机器学习之线性回归岭回归Lasso回归
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之线性回归岭回归Lasso回归相关的知识,希望对你有一定的参考价值。
1、回归算法
分类算法的目标值是标称型数据,而回归的目标变量是连续型数据,主要包括线性回归,岭回归,lasso回归,前向逐步回归。
2、线性回归
线性回归主要用于处理线性数据,结果易于理解,计算复杂度不高,但是处理不了非线性数据。线性回归用最适直线(回归线)去建立因变量Y和一个或多个自变量X之间的关系。可以用公式来表示:Y = wX + b。其中w为权重,也称为回归系数,b为偏置顶。
3、理解线性回归
线性回归从高中数学就接触过了,不过我们主要学习二维形式的线性回归,即y = kx + b。其中斜率k就是权重,截距b就是偏置顶。我们在算法的数据中通常是多维(多特征)的,我们需要找出误差最小的超平面。
4、误差分析(损失函数)
损失函数定义为平方误差之和:

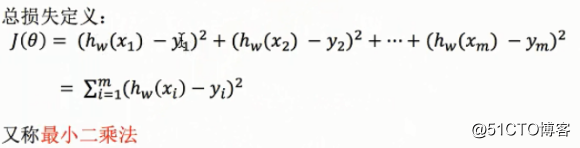
5、求解回归系数
求解回归系数通常有两种方法,一种是利用普通最小二乘法,另一种则是梯度下降法。
普通最小二乘法:利用矩阵求解在进行矩阵求解中,为了简化运算,我们通常将函数的形式改为y = w1*x1 + w2*x2 + w3*x3 + ...+wn*1(wn*1表示的就是偏置顶b),输入数据处理为(x1,x2,x3,...,1),而我们做回归算法的目的就是求出权重w1,w2,...wn
梯度下降法:利用梯度下降不断迭代寻求最优超平面(详见《统计学习方法》感知机)
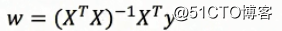
6、代码实现
6.1、 Python代码实现:
import numpy as np
def loadDataSet():
#构造数据集
x = np.mat([[1, 1 ,1], [1, 2 ,1], [2, 2 ,1], [2, 3 ,1]])#最后一列是偏置顶的转换,都是1
y = np.mat([[103],[105],[106],[108]])#y=1*x0 + 2*x1 + 100
return x,y
def standRegres(xMat,yMat):
#利用矩阵求解回归系数
xTx = xMat.T*xMat
if np.linalg.det(xTx) == 0.0:
#如果行列式等于0 就返回,因为在求解逆矩阵会出现错误
return
ws = xTx.I * (xMat.T*yMat)
return ws
if __name__ == ‘__main__‘:
x_train, y_train = loadDataSet()
ws = standRegres(x_train,y_train)
print(ws)
6.2、 sklearn库的实现:
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
def Regressor():
#读取sklearn的数据:波士顿房价
bos = load_boston()
x = bos.data
y = bos.target
#切割数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
#使用普通最下二乘法求解回归系数
lr = LinearRegression()
lr.fit(x_train,y_train)
y_predict_1 = lr.predict(x_test)
print(‘我是回归系数:‘,lr.coef_)#输出回归系数的权重
print(‘我是偏置顶:‘,lr.intercept_)#输出回归系数的偏置顶
print(‘我是预测值:‘,y_predict_1)#输出预测值
print(‘----------------------------------我是华丽的分割线----------------------------------------------------‘)
#使用梯度下降法求解回归系数
sr = SGDRegressor()
sr.fit(x_train, y_train)
y_predict_2 = sr.predict(x_test)
print(‘我是回归系数:‘,sr.coef_)#输出回归系数的权重
print(‘我是偏置顶:‘,sr.intercept_)#输出回归系数的偏置顶
print(‘我是预测值:‘,y_predict_2)#输出预测值
if __name__ == ‘__main__‘:
Regressor()
7、正则化的线性回归:岭回归与Lasso回归
在使用普通最小二乘法求解回归系数时,会出现两个问题,一个就是数据的特征数目比样本点数目还多,一个是数据存在相同或成比例的行(非满秩矩阵)。此时,在求逆矩阵的时候就会出错。于是,便引进了岭回归,Lasso回归。
8、岭回归
岭回归最先用来处理特征数过多的情况,后来通过加入惩罚项,能够减少不重要的参数
求解公式:
在实际的算法过程中,通常采用交叉验证,寻求最佳的λ值
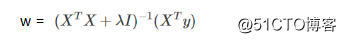
9、Lasso回归
Lasso回归岭回归非常类似,不同的是求解回归系数的目标函数中使用的惩罚函数是L1范数,效果更好,但是计算会相对复杂一点。
10、代码实现
10.1、岭回归的sklearn库的实现
from sklearn.datasets import load_boston
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
def RidgeReression(alpha):
#读取sklearn的数据:波士顿房价
bos = load_boston()
x = bos.data
y = bos.target
#切割数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
#使用普通最下二乘法求解回归系数
rd = Ridge(alpha=alpha)
rd.fit(x_train,y_train)
y_predict = rd.predict(x_test)
error = mean_squared_error(y_predict, y_test)
# print(‘我是回归系数:‘,rd.coef_)#输出回归系数的权重
# print(‘我是偏置顶:‘,rd.intercept_)#输出回归系数的偏置顶
# print(‘我是预测值:‘,y_predict)#输出预测值
# print(‘我是方差:‘,error)
return error
if __name__ == ‘__main__‘:
alphas = [0,0.001,0.005,0.1,0.5,1,2,3,4,5,10,100,100]
#交叉验证
for a in alphas:
print(a,‘:‘,RidgeReression(a))
10.2、Lasso的sklearn库的实现
from sklearn.datasets import load_boston
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
def LassoReression(alpha):
# 读取sklearn的数据:波士顿房价
bos = load_boston()
x = bos.data
y = bos.target
# 切割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 使用普通最下二乘法求解回归系数
ls = Lasso(alpha=alpha)
ls.fit(x_train, y_train)
y_predict = ls.predict(x_test)
error = mean_squared_error(y_predict, y_test)
# print(‘我是回归系数:‘,rd.coef_)#输出回归系数的权重
# print(‘我是偏置顶:‘,rd.intercept_)#输出回归系数的偏置顶
# print(‘我是预测值:‘,y_predict)#输出预测值
# print(‘我是方差:‘,error)
return error
if __name__ == ‘__main__‘:
alphas = [0, 0.001, 0.005, 0.1, 0.5, 1, 2, 3, 4, 5, 10, 100]
# 交叉验证
for a in alphas:
print(a, ‘:‘, LassoReression(a))
以上是关于机器学习之线性回归岭回归Lasso回归的主要内容,如果未能解决你的问题,请参考以下文章