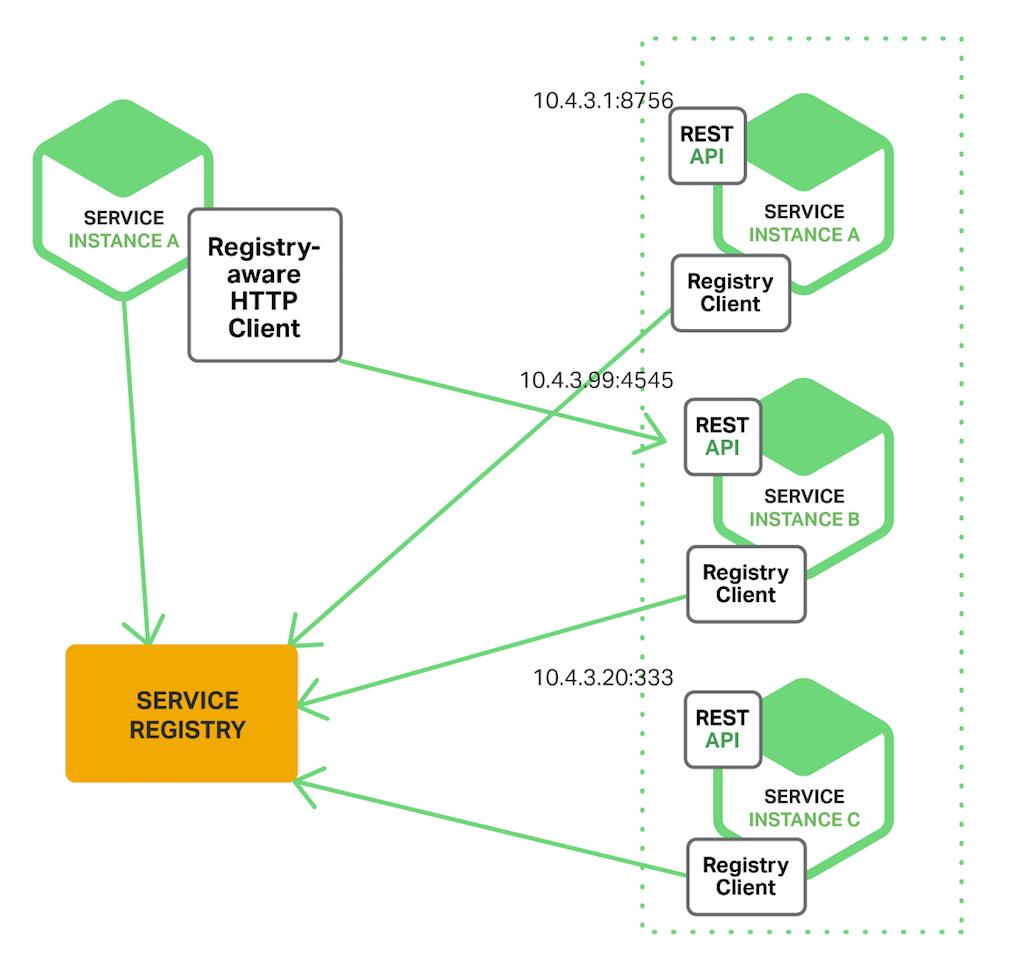
当一个微服务启动的时候,必须主动向服务注册中心注册其服务地址,以供其他微服务查询调用。图中橘黄色为服务注册中心,绿色为微服务节点。

客户端负载均衡
- 当一个微服务有多个实例的时候,由调用者从服务注册中心获取注册服务列表
- 调用者拿到"注册服务列表"之后,决定访问哪一个服务实例。
Spring Cloud常用的服务注册中心
- Eureka:Spring Cloud的大儿子,出生的时候条件一般,长大后素质有限
- Nacos:后起之秀,曾经Spring Cloud眼中“别人家的孩子”,已经纳入收养范围(孵化项目)。
- Apache Zookeeper:关系户,与hadoop关系比较好
- Consul:关系户,曾经与docker关系比较好
- etcd:关系户,与kubernetes关系比较好
如果你的应用已经使用到了hadoop、kubernetes、docker,在Spring Cloud实施过程中可以考虑使用其关系户组件,避免搭建两套注册中心,节省资源。但是二者兼容使用说说容易,真正用起来还需要功夫。目前看,笔者觉得最佳选择应该是Nacos。
这里可以先简单的了解一下常见的这些服务注册中心,后面的章节我们会逐步的详细介绍。
DiscoveryClient服务发现

在前面的章节,我们已经为大家介绍了
- 服务注册的方式,在服务启动的时候主动向服务注册中心注册服务信息
- 服务消费者可以以负载均衡的方式,远程调用服务提供者提供的服务。
服务消费者调用微服务之前,需要向服务注册中心,获取注册服务列表及服务信息。这个过程就是“服务发现”,那么服务发现是通过什么类实现的?服务列表及服务信息又包含哪些内容?本节就带着大家来解开这样的疑惑!
DiscoveryClient测试用例
DiscoveryClient 代表的就是:服务发现操作对象。
public interface DiscoveryClient extends Ordered
int DEFAULT_ORDER = 0;
String description();
List<ServiceInstance> getInstances(String serviceId);
List<String> getServices();
default int getOrder()
return 0;
它有两个核心方法:
- getServices获取在服务注册中心,注册的所有服务的id。比如:ASERVICE-RBAC、ASERVICE-SMS。
- getInstances根据服务id,获取该服务的所有启动实例的注册信息。即:一个微服务的多个副本的注册信息。
下面是一个基于Spring、Junit的测试用例,使用上面两个方法来实现服务发现。
@ExtendWith(SpringExtension.class)
@SpringBootTest
public class DiscoveryClientTest
@Resource
private DiscoveryClient discoveryClient; // 进行eureka的发现服务
@Test
void discoveryClientTest()
//获取服务Id
List<String> services = discoveryClient.getServices();
services.forEach(System.out::println);
//获取每个服务的多个启动实例的注册信息。
for (String service:services)
discoveryClient.getInstances(service)
.forEach(s ->
System.out.println("InstanceId=" + s.getHost() + ":" + s.getPort());
System.out.println("Host:Port="+ s.getHost() + ":" + s.getPort());
System.out.println("Uri=" + s.getUri());
System.out.println("InstanceId=" + s.getInstanceId());
System.out.println("Schema=" + s.getScheme());
System.out.println("ServiceId=" + s.getServiceId());
System.out.println("Metadata="+ s.getMetadata());
);
结合测试结果的打印,可以更清楚的知道服务注册及发现相关的信息。理解DiscoveryClient 及其方法的作用。控制台打印结果如下:
两种服务发现注解的区别
在Spring Cloud中实现服务发现可以使用两种注解:@EnableDiscoveryClient和@EnableEurekaClient,两者的用法基本上是一样的。但存在区别,简单地说:
- 如果服务注册中心是eureka,就需要在服务启动类加上
@EnableEurekaClient注解,实现服务发现。 - 如果是其他的注册中心,那么更推荐使用
@EnableDiscoveryClient,该注解更加的通用。
在Hello-microservice章节,实现微服务向服务注册中心注册的时候,我们使用了@EnableEurekaClient,是因为我们当时搭建的服务注册中心是基于eureka搭建的。Spring Cloud中还有很多的其他服务注册中心的选项,比如:consul、zookeeper、nacos,这时就不能使用@EnableEurekaClient注解了,需要使用@EnableDiscoveryClient注解。
Eureka集群环境构建(linux)
服务注册中心在整个微服务体系中,至关重要!如果服务注册中心挂了,整个系统都将崩溃。所以服务注册中心通常不会被部署为单点应用,而是采用集群的部署方式,其中个别节点挂掉不影响整个系统的运行。

下面,我们就来为大家介绍,如何基于CentOS7服务器构建eureka服务注册中心。
CentOS7(linux)环境准备
| 主机名称 | 主机ip |
|---|---|
| peer1 | 192.168.161.3 |
| peer2 | 192.168.161.4 |
| peer3 | 192.168.161.5 |
并且在安装eureka服务注册中心之间,需要将服务器时间同步,不能相差太多,否则eureka服务有可能启动失败。可以使用ntp进行时间同步。如:
ntpdate ntp.api.bz
profile配置文件修改

application-peer1.yml
- hostname为peer1
- defaultZone为peer2和peer3
- 下面配置我们之所以重写了health-check-url(健康检查路径),是因为设置了context-path。默认的健康检查路径是以“/”为项目的context-path。所以我们需要修改为server.servlet.context-path配置的值。
- 因为我们设置了context-path,所以defaultZone访问端点有两个eureka,第一个eureka是我们配置的context-path。如果不设置context-path,defaultZone:http://peer2:8761/eureka/,http://peer3:8761/eureka/
- 在eureka集群搭建过程中,fetch-registry和register-with-eureka一定设置为true。
这两个值之所以设置为true,目的是让eureka集群之间实现互相注册,互相心跳健康状态,从而达到集群的高可用。
#是否从其他实例获取服务注册信息,因为这是一个单节点的EurekaServer,不需要同步其他的EurekaServer节点的数据,所以设置为false;
fetch-registry: false
#表示是否向eureka注册服务,即在自己的eureka中注册自己,默认为true,此处应该设置为false;
register-with-eureka: false
把它们设置为false,是能解决你可能遇到的一些集群环境问题。这就好比你腿疼,你把腿砍了是不疼了,但你还能走路么。我们要的是让腿不疼,而不是把腿砍掉。“把腿砍了”这就不是“高可用”集群了,相当于你搭建了多个eureka server单点,这是“掩耳盗铃”的做法。
server:
port: 8761
servlet:
context-path: /eureka
spring:
application:
name: eureka-server
eureka:
instance:
hostname: peer1
health-check-url: http://$eureka.instance.hostname:$server.port/$server.servlet.context-path/actuator/health
client:
#从其他两个实例同步服务注册信息
fetch-registry: true
#向其他的两个eureka注册当前eureka实例
register-with-eureka: true
service-url:
defaultZone: http://peer2:8761/eureka/eureka/,http://peer3:8761/eureka/eureka/
application-peer2.yml
- hostname为peer2
- defaultZone为peer1和peer3
server:
port: 8761
servlet:
context-path: /eureka
spring:
application:
name: eureka-server
eureka:
instance:
hostname: peer2
health-check-url: http://$eureka.instance.hostname:$server.port/$server.servlet.context-path/actuator/health
client:
#从其他两个实例同步服务注册信息
fetch-registry: true
#向其他的两个eureka注册当前eureka实例
register-with-eureka: true
service-url:
defaultZone: http://peer1:8761/eureka/eureka/,http://peer3:8761/eureka/eureka/
application-peer3.yml
- hostname为peer3
- defaultZone为peer1和peer2
server:
port: 8761
servlet:
context-path: /eureka
spring:
application:
name: eureka-server
eureka:
instance:
hostname: peer3
health-check-url: http://$eureka.instance.hostname:$server.port/$server.servlet.context-path/actuator/health
client:
#从其他两个实例同步服务注册信息
fetch-registry: true
#向其他的两个eureka注册当前eureka实例
register-with-eureka: true
service-url:
defaultZone: http://peer1:8761/eureka/eureka/,http://peer2:8761/eureka/eureka/
为eureka server加入actuator
spring-boot-starter-actuator是为Spring Boot服务提供相关监控信息的包。因为我们的eureka server要互相注册,并检查彼此的健康状态,所以这个包必须带上。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
CentOS7环境下部署eureka集群
如果你的网络环境内没有DNS,需要配置/etc/hosts文件,将主机名称与ip地址关联。这一步必须要做,否则linux主机之间通过hostname访问eureka服务将无效,每台eureka server主机上都要执行。
192.168.161.3 peer1
192.168.161.4 peer2
192.168.161.5 peer3
开放防火墙端口(CentOS7),每台eureka server主机上都要执行。
firewall-cmd --zone=public --add-port=8761/tcp --permanent
firewall-cmd --reload
- 第一条命令式在防火墙开放8761端口
- 第二条命令是是开放端口重新加载,使生效
将dhy-server-eureka通过maven打包,然后上传CentOS主机,启动Eureka服务注册中心集群
# 在peer1主机执行
nohup java -jar -Dspring.profiles.active=peer1 dhy-server-eureka-1.0.jar &
# 在peer2主机执行
nohup java -jar -Dspring.profiles.active=peer2 dhy-server-eureka-1.0.jar &
# 在peer3主机执行
nohup java -jar -Dspring.profiles.active=peer3 dhy-server-eureka-1.0.jar &
访问测试
访问http://192.168.161.3:8761/eureka/,即:访问peer1的eureka服务。可以见到DS Replicas中已经注册了peer3、peer2。

同理:
- 访问http://192.168.161.4:8761/eureka/,即:访问peer2的eureka服务。可以见到DS Replicas中已经注册了peer1、peer3。
- 访问http://192.168.161.5:8761/eureka/,即:访问peer3的eureka服务。可以见到DS Replicas中已经注册了peer1、peer2。
出现上面的这种eureka server之间互相注册的效果,表示我们的eureka服务注册中心集群模式搭建成功了!那么恭喜你,你是一个幸运儿。在实际的生产环境中,网络及主机环境往往更复杂,搭建过程的参数调整也更加复杂。
其他需要注意的点:
出现 unavailable-replicas 问题,首先要去检查一下你的health-check-url是否能正常响应。如果没有设置context-path,默认是:http://ip:端口/actuator/health。UP状态表示处于可用状态。

如果健康检查没有问题:
1.是否开启了register-with-eureka=true和fetch-registry=true
2.eureka.client.serviceUrl.defaultZone配置项的地址,不能使用localhost,要使用ip或域名。或者可以通过hosts或者DNS解析的主机名称hostname。
3.spring.application.name要一致,不配置也可以,配置了要一致
4.默认情况下,Eureka 使用 hostname(如:peer1、peer2、peer3) 进行服务注册,以及服务信息的显示(eureka web 页面),那如果我们希望使用 IP 地址的方式,该如何配置呢?答案就是eureka.instance.prefer-ip-address=true。当设置prefer-ip-address: true时 ,修改配置defaultZone:http://你的IP:9001/eureka/。如果此时你仍然使用http://peer1:8761/eureka会导致健康检查失败。
Eureka集群多网卡环境ip设置
在上一小节,我们为大家讲解了如何在linux环境下搭建集群式Eureka服务注册中心。有的朋友可能会遇到下面的问题(导致服务注册失败、健康检查失败):

上图中蓝色部分:大家可以明确的看到eureka server的服务绑定的ip是10.0.2.15?这是为什么?我们上一节中,也没有使用过这个ip啊,我们使用的是192.168.161.3。这是因为我的CentOS服务器上有多个网卡,还有一些docker相关的虚拟网卡。“多网卡”在生产环境上是非常常见的情况。怎么让eureka server服务绑定实例我们期望它绑定的网卡?
配置实现
首先来看一下,我的服务器(虚拟机)上面的网卡设备,一共五个(虚拟的)。
- docker0虚拟网卡是因为我在这台机器上安装了docker
- enp0s3网卡是一个NAT网络的网卡,虚拟机上常用。大家注意它的ip是10.0.2.15。
- enp0s8才是我们真正需要使用的本地网络。

那我们现在要做的就是通知spring cloud,我们部署的微服务希望ip是192.168的本地网段。不要使用docker0和enp0s3的网段。
-
spring.cloud.inetutils.preferredNetworks表示我们期望使用的网段,可以使用正则表达式 -
spring.cloud.inetutils.ignoredInterfaces表示我们希望忽略掉的网卡设备。 - 另外我们重新配置了
eureka.instance.instance-id。这个问题比较特殊,spring cloud在组成instance-id规则的时候,并没有遵守我们的preferredNetworks和ignoredInterfaces约定(有可能是版本问题,没准下一个版本就好了)。所以我们不要在instance-id使用ip(因为enp0s3虚拟机桥接网卡的ip在所有的虚拟机上都是10.0.2.15),这导致所有eureka server的instance-id全一样,所以只能注册成功其中一个。
server:
port: 8761
servlet:
context-path: /eureka
spring:
application:
name: eureka-server
cloud:
inetutils:
preferredNetworks:
- 192.168
ignoredInterfaces:
- enp0s3
- docker0
eureka:
instance:
hostname: peer1
instance-id: $spring.application.name-$eureka.instance.hostname:$server.port
health-check-url: http://$eureka.instance.hostname:$server.port/$server.servlet.context-path/actuator/health
client:
#从其他两个实例同步服务注册信息
fetch-registry: true
#向其他的两个eureka注册当前eureka实例
register-with-eureka: true
service-url:
defaultZone: http://peer2:8761/eureka/eureka/,http://peer3:8761/eureka/eureka/
多网卡ip选择配置方法总结归纳
除去上面的配置方法,还有其他能实现多网卡ip选择的方式,可以根据自己的网络环境情况选择使用。归纳如下:
方法一:直接配置eureka.instance.ip-address
eureka.instance.ip-address=192.168.1.7
直接配置一个完整的ip,一般适用于环境单一场景,对于复杂场景缺少有利支持。比如:你的eureka环境是结合docker容器部署的,就会有问题。因为docker容器的ip是动态的不固定的,所以你很难为docker容器中的服务指定ip。所以这种方式通常不建议使用。
方法二:增加inetutils相关配置
配置对应org.springframework.cloud.commons.util.InetUtilsProperties,其中包含:
| 配置 | 说明 |
|---|---|
| spring.cloud.inetutils.default-hostname | 默认主机名,只有解析出错才会用到 |
| spring.cloud.inetutils.default-ip-address | 默认ip地址,只有解析出错才会用到 |
| spring.cloud.inetutils.ignored-interfaces | 配置忽略的网卡地址 |
| spring.cloud.inetutils.preferred-networks | 期望优先匹配的网卡,正则匹配的ip地址或者ip前缀 |
| spring.cloud.inetutils.timeout-seconds | 计算主机ip信息的超时时间,默认1秒钟 |
| spring.cloud.inetutils.use-only-site-local-interfaces | 只使用内网ip |
上面已经为大家介绍了ignored-interfaces和preferred-networks用法,其他的配置举例说明如下:
使用/etc/hosts中主机名称映射的ip,这一种在docker swarm环境中比较好用。
# 随便配置一个不可能存在的ip,会走到InetAddress.getLocalHost()逻辑。
spring.cloud.inetutils.preferred-networks=none
当所有的网卡遍历逻辑都没有找到合适的网卡ip,会走JDK的InetAddress.getLocalHost()。该方法会返回当前主机的hostname, 然后会根据hostname解析出对应的ip。
# 只使用内网地址,遵循 RFC 1918
# 10/8 前缀
# 172.16/12 前缀
# 192.168/16 前缀
spring.cloud.inetutils.use-only-site-local-interfaces=true
通过启动命令行传递配置
java -jar xxx.jar --spring.cloud.inetutils.preferred-networks= #需要设置的IP地址
或者
java -jar xxx.jar --spring.cloud.inetutils.ignored-interfaces= #需要过滤掉的网卡
源码解析
为了说明这个问题的解决方案,我们需要翻看一下Eureka Client的源码。com.netflix.appinfo包下的InstanceInfo类封装了本机信息,其中就包括了IP地址。在 Spring Cloud 环境下,Eureka Client并没有自己实现探测本机IP的逻辑,而是交给Spring的InetUtils工具类的findFirstNonLoopbackAddress()方法完成的:
public InetAddress findFirstNonLoopbackAddress()
InetAddress result = null;
try
// 记录网卡最小索引
int lowest = Integer.MAX_VALUE;
// 获取主机上的所有网卡
for (Enumeration<NetworkInterface> nics = NetworkInterface
.getNetworkInterfaces(); nics.hasMoreElements();)
NetworkInterface ifc = nics.nextElement();
if (ifc.isUp())
log.trace("Testing interface: " + ifc.getDisplayName());
if (ifc.getIndex() < lowest || result == null)
lowest = ifc.getIndex(); // 记录索引
else if (result != null)
continue重学SpringCloud系列五之服务注册与发现---中