第一次个人代码任务总结
——论一条咸鱼的自我修养
1· 项目要求
1.1 基本功能
- 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php 等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
- 使用性能测试工具进行分析,找到性能的瓶颈并改进。
- 对代码进行质量分析,消除所有警告。
- 设计 10 个测试样例用于测试,确保程序正常运行(如:空文件,只含一个词的文件,只有一行的文件,典型文件等)。
- 使用 Github 进行代码管理。
- Linux 下性能分析(附加任务)。
- 撰写博客。
1.2 注意事项
a) 需要统计的字符等价于 ASCII 码值属于 [32,126] 区间。
b) 单词的定义:至少以 4 个英文字母开头,跟上字母数字符号;单词以分隔符(非字母数字符号)分割;不分大小写;如果两个单词只有最后的数字结尾不同,则认为等价;等价单词输出按字典顺序;单词长度只需要考虑 [4, 1024],超出此范围的不用统计。
c) 词组的定义:同一文件内,相邻两个合法的单词组成词组;若两单词分别均等价,则为同一词组;按字典顺序输出。
d) 输入文件名以命令行参数传入。需要遍历整个文件夹时,则要输入文件夹的路径。
e) 根据命令行参数判断是否为目录。
f) 将所有文件中的词汇,进行统计,最终只输出一个整体的词频统计结果输出文件 result.txt。
2· 思路历程
2.1 遍历文件夹
起初,并不知道 C/C++ 程序下如何打开指定路径的目录,上网查询后得知在 <io.h> 下有可以使用的库函数。其中,结构体_finddata_t 用于存储文件信息,还需要用到 _findfirst、_findnext、_findclose 这三个函数。仔细学习了结构体各分量意义、函数参数传递、返回值,然后掌握了打开文件的方法,再结合递归调用即可,详见后面。
2.2 读取单词
由于还需要统计所有合法字符数,行数,所以一开始思路是用 fgetc(),在打开文件之后逐字符读取,字符数通过 ASCII 码值统计,而行数可以构造映射除第一行外每一个换行符开启新的一行,所以每个文件行数即为换行符数加一。而对于单词数,可以边读字符数的时候,便进行分析判断合法的单词并统计。
接下来的问题就是如何确定存储数据结构。一开始,我查询过字典树的相关知识,其优点是便于排序和查找,但是修改起来较为繁琐况且我们并不需要排序,故弃之。接着,考虑过哈希表,哈希对于解决我们的需求有很大优势,但是又觉得写起来麻烦,需要构造哈希函数和冲突解决方式,又弃之。然后受到单词前四个字符必须是字母的启发,想到了将前面四个字母与四位 26 进制数进行一一映射,构造结构体储存单词信息,开辟长度为 26*26*26*26 的结构体指针数组,对于每个单词通过首四字母计算唯一的地址,对于首四字母相同的单词在该地址下进行链表字典有序查找、插入和修改。详情参见后。
2.3 读取词组
对于读取词组这种要求,一开始我的内心其实是拒绝的,所以先想着先把单词解决。殊不知,解决完单词之后,尴尬的境地才出现了。其中我历经了两个彻底不同的处理词组代码的实现。
原始版本下,由于单词结构体已经开辟,不想再为词组申请大量存储空间,我在单词结构体之下增加一个分量,每次读取一个单词,顺便拉一条链指向该单词上一位出现过的所有单词,由此存储词组信息,然后处境异常尴尬,出现了情理之中的恰如其分的繁琐,更尴尬的就是我静下心来也完成了统计,词组 top10 结果均正确,运行也是情理之中的恰如其分的慢。代码整合后已经到了星期四中午,但我还是决定重新处理这部分。
优化版本下,我还是改用了哈希表的方式处理词组,因为我查到了 C++ 的 STL 库中有 unordered_map 的库可以用,之前并没有接触过,甚至 C++ 都不熟,还是学习了一下这其中的类和对象,然后重载方法,定义词组结构体,里面有指向两单词的指针和该词组数,将该结构体自定义为 hash key,然后又自定义 hash 函数和 hash 比较函数,使用 unordered_map 处理词组。
2.4 频率统计
由于一开始对革命路线错误的估计和判断,很单纯地觉得庞大的数量用遍历肯定不好,所以在一边读取的时候一边更新 top10,后来才意识到,实时更新复杂度更高,因为读完后很多单词都重复出现,而在实时读取更新的时候则浪费了比较时间。
3· 具体实现
3.1 数据结构
3.1.1 单词 (原始版)


1 struct wordsdata //存放单词信息 2 { 3 char words[1024]; //单词字符串 4 int number; //单词数量 5 wordsdata *next; 6 phrase *prehead; //指向词组 7 };
单词还会拉出一条链,指向所有与之构成词组的上一位单词。
3.1.2 词组(原始版)
1 struct phrase //词组信息 2 { 3 int number; 4 char *before; //指向前一位单词 5 phrase *next; 6 };
存放指向上一位单词的字符串地址。
3.1.3 单词 (优化版)
1 struct wordsdata //存放单词信息 2 { 3 char words[1024]; //单词字符串 4 int number; //出现次数 5 wordsdata *next; 6 };
只存放单词基本信息。
3.1.4 词组 (优化版)
1 struct phrases 2 { 3 char *one; 4 char *tw; 5 int num; 6 };
分别指向两单词字符串地址,保存数量信息。
3.1.5 哈希(优化版)
1 struct phrase_cmp 2 { 3 bool operator()(const phrases &p1, const phrases &p2) const 4 { 5 return ((wordcmp(p1.one, p2.one) < 2) && (wordcmp(p1.tw, p2.tw) < 2)); 6 } 7 8 }; 9 struct phrase_hash 10 { 11 size_t operator()(const phrases &ph) const 12 { 13 unsigned long __h = 0; 14 int temp; 15 size_t i; 16 for (i = 0; ph.one[i]; i++) 17 { 18 temp = ph.one[i]; 19 if (temp > 64) 20 { 21 (temp > 96) ? (temp - 96) : (temp - 64); 22 __h += (29 * __h + temp); 23 __h %= 2147483647; 24 } 25 26 } 27 for (i = 0; ph.tw[i]; i++) 28 { 29 temp = ph.tw[i]; 30 if (temp > 64) 31 { 32 (temp > 96) ? (temp - 96) : (temp - 64); 33 __h += (29 * __h + temp); 34 __h %= 2147483647; 35 } 36 } 37 38 return size_t(__h); 39 } 40 41 }; 42 43 typedef unordered_map<phrases, int, phrase_hash, phrase_cmp> Char_Phrase; 44 Char_Phrase phrasemap;
使用 unordered_map,并自定义 key ,即 3.14 中的词组;自定义 hash 函数以及 hash 比较函数。
3.2 主要函数
3.2.1 遍历文件夹
1 int getfiles(char *path, struct _finddata_t *fileinfo, long handle) 2 { 3 handle = _findfirst(path, fileinfo); //第一次打开父目录 4 if (handle == -1) 5 return -1; 6 7 8 do 9 { 10 //printf("> %s\\n", path); //显示目录名 11 12 if (fileinfo->attrib & _A_SUBDIR) //如果读取到子目录 13 { 14 if (strcmp(fileinfo->name, ".") != 0 && strcmp(fileinfo->name, "..") != 0) 15 { 16 char temppath[1024] = ""; //记录子目录路径 17 long temphandle = 0; 18 struct _finddata_t tempfileinfo; 19 strcpy(temppath, path); 20 strcat(temppath, "/*"); 21 22 temphandle = _findfirst(temppath, &tempfileinfo); //第一次打开子目录 23 if (temphandle == -1) 24 return -1; 25 26 do //对子目录所有文件递归 27 { 28 if (strcmp(tempfileinfo.name, ".") != 0 && strcmp(tempfileinfo.name, "..") != 0) 29 { 30 strcpy(temppath, path); 31 strcat(temppath, "/"); 32 strcat(temppath, tempfileinfo.name); 33 getfiles(temppath, &tempfileinfo, temphandle); 34 } 35 } while (_findnext(temphandle, &tempfileinfo) != -1); 36 37 _findclose(temphandle); 38 }//递归完毕 39 40 } //子目录读取完毕 41 else 42 getwords(path, fourletter); 43 44 45 } while (_findnext(handle, fileinfo) != -1); 46 47 _findclose(handle); //关闭句柄 48 49 return 1; 50 51 }
每次通过 char *path 来保存路径,递归遍历文件夹。
3.2.2 读取单词和词组 (原始版)
1 int getwords(char *path, struct wordsdata **word) 2 { 3 FILE *fp; 4 int cmp = 0; 5 int num = 0; //计算首四位地址 6 char temp = 0; //读取一个字符 ACSII 码值 7 int length = 0; 8 9 char present[1024] = ""; //存储当前单词 10 char address[4] = ""; 11 12 struct wordsdata *pre = NULL; 13 struct wordsdata *q = NULL; 14 struct wordsdata *newword = NULL; 15 struct wordsdata *previous = NULL; 16 struct phrase *newphrase = NULL; 17 struct phrase *preword = NULL; 18 struct phrase *p = NULL; 19 20 if ((fp = fopen(path, "r")) == NULL) 21 { 22 printf("打开文件 %s 错误!!! \\n", path); 23 return 0; 24 } 25 linenum++; 26 while (temp != -1) 27 { 28 //读取字符串 29 temp = fgetc(fp); 30 if (temp > 31 && temp < 127) 31 charnum++; 32 if (temp == ‘\\n‘ || temp == ‘\\r‘) 33 linenum++; 34 35 while ((temp >= ‘0‘ && temp <= ‘9‘) || (temp >= ‘a‘ && temp <= ‘z‘) || (temp >= ‘A‘ && temp <= ‘Z‘)) 36 { 37 if (length != -1 && length < 4) 38 { 39 if (temp >= ‘A‘) //是字母 40 { 41 present[length] = temp; 42 address[length] = (temp >= ‘a‘ ? (temp - ‘a‘) : (temp - ‘A‘)); 43 length++; 44 } 45 else //不是字母 46 length = -1; 47 } 48 else if (length >= 4) 49 { 50 present[length] = temp; 51 length++; 52 } 53 temp = fgetc(fp); 54 if (temp > 31 && temp < 127) 55 charnum++; 56 if (temp == ‘\\n‘ || temp == ‘\\r‘) 57 linenum++; 58 } // end while 59 60 //判断是否为单词 61 if (length >= 4) 62 { 63 wordnum++; 64 65 //计算首四位代表地址 66 num = address[0] * 17576 + address[1] * 676 + address[2] * 26 + address[3]; 67 68 //插入当前单词 69 if (word[num] == NULL) 70 { 71 word[num] = new wordsdata; 72 newword = new wordsdata; 73 newword->number = 1; 74 newword->next = NULL; 75 strcpy(newword->words, present); 76 word[num]->next = newword; 77 78 if (previous != NULL) 79 { 80 newword->prehead = new phrase; 81 newword->prehead->before = previous->words; 82 newword->prehead->next = NULL; 83 newword->prehead->number = 1; 84 } 85 previous = newword; 86 } 87 else 88 { 89 pre = word[num]; 90 q = pre->next; 91 cmp = wordcmp(q->words, present); 92 93 while (cmp == small) 94 { 95 pre = q; 96 q = q->next; 97 if (q != NULL) 98 cmp = wordcmp(q->words, present); 99 else 100 break; 101 } 102 if (q != NULL && cmp <= 1) 103 { 104 q->number++; 105 if (cmp == 1) 106 strcpy(q->words, present); 107 108 if (previous != NULL) 109 { 110 if (q->prehead == NULL) 111 { 112 q->prehead = new phrase; 113 q->prehead->before = previous->words; 114 q->prehead->next = NULL; 115 q->prehead->number = 1; 116 } 117 else 118 { 119 p = q->prehead; 120 while (p != NULL && p->before != previous->words) 121 { 122 p = p->next; 123 } 124 if (p != NULL) 125 p->number++; 126 else 127 { 128 preword = new phrase; 129 preword->before = previous->words; 130 preword->number = 1; 131 preword->next = q->prehead; 132 q->prehead = preword; 133 134 } 135 } 136 } 137 previous = q; 138 } 139 140 else 141 { 142 newword = new wordsdata; 143 newword->number = 1; 144 strcpy(newword->words, present); 145 pre->next = newword; 146 newword->next = q; 147 148 if (previous != NULL) 149 { 150 newword->prehead = new phrase; 151 newword->prehead->before = previous->words; 152 newword->prehead->next = NULL; 153 newword->prehead->number = 1; 154 } 155 previous = newword; 156 } 157 158 } 159 160 //当前单词置空 161 for (int j = 0; present[j] && j < 1024; j++) 162 present[j] = 0; 163 } 164 length = 0; 165 } 166 167 fclose(fp); 168 return 1; 169 }
边读边分析是否为单词,查询、插入、修改单词,并且保存每个单词结构体又拉一条链,存储与它构成词组的单词信息。
3.2.3 读取单词和词组 (优化版)
1 int getwords(char *path, struct wordsdata **word) 2 { 3 FILE *fp; 4 int j = 0; 5 int cmp = 0; 6 int num = 0; //计算首四位地址 7 char temp = 0; //读取一个字符 ACSII 码值 8 int length = 0; 9 10 char present[1024] = ""; //存储当前单词 11 12 char address[4] = ""; 13 struct wordsdata *q = NULL; 14 struct wordsdata *pre = NULL; 15 struct wordsdata *neword = NULL; 16 struct wordsdata *now = NULL; 17 struct wordsdata *previous = NULL; 18 struct phrases *newphrase = NULL; 19 20 if ((fp = fopen(path, "r")) == NULL) 21 { 22 //printf("error!!! \\n", path); 23 return 0; 24 } 25 linenum++; 26 while (temp != -1) 27 { 28 //读取字符串 29 temp = fgetc(fp); 30 if (temp > 31 && temp < 127) 31 charnum++; 32 if (temp == ‘\\n‘ || temp == ‘\\r‘) 33 linenum++; 34 35 while ((temp >= ‘0‘ && temp <= ‘9‘) || (temp >= ‘a‘ && temp <= ‘z‘) || (temp >= ‘A‘ && temp <= ‘Z‘)) 36 { 37 if (length != -1 && length < 4) 38 { 39 if (temp >= ‘A‘) //是字母 40 { 41 present[length] = temp; 42 address[length] = (temp >= ‘a‘ ? (temp - ‘a‘) : (temp - ‘A‘)); 43 length++; 44 } 45 else //不是字母 46 length = -1; 47 } 48 else if (length >= 4) 49 { 50 present[length] = temp; 51 length++; 52 } 53 temp = fgetc(fp); 54 if (temp > 31 && temp < 127) 55 charnum++; 56 if (temp == ‘\\n‘ || temp == ‘\\r‘) 57 linenum++; 58 } // end while 59 60 //判断是否为单词 61 if (length >= 4) 62 { 63 wordnum++; 64 65 //计算首四位代表地址 66 num = address[0] * 17576 + address[1] * 676 + address[2] * 26 + address[3]; 67 68 //插入当前单词 69 if (word[num] == NULL) 70 { 71 word[num] = new wordsdata; 72 neword = new wordsdata; 73 neword->number = 1; 74 neword->next = NULL; 75 strcpy(neword->words, present); 76 word[num]->next = neword; 77 now = neword; 78 } 79 else 80 { 81 pre = word[num]; 82 q = pre->next; 83 cmp = wordcmp(q->words, present); 84 85 while (cmp == small) 86 { 87 pre = q; 88 q = q->next; 89 if (q != NULL) 90 cmp = wordcmp(q->words, present); 91 else 92 break; 93 } 94 if (q != NULL && cmp <= 1) 95 { 96 now = q; 97 q->number++; 98 if (cmp == 1) 99 strcpy(q->words, present); 100 } 101 102 else 103 { 104 neword = new wordsdata; 105 neword->number = 1; 106 strcpy(neword->words, present); 107 pre->next = neword; 108 neword->next = q; 109 now = neword; 110 } 111 } 112 113 if (previous != NULL) 114 { 115 newphrase = new phrases; 116 117 newphrase->tw = now->words; 118 newphrase->one = previous->words; 119 120 unordered_map<phrases, int>::const_iterator got = phrasemap.find( *newphrase); 121 if (got != phrasemap.end()) 122 { 123 phrasemap[*newphrase]++; 124 } 125 else 126 { 127 phrasemap.insert(pair<phrases, int>(*newphrase, 1)); 128 } 129 } 130 previous = now; 131 132 //当前单词置空 133 for (int j = 0; present[j] && j < 1024; j++) 134 present[j] = 0; 135 } 136 length = 0; 137 } 138 139 fclose(fp); 140 return 1; 141 }
边读边分析是否为单词,查询、插入、修改单词,用 unordered_map 处理词组,构建哈希表,查询、插入、修改词组。
3.2.4 比较单词序
1 int wordcmp(char *str1, char *str2) 2 { 3 char *p1 = str1; 4 char *p2 = str2; 5 char q1 = *p1; 6 char q2 = *p2; 7 8 if (q1 >= ‘a‘ && q1 <= ‘z‘) 9 q1 -= 32; 10 11 if (q2 >= ‘a‘ && q2 <= ‘z‘) 12 q2 -= 32; 13 14 while (q1 && q2 && q1 == q2) 15 { 16 p1++; 17 p2++; 18 19 q1 = *p1; 20 q2 = *p2; 21 22 if (q1 >= ‘a‘ && q1 <= ‘z‘) 23 q1 -= 32; 24 25 if (q2 >= ‘a‘ && q2 <= ‘z‘) 26 q2 -= 32; 27 } 28 29 while (*p1 >= ‘0‘ && *p1 <= ‘9‘) 30 p1++; 31 while (*p2 >= ‘0‘ && *p2 <= ‘9‘) 32 p2++; 33 34 if (*p1 == 0 && *p2 == 0) //两单词等价 35 return strcmp(str1, str2); //等价前者字典顺序小返回-1,大返回1,完全相等返回0 36 37 if (q1 < q2) //前者小 38 return 2; 39 40 if (q1 > q2) //后者小 41 return 3; 42 43 return 4; 44 }
比较单词是否等价,以及字典序。
3.2.5 获取 top10 (原始版)
1 int gettop(struct wordsdata **word) 2 { 3 int i = 0, j = 0; 4 struct phrasetop *ph[12] = {}; 5 struct wordsdata *top[12] = {}; 6 struct phrase *p = NULL; 7 struct wordsdata *w = NULL; 8 9 for (j = 0; j < 12; j++) 10 { 11 ph[j] = new struct phrasetop; 12 ph[j]->number = 0; 13 ph[j]->first = ""; 14 ph[j]->last = ""; 15 top[j] = new struct wordsdata; 16 top[j]->number = 0; 17 } 18 for (int i = 0; i < 456976; i++) 19 { 20 if (word[i] != NULL) 21 { 22 w = word[i]->next; 23 while (w != NULL) 24 { 25 top[11]->number = w->number; 26 top[11]->next = w; 27 j = 11; 28 while (j > 1 && top[j]->number > top[j - 1]->number) 29 { 30 top[0] = top[j]; 31 top[j] = top[j - 1]; 32 top[j - 1] = top[0]; 33 j--; 34 } 35 p = w->prehead; 36 while (p != NULL) 37 { 38 ph[11]->number = p->number; 39 ph[11]->last = w->words; 40 ph[11]->first = p->before; 41 j = 11; 42 while (j > 1 && (ph[j]->number > ph[j - 1]->number)) 43 { 44 ph[0] = ph[j]; 45 ph[j] = ph[j - 1]; 46 ph[j - 1] = ph[0]; 47 j--; 48 } 49 p = p->next; 50 } 51 w = w->next; 52 } 53 54 } 55 56 } 57 58 for (j = 1; j < 11; j++) 59 { 60 if (top[j]) 61 printf("\\n%s :%d", top[j]->next->words, top[j]->number); 62 } 63 for (j = 1; j < 11; j++) 64 { 65 if (ph[j]) 66 printf("\\n%s %s:%d ", ph[j]->first, ph[j]->last, ph[j]->number); 67 } 68 return 1; 69 }
链表一次遍历查找单词、词组前十。
3.2.6 获取 top10 (优化版)
1 int gettop(struct wordsdata **word) 2 { 3 int i = 0, j = 0; 4 struct wordsdata *topw[12] = {}; 5 struct phrases *toph[12] = {}; 6 struct wordsdata *w = NULL; 7 FILE *fp; 8 fp = fopen("result.txt", "w"); 9 fprintf(fp,"characters:%d \\nwords:%d \\nlines:%d\\n", charnum,wordnum, linenum); 10 11 for (j = 0; j < 12; j++) 12 { 13 toph[j] = new struct phrases; 14 toph[j]->num = 0; 15 topw[j] = new struct wordsdata; 16 topw[j]->number = 0; 17 } 18 for (i = 0; i < 456976; i++) 19 { 20 if (word[i] != NULL) 21 { 22 w = word[i]->next; 23 while (w != NULL) 24 { 25 topw[11]->number = w->number; 26 topw[11]->next = w; 27 j = 11; 28 while (j > 1 && topw[j]->number > topw[j - 1]->number) 29 { 30 topw[0] = topw[j]; 31 topw[j] = topw[j - 1]; 32 topw[j - 1] = topw[0]; 33 j--; 34 } 35 w = w->next; 36 } 37 } 38 } 39 for (j = 1; j < 11; j++) 40 { 41 if (topw[j]->number) 42 fprintf(fp,"\\n%s :%d", topw[j]->next->words, topw[j]->number); 43 } 44 for (Char_Phrase::iterator it = phrasemap.begin(); it != phrasemap.end(); it++) 45 { 46 toph[11]->one = it->first.one; 47 toph[11]->tw = it->first.tw; 48 toph[11]->num = it->second; 49 j = 11; 50 while (j > 1 && toph[j]->num > toph[j - 1]->num) 51 { 52 toph[0] = toph[j]; 53 toph[j] = toph[j - 1]; 54 toph[j - 1] = toph[0]; 55 j--; 56 } 57 } 58 fprintf(fp, "\\n"); 59 for (j = 1; j < 11; j++) 60 { 61 if (toph[j]->num) 62 fprintf(fp,"\\n%s %s :%d", toph[j]->one, toph[j]->tw, toph[j]->num); 63 } 64 fclose(fp); 65 return 1; 66 }
链表一次遍历查找单词,哈希一次遍历查找词组前十。
4. 测试结果
4.1 原始版
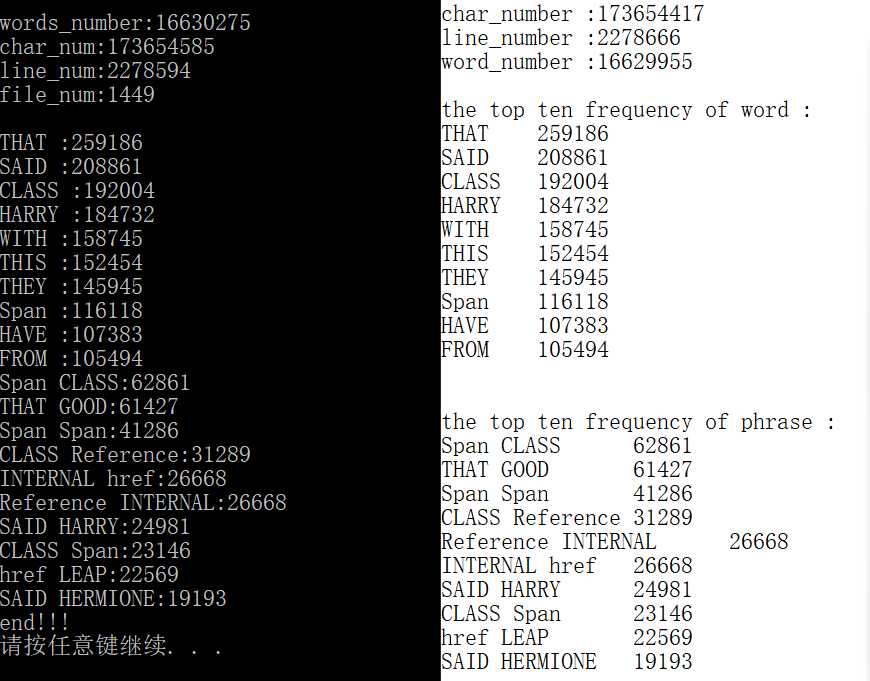
自己任意设计的测试样例,都可以通过。助教样例中,单词和词组的频率前十均正确,但行数、字符数、单词数结果均有误差数量级约 100。
4.1 优化版
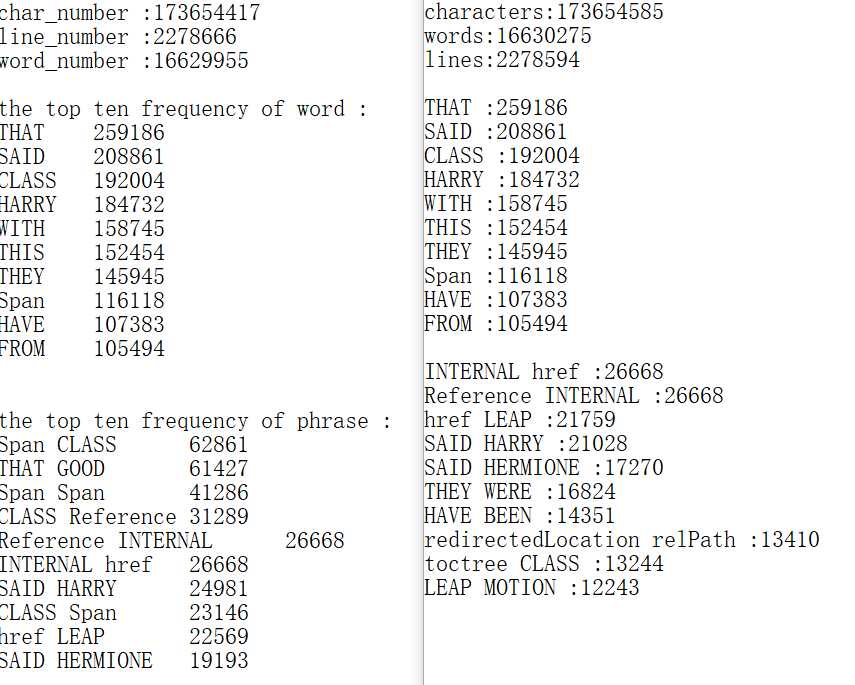
助教样例中,单词频率前十均正确,但行数、字符数、单词数结果不变,词组频率前十误差较大。自己调试时发现在 hash 表运用时出现 bug ,运用断点、调试窗口等,发现哈希表的查询出现 bug ,似乎并不能按照我设定的哈西比较函数进行查询,但已经到了周四下午,后来没时间解决了,后续还会继续改进。
5· 性能分析
5.1 原始版
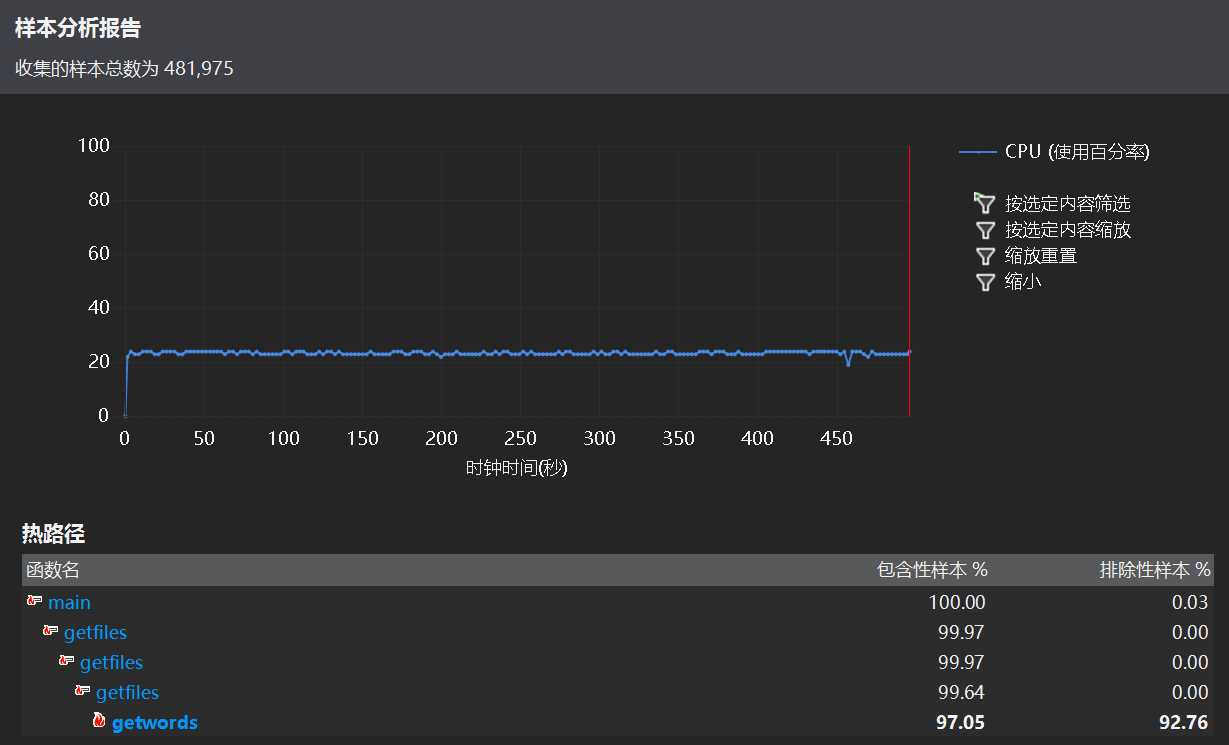
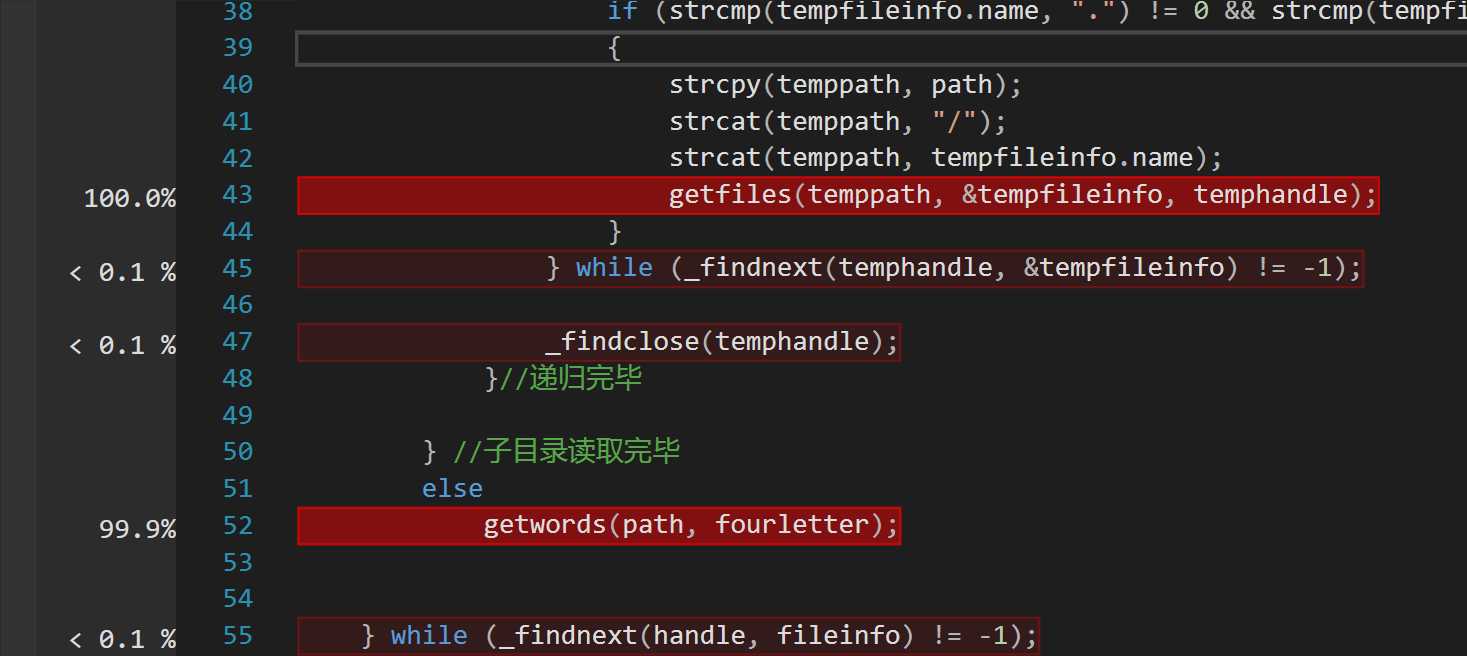
启动 VS2017 性能分析时,发现递归打开文件夹和读取单词调用较多,这在情理之中,每层递归都要处理完整个文件单词和词组。这一点上难做大的改动。
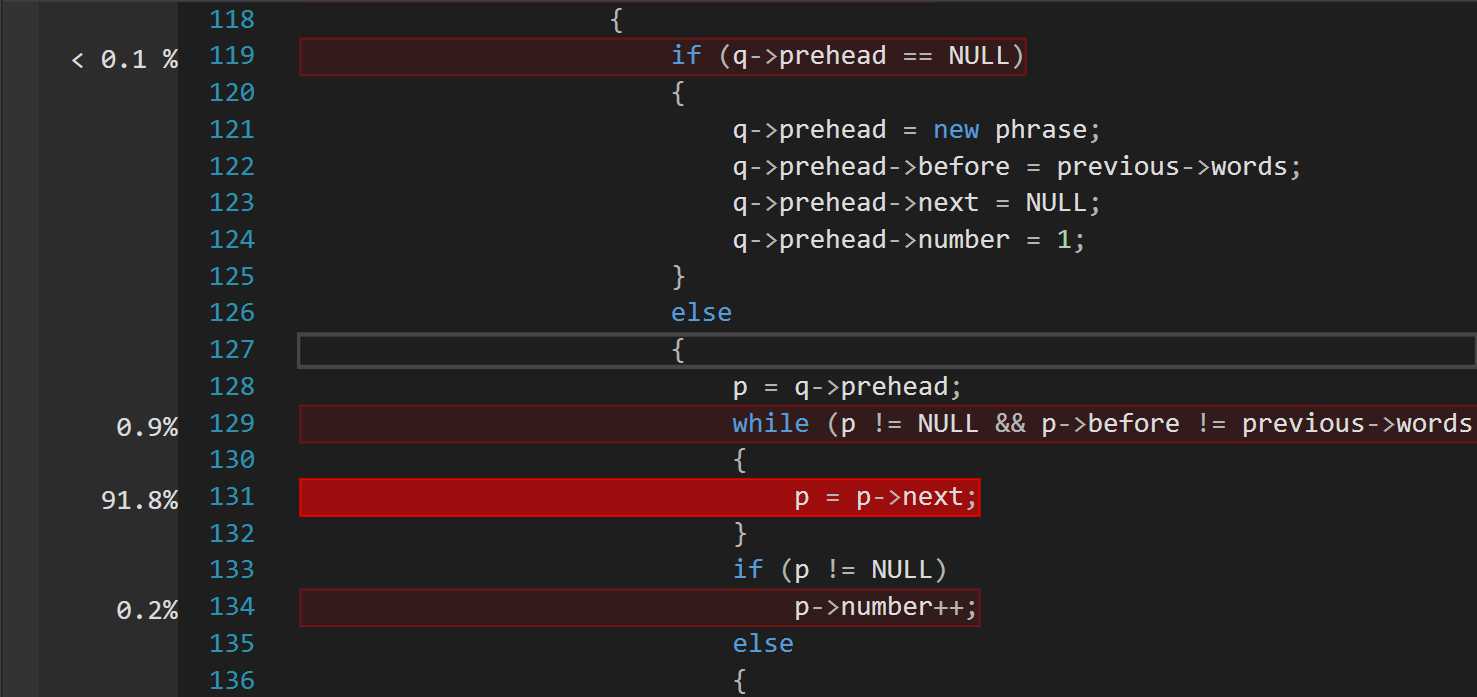
词组查询太过于耗时间,原始版中,词组是单词后面再拉链,头插法,每次遍历查找,写之前就知道时间复杂度很高,只是想实现它,并不对它的性能抱希望,结果也在情理之中。因此在临近 DDL 的时候,在不太会用 STL 库的时候,我还是毅然地选择了大幅改写程序。
另外,单词比较的程序被调用很多次,但这几乎也不能避免,因为任务要求中对单词的限定条件较多,因此比较起来较为麻烦,最好就是至多一次遍历就得出结果。
5.2 优化版
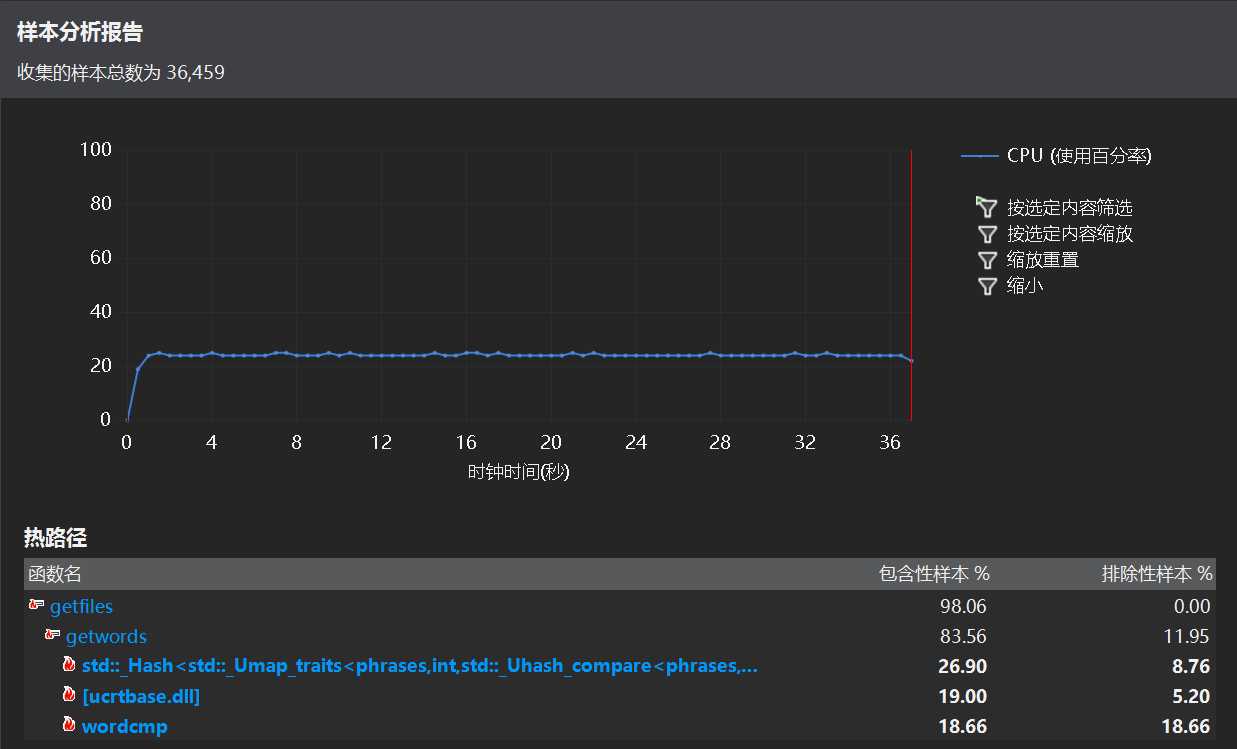
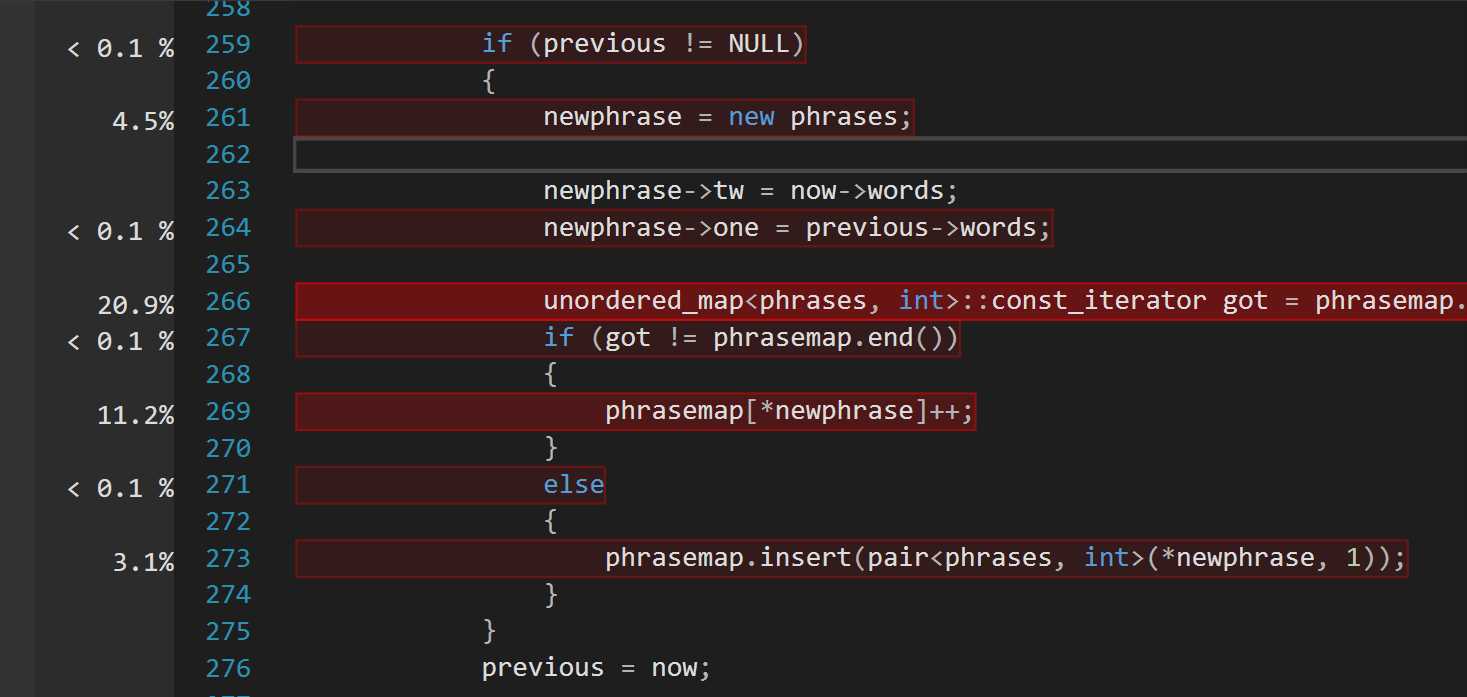
刚大幅改为哈希,没做细节上的优化,30 s 可以跑完,可以看到运行速度有了提升,虽然还是较慢,除了打开文件夹读取单词的函数调用最多外,哈希表简化了词组操作和时间复杂度。但是对于表中查询的 bug 我将会继续寻找解决。
另外 fgetc() 函数可能较慢,换用 fread() 可能更好,后面可以再做尝试,还有其他细节优化没来得及改善,后面会继续。
6. 总结
6.1 反思
1)时间复杂度
对于单词的查询,速度还是比较快,毕竟有 26*26*26*26 = 456976 个指针,而且对应关系唯一,顺序查找时间也还能接受;但是加入词组查询之后,运行速度锐减,词组查询太过于耗时,因此后来还是决定改写。在编程之前应该对问题做充分的思考,尽可能多提供几种解决思路,如果迫于学的知识少思路受限,应该主动自学更多知识并学以致用,而对于这些思路,逐一考量时间复杂度,思考得尽可能全面,先让程序在自己脑袋中跑起来。
2)编程效率
对于第一想法存在执念,在实现之后陷入尴尬,最后又进行了大幅修改,耗费了一定的时间,而学习了 unordered_map 的使用后,数据结构简化,程序更快,编程时间还远小于前者。原始版本的单词首四位计算地址后拉一条链,单词后面还拉链指向相关词组,实现起来很多细节想想就繁琐。但是在写完单词查询之后,再加入词组,很多问题我反应更加快了,一块块地编程调试,最终词组查询的编写反而更顺畅,对于助教样例,一遍就得到了正确结果,虽然运行较慢。结构丑是丑了一点,但还是锻炼了不少基本操作的能力,编程习惯有了改进,发现问题的能力也有所提高。但以后应该选用更加合理的数据结构,养成良好的编程习惯,提高效率。
3)面向对象
对第一想法的执念,某种程度上是智力上的懒惰的借口。再写出一个难看的结构后,我毅然地决定放弃,在仅剩的时间里学习并尝试了标准库的使用,虽然出现 bug 但是最后我还是提交了优化后的一版。面对复杂问题的时候,还是应该将问题尽可能地抽象化,将程序进行结构化设计,合理运用数据结构,合理使用标准库,如果不行就按照需求自己实现一些库。
6.2 课程建议
个人建议以后代码和优化可以分别提交,例如:该周四布置代码任务,下周四必须交一版程序,然后可以给再给一定的优化时间,比如三天后的周日提交最终优化版本。
IF(第一次提交效果就很好) 这部分同学可以展现优势,也能提高优化的积极性;
ELSE IF(能坚持做出优化) 很多意义并不能纯粹用结果去衡量,鼓励学生用于学习新知识,耐心发现自己的问题,或者进行优化改进可能也有意义;
ELSE 也能给部分学生一定的缓冲时间,因为我们并不只学软工这一门课程,在以软工为纲的大跃进之下,也要兼顾我科的数理基础。
6.2 论一条咸鱼的自我修养(扯淡杂谈)
咸鱼是否真的咸,也许并不重要,如果说面对任务反正都不能闲的话,还不如勇于去学习新的知识,至少不能放弃试图对观念意识和基本能力做出提升。因为以后面临的问题将会更复杂,而知识毕竟有限,在当前情形下,结果并不重要,分数就更不重要了,拒绝智力上的懒惰以求进步的姿态或许也有意义。比如我们的大项目作业——校园二手交易和信息共享网站平台,面临的问题更加复杂,所学的知识更加局限,但我反而更加期望去学习更多的知识,时刻理清逻辑结构,然后逐步客克服困难,当一个产品摆在眼前的时候,一定会有骄傲和喜悦。当我们深刻地意识到日益增长的任务需求和个人生产力之间的矛盾是,意识到有些事情掌控起来并不是想象的那么简单时,仍能够内心毫不抗拒地至少去做,这也是咸鱼的自我修养。
周四之前用于编程任务,周五上午下午和晚上都有事情,因此提交得迟了一点,因为出于强迫症并不想草率提交博客,事实上根据深厚的吹逼造诣也不是不行,上次周三读书笔记瞎扯一通,邓老师还赞了,也可以先提交后修改,但我本质上是个克制的体面人,因此还是认真记录了一条咸鱼的历程。
另外,在此立下 flag,以后认真自学 C++、Python 和 Java,提高编程的观念和意识。网站后端采用 Java,希望对它有新的理解,Python 运用较广人工智能也会大量应用,R.O.S 是基于 C++ 和 Python 写的,有时间一定要在实验室掌握 R.O.S 的使用。
7· 附录
7.1 PSP
| PSP | Stages | 预估耗时(min) | 实际耗时(min) |
|---|---|---|---|
| · Planning | · 计划 | 20 | 30 |
| · Estimate | · 估计任务时间 | 10 | 10 |
| · Analysis | · 需求分析 | 1 * 60 | 2 * 60 |
| · Design Spec | · 生成设计文档 | 20 | 10 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 | 10 | 20 |
| · Design | · 具体设计 | 30 | 1 * 60 |
| · Coding | · 具体编码 | 8 * 60 | 10 * 60 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(测试,修改,提交) | 5 * 60 | 7 * 60 |
| · Reporting | · 报告 | 3 * 60 | 4 * 60 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| All | 总记 | 1170 | 1580 |
7·2 提交版源码
1 #include "io.h" 2 #include "math.h" 3 #include "stdio.h" 4 #include "string.h" 5 #include "stdlib.h" 6 #include "unordered_map" 7 8 using namespace std; 9 10 #define small 2 11 12 int wordnum = 0; 13 int charnum = 0; 14 int linenum = 0; 15 16 struct wordsdata //存放单词信息 17 { 18 char words[1024]; //单词字符串 19 int number; //出现次数 20 wordsdata *next; 21 }; 22 struct phrases 23 { 24 char *one; 25 char *tw; 26 int num; 27 }; 28 29 int wordcmp(char *str1, char *str2); 30 int gettop(struct wordsdata **word); 31 int getwords(char *path, struct wordsdata **word); 32 int getfiles(char *path, struct _finddata_t *fileinfo, long handle); 33 34 struct phrase_cmp 35 { 36 bool operator()(const phrases &p1, const phrases &p2) const 37 { 38 return ((wordcmp(p1.one, p2.one) < 2) && (wordcmp(p1.tw, p2.tw) < 2)); 39 } 40 41 }; 42 struct phrase_hash 43 { 44 size_t operator()(const phrases &ph) const 45 { 46 unsigned long __h = 0; 47 int temp; 48 size_t i; 49 for (i = 0; ph.one[i]; i++) 50 { 51 temp = ph.one[i]; 52 if (temp > 64) 53 { 54 (temp > 96) ? (temp - 96) : (temp - 64); 55 __h += (29 * __h + temp); 56 __h %= 2147483647; 57 } 58 59 } 60 for (i = 0; ph.tw[i]; i++) 61 { 62 temp = ph.tw[i]; 63 if (temp > 64) 64 { 65 (temp > 96) ? (temp - 96) : (temp - 64); 66 __h += (29 * __h + temp); 67 __h %= 2147483647; 68 } 69 } 70 71 return size_t(__h); 72 } 73 74 }; 75 76 typedef unordered_map<phrases, int, phrase_hash, phrase_cmp> Char_Phrase; 77 Char_Phrase phrasemap; 78 struct wordsdata *fourletter[26 * 26 * 26 * 26] = {}; //按首四字母排序 79 80 int main() 81 { 82 int j = 0; 83 long handle = 0; // 用于查找的句柄 84 struct _finddata_t fileinfo; // 文件信息的结构体 85 char *path = __argv[1]; 86 87 getfiles(path, &fileinfo, handle); 88 89 gettop(fourletter); 90 91 system("pause"); 92 return 1; 93 } 94 95 int getfiles(char *path, struct _finddata_t *fileinfo, long handle) 96 { 97 handle = _findfirst(path, fileinfo); //第一次打开父目录 98 if (handle == -1) 99 return -1; 100 101 102 do 103 { 104 //printf("> %s\\n", path); //显示目录名 105 106 if (fileinfo->attrib & _A_SUBDIR) //如果读取到子目录 107 { 108 if (strcmp(fileinfo->name, ".") != 0 && strcmp(fileinfo->name, "..") != 0) 109 { 110 char temppath[1024] = ""; //记录子目录路径 111 long temphandle = 0; 112 struct _finddata_t tempfileinfo; 113 strcpy(temppath, path); 114 strcat(temppath, "/*"); 115 116 temphandle = _findfirst(temppath, &tempfileinfo); //第一次打开子目录 117 if (temphandle == -1) 118 return -1; 119 120 do //对子目录所有文件递归 121 { 122 if (strcmp(tempfileinfo.name, ".") != 0 && strcmp(tempfileinfo.name, "..") != 0) 123 { 124 strcpy(temppath, path); 125 strcat(temppath, "/"); 126 strcat(temppath, tempfileinfo.name); 127 getfiles(temppath, &tempfileinfo, temphandle); 128 } 129 } while (_findnext(temphandle, &tempfileinfo) != -1); 130 131 _findclose(temphandle); 132 }//递归完毕 133 134 } //子目录读取完毕 135 else 136 getwords(path, fourletter); 137 138 139 } while (_findnext(handle, fileinfo) != -1); 140 141 _findclose(handle); //关闭句柄 142 143 return 1; 144 145 } 146 147 int getwords(char *path, struct wordsdata **word) 148 { 149 FILE *fp; 150 int j = 0; 151 int cmp = 0; 152 int num = 0; //计算首四位地址 153 char temp = 0; //读取一个字符 ACSII 码值 154 int length = 0; 155 156 char present[1024] = ""; //存储当前单词 157 158 char address[4] = ""; 159 struct wordsdata *q = NULL; 160 struct wordsdata *pre = NULL; 161 struct wordsdata *neword = NULL; 162 struct wordsdata *now = NULL; 163 struct wordsdata *previous = NULL; 164 struct phrases *newphrase = NULL; 165 166 if ((fp = fopen(path, "r")) == NULL) 167 { 168 //printf("error!!! \\n", path); 169 return 0; 170 } 171 linenum++; 172 while (temp != -1) 173 { 174 //读取字符串 175 temp = fgetc(fp); 176 if (temp > 31 && temp < 127) 177 charnum++; 178 if (temp == ‘\\n‘ || temp == ‘\\r‘) 179 linenum++; 180 181 while ((temp >= ‘0‘ && temp <= ‘9‘) || (temp >= ‘a‘ && temp <= ‘z‘) || (temp >= ‘A‘ && temp <= ‘Z‘)) 182 { 183 if (length != -1 && length < 4) 184 { 185 if (temp >= ‘A‘) //是字母 186 { 187 present[length] = temp; 188 address[length] = (temp >= ‘a‘ ? (temp - ‘a‘) : (temp - ‘A‘)); 189 length++; 190 } 191 else //不是字母 192 length = -1; 193 } 194 else if (length >= 4) 195 { 196 present[length] = temp; 197 length++; 198 } 199 temp = fgetc(fp); 200 if (temp > 31 && temp < 127) 201 charnum++; 202 if (temp == ‘\\n‘ || temp == ‘\\r‘) 203 linenum++; 204 } // end while 205 206 //判断是否为单词 207 if (length >= 4) 208 { 209 wordnum++; 210 211 //计算首四位代表地址 212 num = address[0] * 17576 + address[1] * 676 + address[2] * 26 + address[3]; 213 214 //插入当前单词 215 if (word[num] == NULL) 216 { 217 word[num] = new wordsdata; 218 neword = new wordsdata; 219 neword->number = 1; 220 neword->next = NULL; 221 strcpy(neword->words, present); 222 word[num]->next = neword; 223 now = neword; 224 } 225 else 226 { 227 pre = word[num]; 228 q = pre->next; 229 cmp = wordcmp(q->words, present); 230 231 while (cmp == small) 232 { 233 pre = q; 234 q = q->next; 235 if (q != NULL) 236 cmp = wordcmp(q->words, present); 237 else 238 break; 239 } 240 if (q != NULL && cmp <= 1) 241 { 242 now = q; 243 q->number++; 244 if (cmp == 1) 245 strcpy(q->words, present); 246 } 247 248 else 249 { 250 neword = new wordsdata; 251 neword->number = 1; 252 strcpy(neword->words, present); 253 pre->next = neword; 254 neword->next = q; 255 now = neword; 256 } 257 } 258 259 if (previous != NULL) 260 { 261 newphrase = new phrases; 262 263 newphrase->tw = now->words; 264 newphrase->one = previous->words; 265 266 unordered_map<phrases, int>::const_iterator got = phrasemap.find( *newphrase); 267 if (got != phrasemap.end()) 268 { 269 phrasemap[*newphrase]++; 270 } 271 else 272 { 273 phrasemap.insert(pair<phrases, int>(*newphrase, 1)); 274 } 275 } 276 previous = now; 277 278 //当前单词置空 279 for (int j = 0; present[j] && j < 1024; j++) 280 present[j] = 0; 281 } 282 length = 0; 283 } 284 285 fclose(fp); 286 return 1; 287 } 288 289 int wordcmp(char *str1, char *str2) 290 { 291 char *p1 = str1; 292 char *p2 = str2; 293 char q1 = *p1; 294 char q2 = *p2; 295 296 if (q1 >= ‘a‘ && q1 <= ‘z‘) 297 q1 -= 32; 298 299 if (q2 >= ‘a‘ && q2 <= ‘z‘) 300 q2 -= 32; 301 302 while (q1 && q2 && q1 == q2) 303 { 304 p1++; 305 p2++; 306 307 q1 = *p1; 308 q2 = *p2; 309 310 if (q1 >= ‘a‘ && q1 <= ‘z‘) 311 q1 -= 32; 312 313 if (q2 >= ‘a‘ && q2 <= ‘z‘) 314 q2 -= 32; 315 } 316 317 while (*p1 >= ‘0‘ && *p1 <= ‘9‘) 318 p1++; 319 while (*p2 >= ‘0‘ && *p2 <= ‘9‘) 320 p2++; 321 322 if (*p1 == 0 && *p2 == 0) //两单词等价 323 return strcmp(str1, str2); //等价前者字典顺序小返回-1,大返回1,完全相等返回0 324 325 if (q1 < q2) //前者小 326 return 2; 327 328 if (q1 > q2) //后者小 329 return 3; 330 331 return 4; 332 } 333 334 int gettop(struct wordsdata **word) 335 { 336 int i = 0, j = 0; 337 struct wordsdata *topw[12] = {}; 338 struct phrases *toph[12] = {}; 339 struct wordsdata *w = NULL; 340 FILE *fp; 341 fp = fopen("result.txt", "w"); 342 fprintf(fp,"characters:%d \\nwords:%d \\nlines:%d\\n", charnum,wordnum, linenum); 343 344 for (j = 0; j < 12; j++) 345 { 346 toph[j] = new struct phrases; 347 toph[j]->num = 0; 348 topw[j] = new struct wordsdata; 349 topw[j]->number = 0; 350 } 351 for (i = 0; i < 456976; i++) 352 { 353 if (word[i] != NULL) 354 { 355 w = word[i]->next; 356 while (w != NULL) 357 { 358 topw[11]->number = w->number; 359 topw[11]->next = w; 360 j = 11; 361 while (j > 1 && topw[j]->number > topw[j - 1]->number) 362 { 363 topw[0] = topw[j]; 364 topw[j] = topw[j - 1]; 365 topw[j - 1] = topw[0]; 366 j--; 367 } 368 w = w->next; 369 } 370 } 371 } 372 for (j = 1; j < 11; j++) 373 { 374 if (topw[j]->number) 375 fprintf(fp,"\\n%s :%d", topw[j]->next->words, topw[j]->number); 376 } 377 for (Char_Phrase::iterator it = phrasemap.begin(); it != phrasemap.end(); it++) 378 { 379 toph[11]->one = it->first.one; 380 toph[11]->tw = it->first.tw; 381 toph[11]->num = it->second; 382 j = 11; 383 while (j > 1 && toph[j]->num > toph[j - 1]->num) 384 { 385 toph[0] = toph[j]; 386 toph[j] = toph[j - 1]; 387 toph[j - 1] = toph[0]; 388 j--; 389 } 390 } 391 fprintf(fp, "\\n"); 392 for (j = 1; j < 11; j++) 393 { 394 if (toph[j]->num) 395 fprintf(fp,"\\n%s %s :%d", toph[j]->one, toph[j]->tw, toph[j]->num); 396 } 397 fclose(fp); 398 return 1; 399 }