结对编程第4小组-词频统计
Posted mzfeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结对编程第4小组-词频统计相关的知识,希望对你有一定的参考价值。
(项目源代码路径:https://github.com/miaozhongfeng/PairProject2018.git)
一、PSP表格预估时间花费
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
||
|
· Estimate |
· 估计这个任务需要多少时间 |
30 |
30 |
|
Development |
开发 |
||
|
· Analysis |
· 需求分析 (包括学习新技术) |
30 |
30 |
|
· Design Spec |
· 生成设计文档 |
15 |
10 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
15 |
10 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
15 |
10 |
|
· Design |
· 具体设计 |
30 |
50 |
|
· Coding |
· 具体编码 |
60 |
110 |
|
· Code Review |
· 代码复审 |
30 |
60 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
30 |
50 |
|
Reporting |
报告 |
||
|
· Test Report |
· 测试报告 |
15 |
10 |
|
· Size Measurement |
· 计算工作量 |
15 |
10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
15 |
15 |
|
合计 |
300 |
395 |
二、计算模块接口的设计与实现过程
根据基本需求进行分析,需要实现统计文本总字符数、统计特定单词数、统计各单词出现频率并写入文件。所以我们小组在设计结构时设计了3个类:CountStr、CountWord、WordsRate分别实现3个模块功能。
(1)在CountStr类中,设计了coutAllNumber(char*inputfilename)方法,用于文本字符统计。在实现该功能时,使用open()方法打开文本,在eof()返回值为false时统计变量自增。
(2)在CountWord类中,设计了countWord(char*inputfile)方法,用于统计文本中单词个数。在该函数中,使用String类型变量接收读取的字符(包括空格),使用vector容器存放单词,最终返回容器大小。
(3)在WordsRate类中,设计了display_map(map<string, int> &wmap)方法,用于统计词频并写入文本,采用Map映射方式,其中排序使用了sort()函数实现。但是由于sort()函数无法直接对map排序,需要先将map用vector容器接收,在用sort()对vector容器的内容进行排序,排序参数为cmp,定义为Value值按从大到小排序。关键代码如下:
map<string, int>::const_iterator map_it; map<string, int>::iterator iter_it; vector<PAIR>vec_it; for (iter_it = wmap.begin(); iter_it != wmap.end();iter_it++) { vec_it.push_back(*iter_it); } sort(vec_it.begin(), vec_it.end(), cmp());
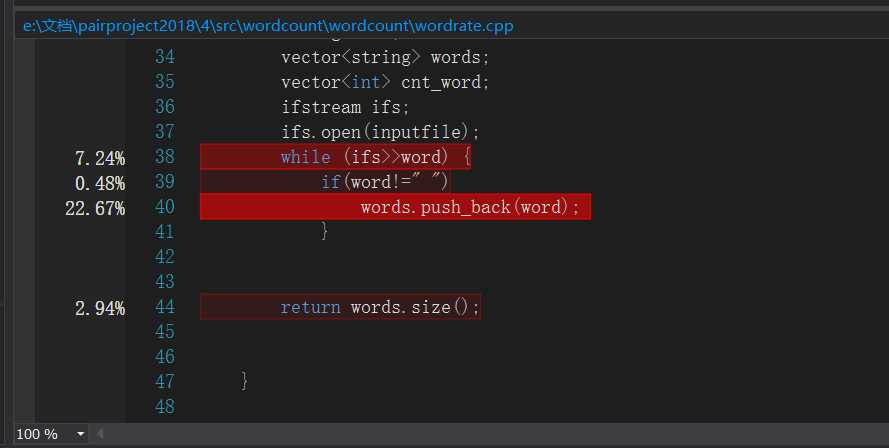
三、性能分析
通过性能分析工具得出耗时最大的函数为countword(),主要耗费在读取字符和放入容器的语句上,如下图:
四、结对编程总结
结对编程的优点是:一个人的思维有限,结对编程双方可以相互学习,相互提高,集两人之智商讨问题解决方案;结对编程的缺点是双方的编程习惯不同,在少数问题上就会产生1+1<2的情形,降低了效率。苗助教的优点:接受新知识能力快;对库函数的运用熟练; 善于总结问题。
以上是关于结对编程第4小组-词频统计的主要内容,如果未能解决你的问题,请参考以下文章