Kafka基础系列第2讲:Kafka技术架构剖析
Posted chanshuyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka基础系列第2讲:Kafka技术架构剖析相关的知识,希望对你有一定的参考价值。
使用过 Kafka 框架的朋友都知道,启动 Kafka 框架只需要两个关联的组件,分别是:Zookeeper 和 Kafka。如果你还没使用过 Kafka 框架,建议先阅读《Kafka 快速入门教程》把玩一下,对 Kafka 有一个感性的认识。
当我们熟悉了 Kafka 的使用之后,我们自然有一些疑惑:Kafka 到底是如何工作的?消息从生产者到 Kafka Server 这中间到底做了什么事情?而 Zookeeper Server 在这过程中有起到什么作用?带着这些疑问,今天我们来深入了解一下 Kafka 的工作机制。
我们先来看一下 Kafka 的架构图:
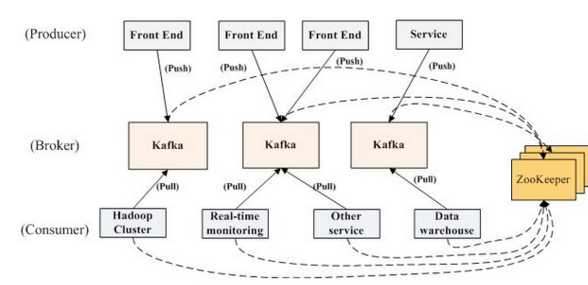
Kafka 的架构图可以分为四个部分:
- Producer Cluster:生产者集群。一般由许多个实际的业务项目组成,其不断地往 Kafka 集群中写入数据。
- Kafka Cluster:Kafka 服务器集群。这里就是 Kafka 作为重要的一部分,这里负责接收生产者写入的数据,并将其持久化到文件里,最终将消息提供给 Consumer Cluster。
- Zookeeper Cluster:Zookeeper 集群。Zookeeper 负责维护整个 Kafka 集群的 Topic 信息、Kafka Controller 等信息。
- Consumer Cluster:消费者集群。与 Producer Cluster 一样,其一般是由许多个实际的业务项目组成,不断地从 Kafka Cluster 中读取数据。
根据这个架构图,我们可以将一个消息的流转流程分为下面几个阶段:
- 服务器启动阶段
- 生产者发送消息阶段
- Kafka存储消息阶段
- 消费者拉取消息阶段
服务器启动阶段
首先,我们会启动 Zookeeper 服务器,作为集群管理服务器。
接着启动 Kafka Server,Kafka Server 会向 Zookeeper 服务器注册信息,接着启动线程池监听客户端的连接请求。(更详细的启动流程可以参考:)
接着启动消费端,连接到 Zookeeper 服务器,从 Zookeeper 服务器获取到对应的 Kafka Server 信息。
生产者发送消息阶段
当需要将消息存入消息队列中时,生产者根据配置的分片算法,选择分到哪一个 partition 中。在发送一条消息时,可以指定这条消息的 key,Producer 根据这个 key 和 Partition 机制来判断应该将这条消息发送到哪个 Parition。
Paritition 机制可以通过指定 Producer 的 paritition.class 这一参数来指定,该 class 必须实现 kafka.producer.Partitioner 接口。如果不实现 Partition 接口,那么会使用默认的分区算法,即根据根据 key 哈希后取余[4]。
随后生产者与该 Partition Leader 建立联系,之后将消息发送至该 partition leader。之后生产者会根据设置的 request.required.acks 参数不同,选择等待或或直接发送下一条消息。
- request.required.acks = 0 表示 Producer 不等待来自 Leader 的 ACK 确认,直接发送下一条消息。在这种情况下,如果 Leader 分片所在服务器发生宕机,那么这些已经发送的数据会丢失。
- request.required.acks = 1 表示 Producer 等待来自 Leader 的 ACK 确认,当收到确认后才发送下一条消息。在这种情况下,消息一定会被写入到 Leader 服务器,但并不保证 Follow 节点已经同步完成。所以如果在消息已经被写入 Leader 分片,但是还未同步到 Follower 节点,此时Leader 分片所在服务器宕机了,那么这条消息也就丢失了,无法被消费到。
- request.required.acks = -1 表示 Producer 等待来自 Leader 和所有 Follower 的 ACK 确认之后,才发送下一条消息。在这种情况下,无论什么情况都不会发生消息的丢失,除非所有 Follower 节点都宕机了。
Kafka存储消息阶段
当 Kafka 接收到消息后,其并不直接将消息写入磁盘,而是先写入内存中。之后根据生产者设置参数的不同,选择是否回复 ack 给生产者。之后有一个线程会定期将内存中的数据刷入磁盘,这里有两个参数控制着这个过程:
# 数据达到多少条就将消息刷到磁盘
#log.flush.interval.messages=10000
# 多久将累积的消息刷到磁盘,任何一个达到指定值就触发写入
#log.flush.interval.ms=1000如果我们设置 log.flush.interval.messages=1,那么每次来一条消息,就会刷一次磁盘。通过这种方式,就可以达到消息绝对不丢失的目的,这种情况我们称之为同步刷盘。反之,我们称之为异步刷盘。
于此同时,Kafka 服务器也会进行副本的复制,该 Partition 的 Follower 会从 Leader 节点拉取数据进行保存。然后将数据存储到 Partition 的 Follower 节点中。
消费者拉取消息阶段
在消费者启动时,其会连接到 zk 注册节点,之后根据所连接 topic 的 partition 个数和消费者个数,进行 partition 个数。一个 partition 最多只能被一个线程消费,但一个线程可以消费多个 partition。其分配算法如下:

我简单描述下这个算法的内容,假设我们连接的 topic 有 8 个 partition,此时有 3 个消费线程。那么气分配故城大致是这样的:
- 8/3=2.667,向上取整就是3。
- 那么给第一个消费者分配p0/p1/p2三个分区。
- 给第二个消费者分配p3/p4/p5三个分区。
- 给第三个消费者分配p6/p7两个分区。
接着消费者连接对应的分区,并从该分区服务器拉取数据。这里其实还会涉及到一个叫做「Zero Copy」的知识点,正是因为使用了「Zero Copy」技术才使得 Kafka 的吞吐量如此之高。
总结
从生产者到 Kafka,从 Kafka 到存储以及副本,再从 Kafka 到消费者。了解这整个过程可以让我们更好地理解 Kafka 消息队列。
参考资料
- Kafka 设计解析(一):Kafka 背景及架构介绍
- Kafka 设计解析(二):Kafka High Availability (上)
- Kafka 设计解析(三):Kafka High Availability (下)
- kafka broker启动流程和server结构
- [4].kafka发送消息分区选择策略详解
以上是关于Kafka基础系列第2讲:Kafka技术架构剖析的主要内容,如果未能解决你的问题,请参考以下文章
聊聊 Kafka:协调者 GroupCoordinator 源码剖析之实例化与启动 GroupCoordinator
聊聊 Kafka:协调者 GroupCoordinator 源码剖析之实例化与启动 GroupCoordinator