机器学习之Knn(K-近邻算法)
Posted monologuesmw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之Knn(K-近邻算法)相关的知识,希望对你有一定的参考价值。
Contents
- KNN算法简介
- 算法实现
- 总结
KNN算法简介
k近邻算法(k-nearest neighbor)是一种基本的分类、回归算法。
算法的基本思想是“物以类聚”。也就是说,物体周边事物的类别可以在某种程度上反应该物体的类别。例如,可以通过了解你身边最亲密的几个朋友来了解你的性格;又或者一部电影中某类镜头出现的频率高,会把该类电影归纳为与之对应类型的电影。
因此,knn算法在分类时,对于新的实例,会根据其k个最近邻实例的类别,通过多数表决的方式进行预测,也就是少数服从多数。在实际使用中,就是找k个邻居,通过邻居的类别来决定自身的类别。具体来说,训练数据将作为已知标签的实例分布在特征空间中,作为分类的“模型”。测试数据在训练数据构成的样本空间中寻找k个距离最近的实例,通过这些实例的类别确定该测试样本的类别。从中可以看出,knn算法虽然属于监督学习的算法,但不具有显式的学习过程。对于训练数据依赖程度比较大 。
通过上述描述,knn算法的精度主要取决于:
- k值的选择
- 距离的度量
- 分类决策规则
也被称之为三个基本要素。
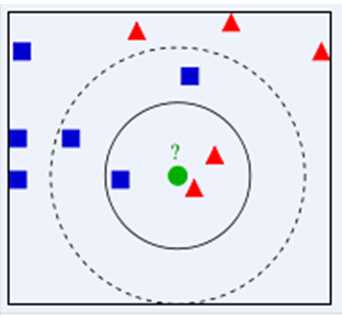
例如,下图中对于绿色的测试样本,如果k取3,那么它将被归为红色三角形那一类;如果k取5,则它将被归为蓝色正方形那一类。k值的选择会对knn算法的结果产生重大影响。
- k值较小,相当于用较小的邻域中的训练实例进行分类,如果临近的恰好是噪声,则容易出错,容易过拟合;
- k值较大时,与训练实例较远的(不相似的)也会对分类起作用,影响分类的效果。并且当k=N(训练样本数据个数)时,这时无论输入实例是什么,都会简单的将其归为训练样本数据中最多的类。
因此,k值一般取一个较小的数值。
距离的度量有很多种方式,例如闵可夫斯基距离,欧式距离,切比雪夫距离,绝对值距离,曼哈顿距离等。
分类决策规则主要包括:
- 投票决定的少数服从多数
- 加权投票(距离作为权重)
算法的具体流程可以描述为:
- 算距离,对测试样本计算起到各训练样本的距离;
- 找邻居,找最近的k个邻居; (k值的确定往往通过交叉验证的方式来确定)
- 做分类,根据k个邻居的类别做判断。
算法实现
在python3.6下,使用knn算法对经典数据集鸢尾花iris进行分类
1. 数据准备
1 import numpy as np, pandas as pd 2 import scipy.io as scio 3 import matplotlib.pyplot as plt 4 # 数据准备 5 data = scio.loadmat(‘iris_data.mat‘) # 读出来的是字典格式 6 dataFeatures = data.get(‘features‘) # features classes 是data字典中的一个键 7 dataLabels = data.get(‘classes‘) 8 a, b = dataFeatures.shape
2. Knn分类
1 # KNN分类 2 def KnnClassify(inX, dataSet, labels, k): 3 ‘‘‘ 4 Knn实现分类的程序: 5 1. 首先计算测试数据集与训练数据集之间的距离: 6 训练数据集的行数 7 计算距离 numpy中有一个样本延展的方法.tile 可以将输入样本延展复制训练样本份 8 然后直接减 就可以直接算出一个测试样本与所有训练样本各个维度的距离 9 2. 对样本进行排序,获得排序后的索引:argsort 最大的序号 第一个位置 10 3. 根据序号,选取k个 对应的标签 11 并统计标签的次数 + 1 用字典 12 4. 获取上述统计结果中最大的标签 --》 字典按照值排序 13 5. 返回结果 --》最大的标签 14 15 :param inX: 输入的需要分类的数据 只能是1行的数据 16 :param dataSet: 训练集的特征 17 :param labels: 训练集的标签 18 :param k: Knn中的最近邻 K值 19 :return: 分类结果 20 ‘‘‘ 21 # 1. 获取训练集的行数 22 dataSetSize = dataSet.shape[0] 23 # 2. 计算测试集数据与训练集数据之间的距离 24 diff = np.tile(inX, (dataSetSize, 1)) - dataSet 25 sqdiff = diff**2 26 sqDistance = sqdiff.sum(axis=1) 27 distance = sqDistance**0.5 28 # 3. 进行排序 选择距离最小的k个点 29 sortDistanceIndex = distance.argsort() # 获取排序结果的索引 30 classCount = {} 31 for i in range(k): 32 votelLabel = labels[sortDistanceIndex[i]][0] # 获取前k个的类别标签 33 classCount[votelLabel] = classCount.get(votelLabel, 0)+1 # 统计了k个最近邻类别出现的次数 34 # 4. 统计这k个点的类别, 35 # max(classCount, key=classCount.get()) # 获取字典中值最大的键 36 result = sorted(classCount.items(), key=lambda x: x[1]) # 按照值,排序 37 return result[0][0]
3. 调用接口
1 # 调用接口 2 def dataClassTest(data, labels, ratio, k): 3 ‘‘‘ 4 为方便调用,此处做一个调用接口 5 :param data: 整个数据 不带标签的 6 :param labels: 整个数据的标签 7 :param ratio: 训练样本的比率 8 :param k: Knn中最近邻K值 9 :return: 分类结果,错分个数,准确率 10 ‘‘‘ 11 # 1.获取整个数据集,包括训练数据、测试数据的行数 12 rows = data.shape[0] 13 trainDataNum = int(rows*ratio) # 训练数据集的行数 14 testDataNum = rows - trainDataNum # 测试数据集的行数 15 errorCount = 0.0 # 错分概率初始化 16 resultCount = [] 17 for i in range(testDataNum): 18 result = KnnClassify(data[trainDataNum+i], data[0:trainDataNum], labels[0:trainDataNum], k) 19 resultCount.append(result) 20 if result != labels[trainDataNum+i]: 21 errorCount += 1 22 bingorate = 1 - errorCount/testDataNum 23 return resultCount, errorCount, bingorate
4. 调用运行
1 esult, error, precision = dataClassTest(dataFeatures, dataLabels, 0.7, 13) 2 print(‘�33[93;1m分类结果为:�33[0m‘, result) 3 print(‘�33[94;1m分错个数为:�33[0m‘, error) 4 print(‘�33[91;1m准确率:�33[0m‘, precision) 5 6 # 画图显示 7 ‘‘‘通过数据特征集的显示,数据集的量程相差不大,可以不进行归一化‘‘‘ 8 # fig = plt.figure() 9 # ax = fig.add_subplot(311) 10 # ax.scatter(dataFeatures[:, 0], dataFeatures[:, 1], 15*np.array(dataLabels)) 11 # ax1 = fig.add_subplot(312) 12 # ax1.scatter(dataFeatures[:, 1], dataFeatures[:, 2], 15*np.array(dataLabels)) 13 # ax1 = fig.add_subplot(313) 14 # ax1.scatter(dataFeatures[:, 2], dataFeatures[:, 3], 15*np.array(dataLabels)) 15 # plt.show() 16 numtest = len(result) 17 fig1 = plt.figure() 18 plt.plot(range(numtest), result, ‘r*-‘) 19 plt.plot(range(numtest), dataLabels[-1-numtest+1:], ‘bx-‘) 20 plt.show()

总结
knn算法原理简单,容易实现。
优点:精度高、对异常值不敏感、无数据输入假定,可以多分类。
缺点:计算复杂度高、空间复杂度高。
以上是关于机器学习之Knn(K-近邻算法)的主要内容,如果未能解决你的问题,请参考以下文章