吴恩达深度学习:2.3梯度下降Gradient Descent
Posted bigdata-stone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴恩达深度学习:2.3梯度下降Gradient Descent相关的知识,希望对你有一定的参考价值。
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输出y,把它和基本真值标签y进行比较
右边展示了完整的公式,成本函数衡量了参数w和b在训练集上的效果。要找到合适的w和b,就很自然的想到,使得成本函数J(w,b)尽可能小的w和b
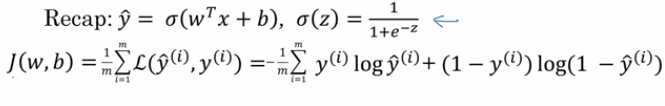
2.接下来看看梯度下降算法,下图中的横轴表示空间参数w和b,在实践中,w可以是更高维的,但是为了绘图的方便,我们让w是一个实数,b也是一个实数,成本函数J(w,b)是在水平轴w和b上的曲面,曲面的高度J(w,b)表示在某一点的值,我们所要做的就是找到这样的w和b,使其对应的成本函数J值是最小值,我们可以看到成本函数J是一个凸函数,就像这样的大碗,因此这是一个凸函数
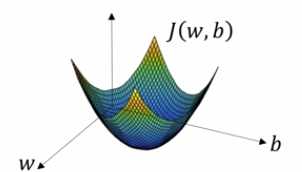
和下面这个函数不一样,下面这个函数是非凸的,它有很不同的局部最优解

为了找到更好的参数值,我们要做的就是用某初始值初始化w和b值,对于logitstic回归而言,几乎任意的初始方法都有效,通常用0进行初始化。梯度下降算法就是从初始点开始,朝最陡的方向走一步,在梯度下降一步后,它可能停在那里,因为它正试图沿着最快下降的方向往下走或者说尽可能快的往下走,这就是梯度下降的一次迭代。
我们更新w,使得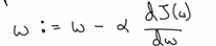 ,在算法收敛之前,我们重复这样做,这里α表示学习率,可以控制每一次迭代或者梯度下降中的步长。无论从哪个方向来变化,梯度下降算法都会朝着全局最小值方向移动,
,在算法收敛之前,我们重复这样做,这里α表示学习率,可以控制每一次迭代或者梯度下降中的步长。无论从哪个方向来变化,梯度下降算法都会朝着全局最小值方向移动,
以上是关于吴恩达深度学习:2.3梯度下降Gradient Descent的主要内容,如果未能解决你的问题,请参考以下文章
吴恩达-深度学习-课程笔记-7: 优化算法( Week 2 )