聊聊 Kafka:协调者 GroupCoordinator 源码剖析之实例化与启动 GroupCoordinator
Posted 老周聊架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊 Kafka:协调者 GroupCoordinator 源码剖析之实例化与启动 GroupCoordinator相关的知识,希望对你有一定的参考价值。
一、前言
在聊聊 Kafka 系列专栏中,我们前面讲了一篇 聊聊 Kafka: Consumer 源码解析之 Consumer 如何加入 Consumer Group,其实那一篇主要讲的是客户端 Consumer 加入组请求、加入组响应、同步组请求、同步组响应等操作,我们这一篇主要来讲服务端侧协调者 GroupCoordinator 处理的请求。服务端处理客户端请求的入口都是 KafkaApis 类,它会根据不同的请求类型分发给不同的方法处理。如下图:
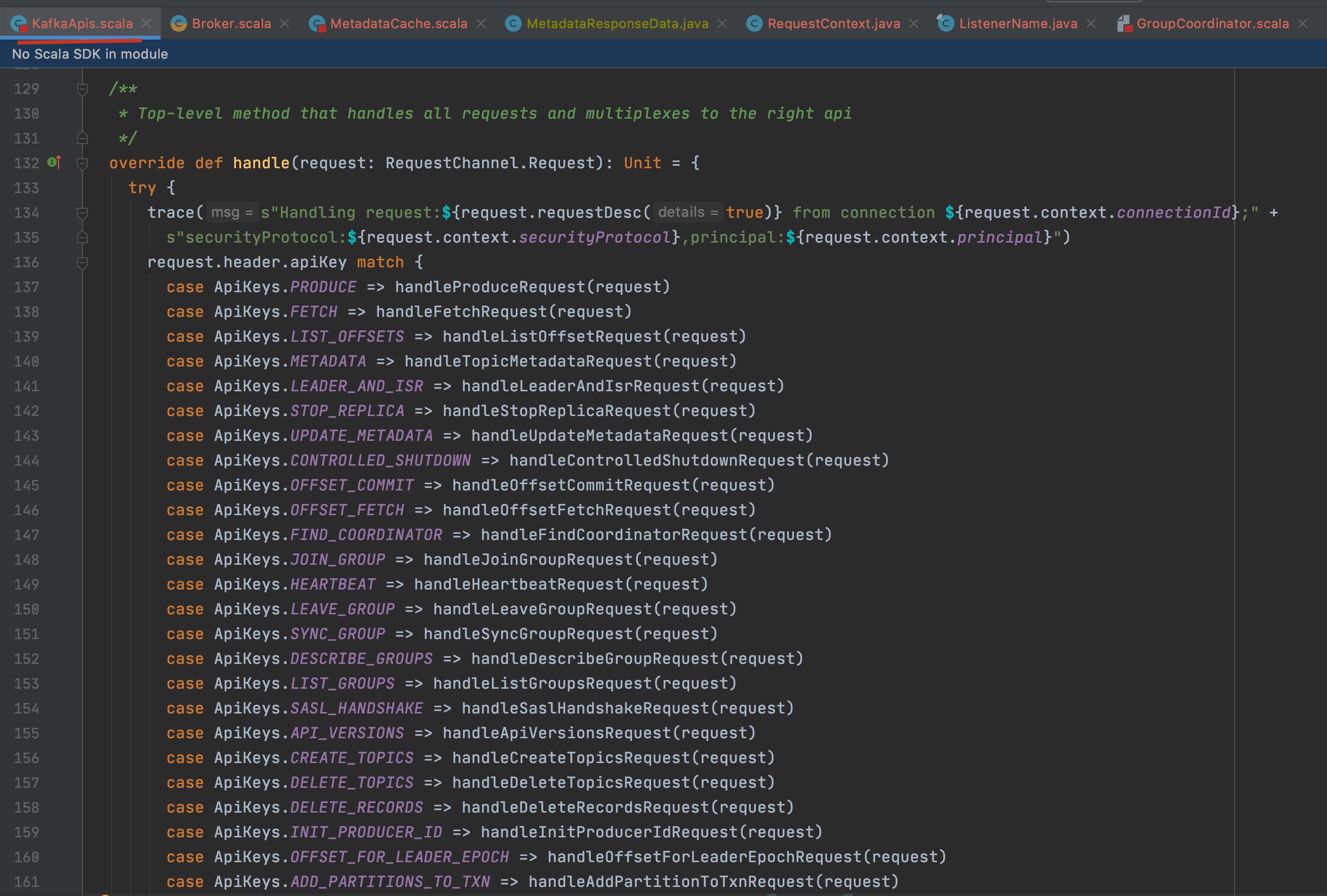
二、主要处理流程
GroupCoordinator 主要有四大类处理的命令:COORDINATOR、GROUP、OFFSET、HEARTBEAT,具体命令如下:
COORDINATOR 命令:
- ApiKeys.FIND_COORDINATOR
GROUP 命令:
- ApiKeys.JOIN_GROUP
- ApiKeys.LEAVE_GROUP
- ApiKeys.SYNC_GROUP
- ApiKeys.DESCRIBE_GROUPS
- ApiKeys.LIST_GROUPS
- ApiKeys.DELETE_GROUPS
OFFSET 命令:
- ApiKeys.OFFSET_COMMIT
- ApiKeys.OFFSET_FETCH
- ApiKeys.OFFSET_FOR_LEADER_EPOCH
- ApiKeys.OFFSET_DELETE
HEARTBEAT 命令:
- ApiKeys.HEARTBEAT
我们下面针对主要的几个命令来进行源码剖析:
三、GroupCoordinator
对主要命令分析之前,我们还是先来看下协调者 GroupCoordinator 的主要数据结构以及它如何维护管理组成员关系的。
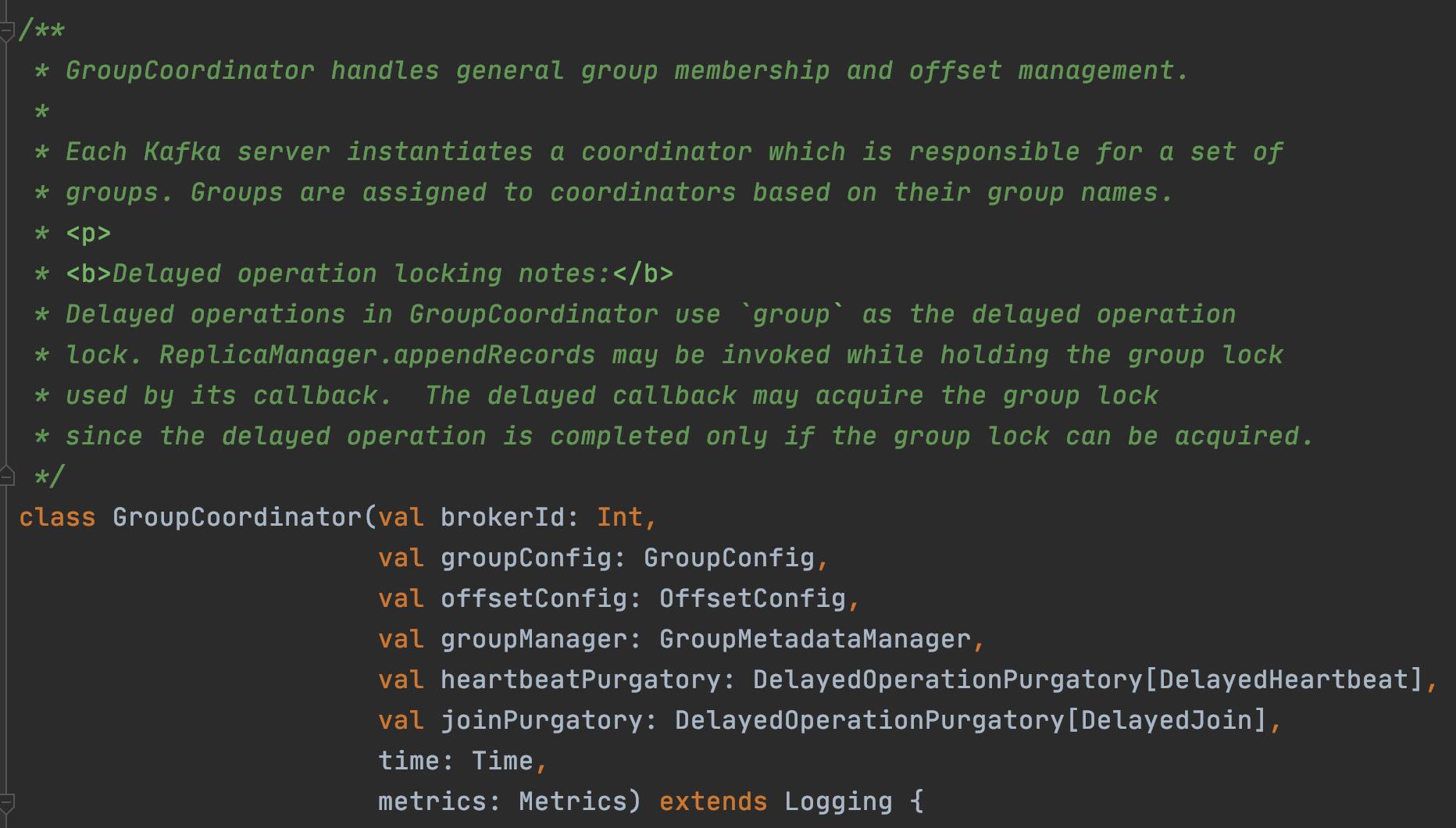
直接看注释不难得出:
- GroupCoordinator 处理群组成员关系和偏移管理
- GroupCoordinator 中的延迟操作使用 “group” 作为延迟操作锁
我们直接从入口开始看
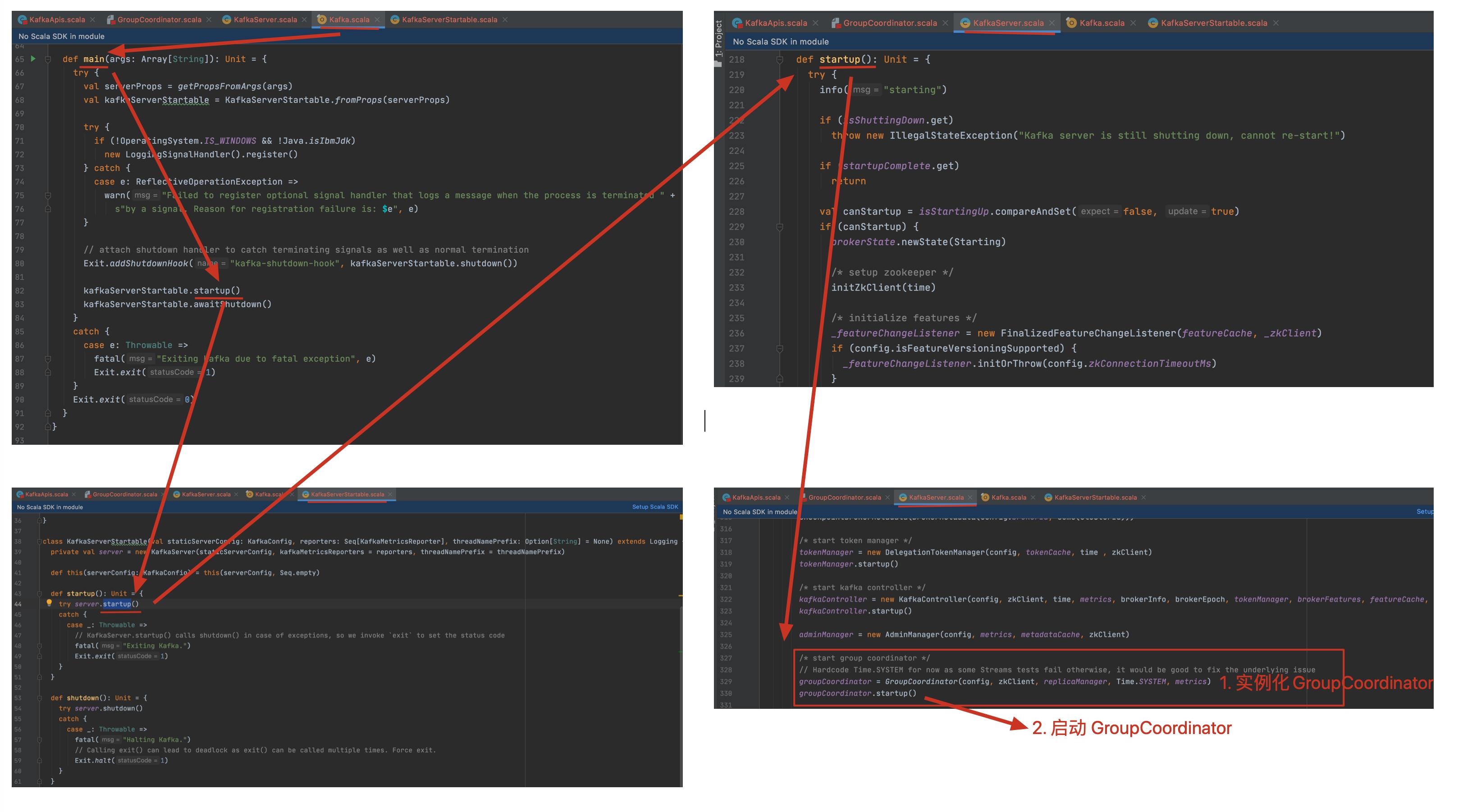
3.1 实例化 GroupCoordinator
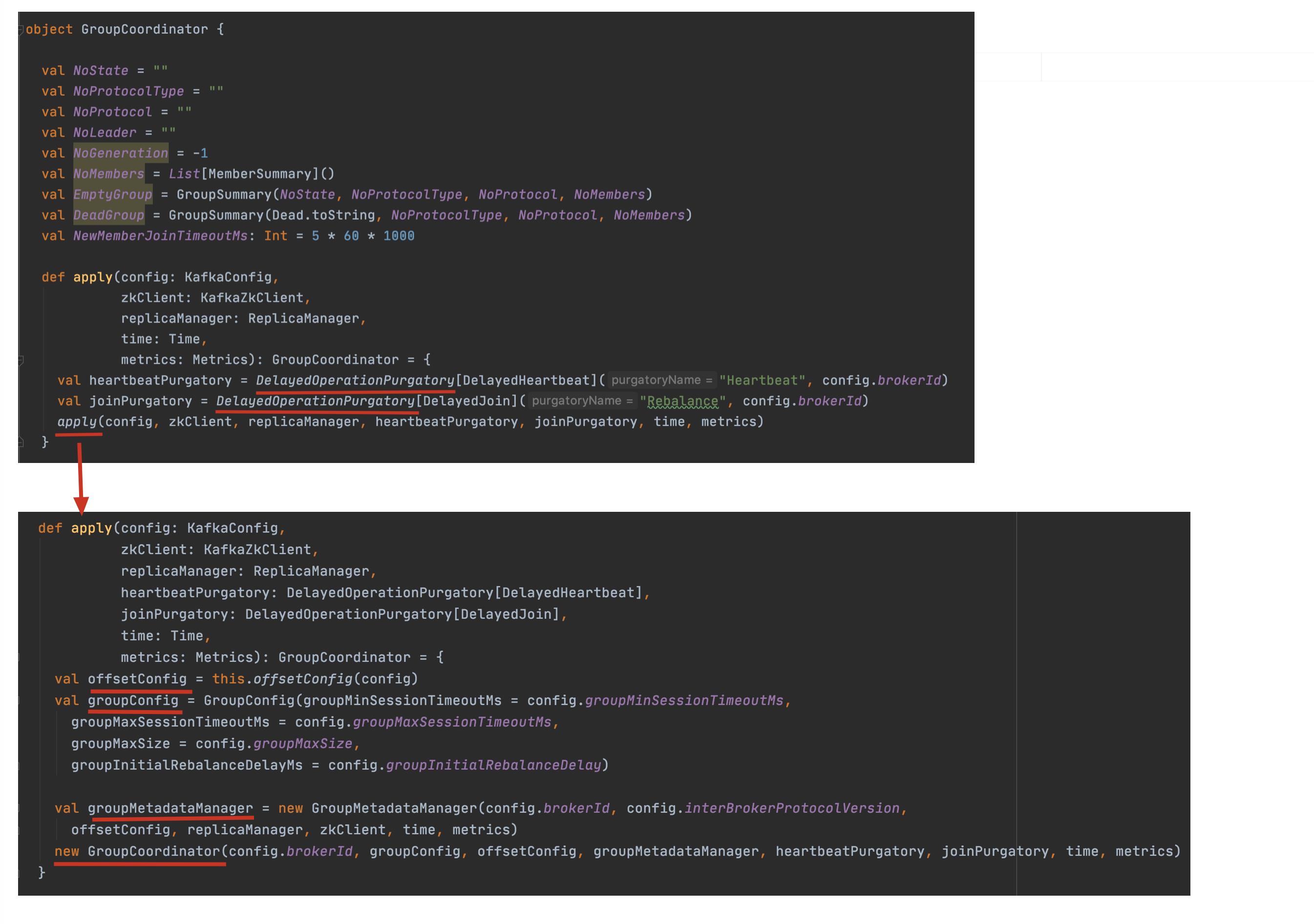
- 创建了两个 DelayedOperationPurgatory,主要是用于延迟队列操作关于:Heartbeat、Rebalance。
- 关于 offset、group 的配置信息加载:offsetConfig、groupConfig。
- 初始化 GroupMetadataManager group 元数据管理器
- 返回 GroupCoordinator 实例
3.2 启动 GroupCoordinator

上面实例化 GroupCoordinator 的时候会初始化 GroupMetadataManager group 元数据管理器,启动 GroupCoordinator 的时候也会 GroupMetadataManager 的 startup 方法,所以不难看出 GroupCoordinator 的功能部分应该是靠的 GroupMetadataManager 这个管理器,那么我们来看下 GroupMetadataManager 中有哪些信息或组件:
3.2.1 GroupMetadataManager 元数据
class GroupMetadataManager(brokerId: Int,
interBrokerProtocolVersion: ApiVersion,
config: OffsetConfig,
// replicaManager 对象,管理 __consumer_offsets
val replicaManager: ReplicaManager,
zkClient: KafkaZkClient,
time: Time,
metrics: Metrics) extends Logging with KafkaMetricsGroup
private val compressionType: CompressionType = CompressionType.forId(config.offsetsTopicCompressionCodec.codec)
// 记录每个 group 在服务端对应的 GroupMetadata 对象
private val groupMetadataCache = new Pool[String, GroupMetadata]
/* lock protecting access to loading and owned partition sets */
private val partitionLock = new ReentrantLock()
/* partitions of consumer groups that are being loaded, its lock should be always called BEFORE the group lock if needed */
// 记录了正在加载的 offsets topic 分区的 ID
private val loadingPartitions: mutable.Set[Int] = mutable.Set()
/* partitions of consumer groups that are assigned, using the same loading partition lock */
// 记录了已经加载的 offsets topic 分区的 ID
private val ownedPartitions: mutable.Set[Int] = mutable.Set()
/* shutting down flag */
private val shuttingDown = new AtomicBoolean(false)
/* number of partitions for the consumer metadata topic */
// 记录 offsets topic 的分区数量,这个字段会调用 getGroupMetadataTopicPartitionCount() 进行初始化,默认 50。
private val groupMetadataTopicPartitionCount = getGroupMetadataTopicPartitionCount
/* single-thread scheduler to handle offset/group metadata cache loading and unloading */
// 处理偏移、组元数据缓存加载和卸载
private val scheduler = new KafkaScheduler(threads = 1, threadNamePrefix = "group-metadata-manager-")
/* The groups with open transactional offsets commits per producer. We need this because when the commit or abort
* marker comes in for a transaction, it is for a particular partition on the offsets topic and a particular producerId.
* We use this structure to quickly find the groups which need to be updated by the commit/abort marker. */
// 代表 transactional 有关的 producer 对应的 offset 记录
private val openGroupsForProducer = mutable.HashMap[Long, mutable.Set[String]]()
/* setup metrics*/
private val partitionLoadSensor = metrics.sensor(GroupMetadataManager.LoadTimeSensor)
...
3.2.2 GroupMetadata 元数据
@nonthreadsafe
private[group] class GroupMetadata(val groupId: String, initialState: GroupState, time: Time) extends Logging
type JoinCallback = JoinGroupResult => Unit
private[group] val lock = new ReentrantLock
private var state: GroupState = initialState
var currentStateTimestamp: Option[Long] = Some(time.milliseconds())
var protocolType: Option[String] = None
var protocolName: Option[String] = None
var generationId = 0
private var leaderId: Option[String] = None
// 成员的集合
private val members = new mutable.HashMap[String, MemberMetadata]
// Static membership mapping [key: group.instance.id, value: member.id]
private val staticMembers = new mutable.HashMap[String, String]
private val pendingMembers = new mutable.HashSet[String]
private var numMembersAwaitingJoin = 0
private val supportedProtocols = new mutable.HashMap[String, Integer]().withDefaultValue(0)
// 每个 topic-partition 对应的 CommitRecordMetadataAndOffset (这个里面含有 offset 的 long 值、OffsetAndMetadata [offset 提交的时间戳、offset 超时的时间戳])
private val offsets = new mutable.HashMap[TopicPartition, CommitRecordMetadataAndOffset]
private val pendingOffsetCommits = new mutable.HashMap[TopicPartition, OffsetAndMetadata]
private val pendingTransactionalOffsetCommits = new mutable.HashMap[Long, mutable.Map[TopicPartition, CommitRecordMetadataAndOffset]]()
private var receivedTransactionalOffsetCommits = false
private var receivedConsumerOffsetCommits = false
// When protocolType == `consumer`, a set of subscribed topics is maintained. The set is
// computed when a new generation is created or when the group is restored from the log.
private var subscribedTopics: Option[Set[String]] = None
var newMemberAdded: Boolean = false
...
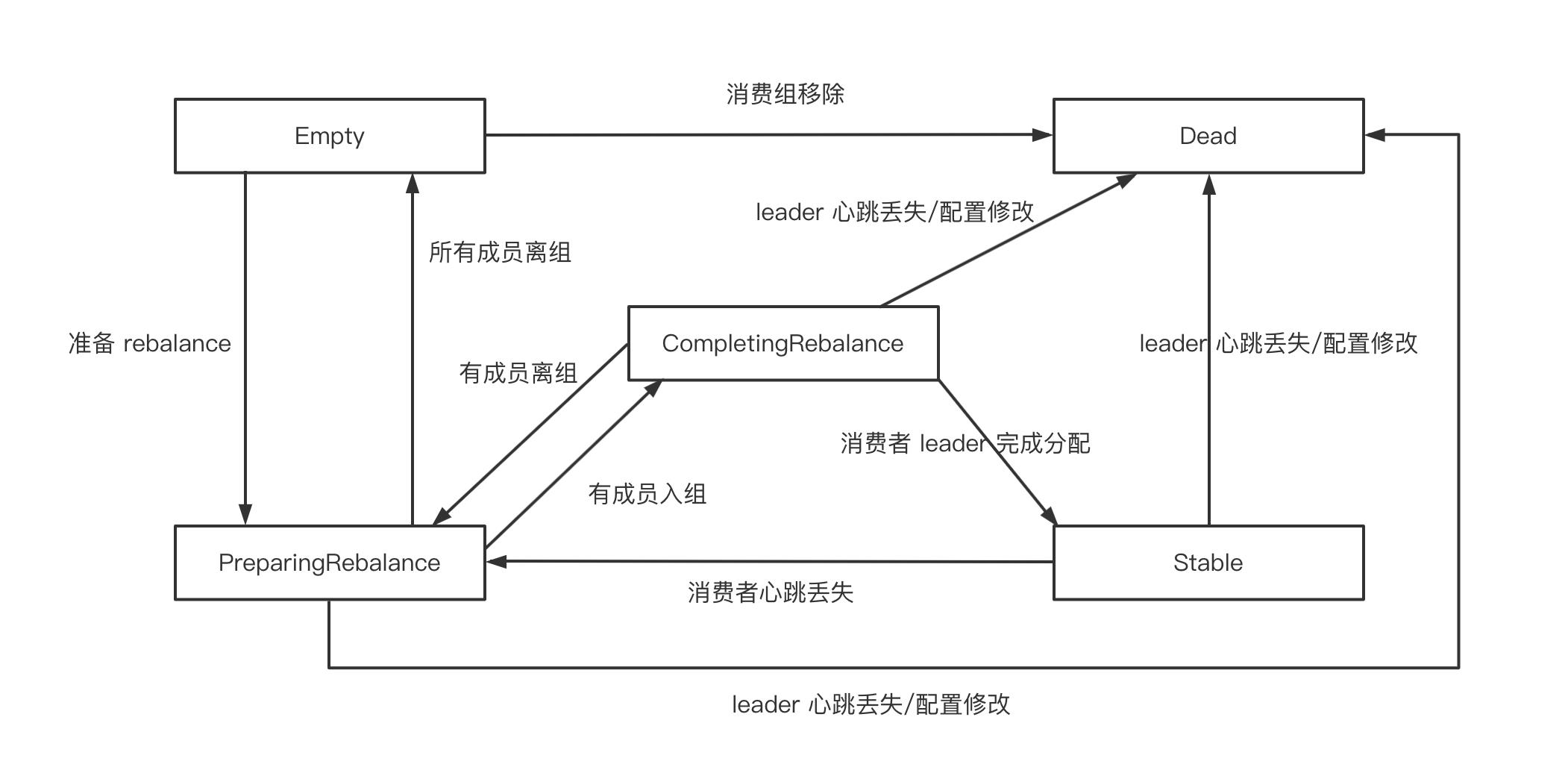
对于 Kafka 服务端的组,GroupState 有五种状态 Empty、PreparingRebalance、CompletingRebalance、Stable、Dead。他们的状态转换如下图所示:

3.2.3 启动 GroupCoordinator 具体的流程
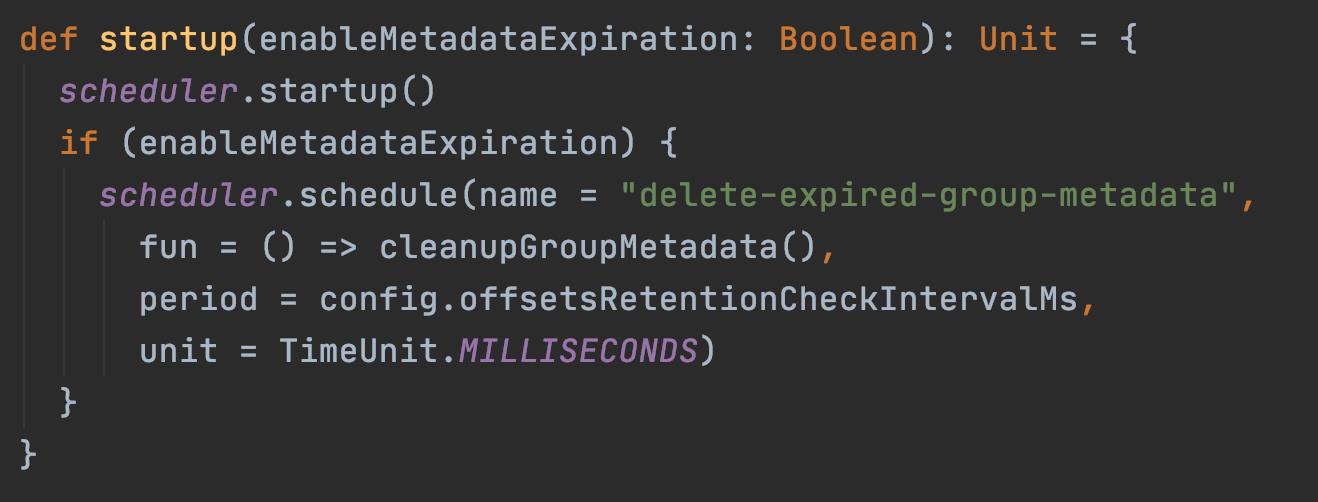
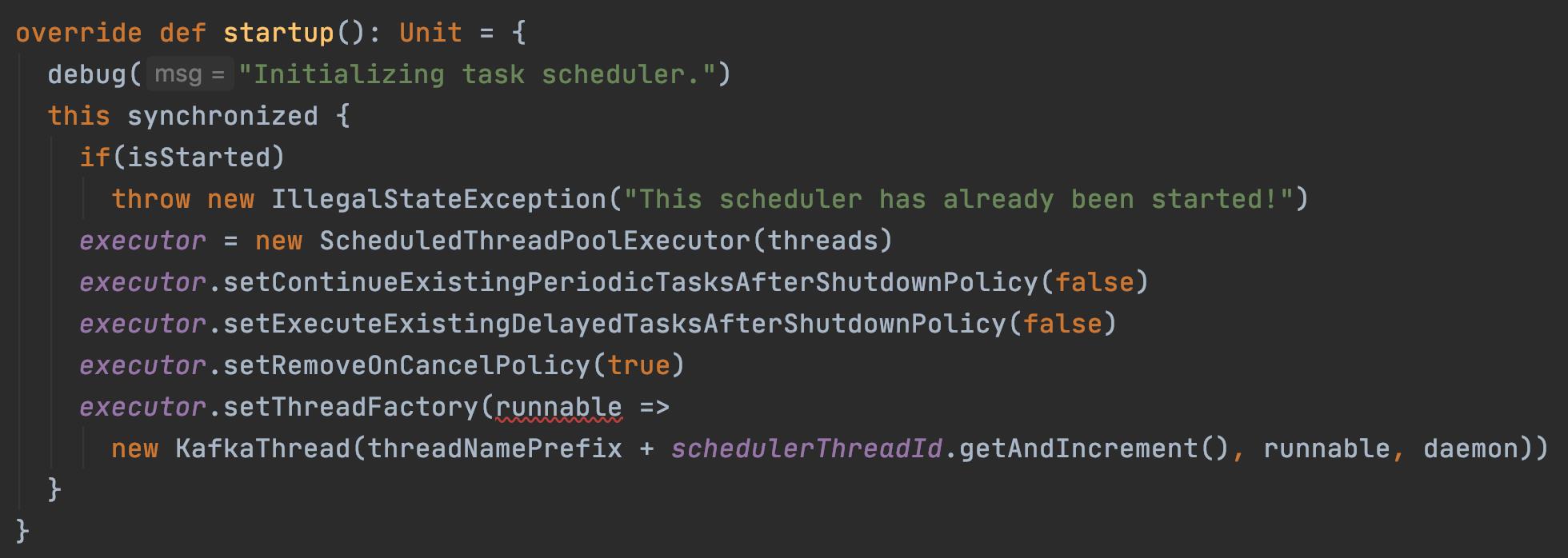
- 线程池 scheduler 启动
- 向 scheduler 中添加一个定时任务
delete-expired-group-metadata,用于清除过期的 group metadata。 - group.removeExpiredOffsets(currentTimestamp, config.offsetsRetentionMs)
- 将过期的记录从 offsets 中去除
- 将有效的记录返回 Map[TopicPartition, OffsetAndMetadata]
- 主要的函数 cleanupGroupMetadata(groups: Iterable[GroupMetadata], selector: GroupMetadata => Map[TopicPartition, OffsetAndMetadata])
- 遍历 groups 获取 group 即 GroupMetadata,从 selector 中获取对应的 OffsetAndMetadata,对 group 进行判断如下,为 true 则将 group 状态改为 Dead。
- group.is(Empty) && !group.hasOffsets
- 此时刚启动起来,没有成员加入,我们到此就打住了,实例化与启动 GroupCoordinator 就到这,后面有关状态的流转下篇再来分析。
假设一台 broker 启动了,然后服务端的 GroupCoordinator 在此时启动了。那么后面会发生什么?从 GroupMetadata 的状态变更可以看出来,一开始是 Empty 因为刚起来什么都没有。然后想要状态变更就有两个途径:新成员加入、超时过期。
我们这里看下新成员加入的场景,当前的服务端 GroupCoordinator 已启动了,一个新的消费者组过来了,首先需要找到这个 GroupCoordinator,即 FIND_COORDINATOR,然后发送加入的请求 JOIN_GROUP,再同步分区的分配信息 SYNC_GROUP。
我们下一篇来说一下找到这个 GroupCoordinator,即 FIND_COORDINATOR。
以上是关于聊聊 Kafka:协调者 GroupCoordinator 源码剖析之实例化与启动 GroupCoordinator的主要内容,如果未能解决你的问题,请参考以下文章
聊聊 Kafka:协调者 GroupCoordinator 源码剖析之实例化与启动 GroupCoordinator
聊聊 Kafka:协调者 GroupCoordinator 源码剖析之 FIND_COORDINATOR
聊聊 Kafka:协调者 GroupCoordinator 源码剖析之 FIND_COORDINATOR