spark join算子
Posted tele-share
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark join算子相关的知识,希望对你有一定的参考价值。
java
1 /**
2 *join算子是根据两个rdd的key进行关联操作,类似scala中的拉链操作,返回的新元素为<key,value>,一对一
3 *@author Tele
4 *
5 */
6 public class JoinDemo {
7 private static SparkConf conf = new SparkConf().setMaster("local").setAppName("joindemo");
8 private static JavaSparkContext jsc = new JavaSparkContext(conf);
9 public static void main(String[] args) {
10
11 //假设每个学生只有一门成绩
12 List<Tuple2<Integer,String>> studentList = Arrays.asList(
13 new Tuple2<Integer,String>(1,"tele"),
14 new Tuple2<Integer,String>(2,"yeye"),
15 new Tuple2<Integer,String>(3,"wyc")
16 );
17
18 List<Tuple2<Integer,Integer>> scoreList = Arrays.asList(
19 new Tuple2<Integer,Integer>(1,100),
20 new Tuple2<Integer,Integer>(1,1100),
21 new Tuple2<Integer,Integer>(2,90),
22 new Tuple2<Integer,Integer>(3,70)
23 );
24
25
26 JavaPairRDD<Integer, String> studentRDD = jsc.parallelizePairs(studentList);
27 JavaPairRDD<Integer, Integer> scoreRDD = jsc.parallelizePairs(scoreList);
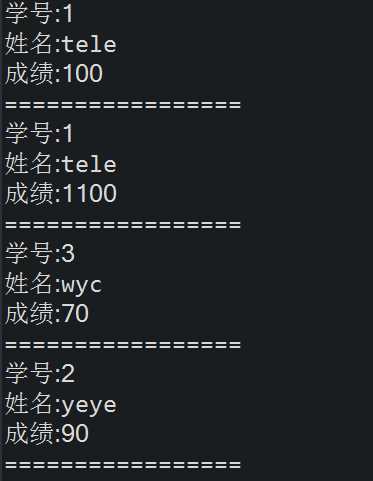
28
29 //注意此处生成的新rdd对的参数类型,第一个泛型参数为key的类型,Tuple2的String与Integer分别对应原rdd的value类型
30 JavaPairRDD<Integer, Tuple2<String, Integer>> result = studentRDD.join(scoreRDD);
31
32 result.foreach(new VoidFunction<Tuple2<Integer,Tuple2<String,Integer>>>() {
33 private static final long serialVersionUID = 1L;
34
35 @Override
36 public void call(Tuple2<Integer, Tuple2<String, Integer>> t) throws Exception {
37 System.out.println("学号:" + t._1);
38 System.out.println("姓名:" + t._2._1);
39 System.out.println("成绩:" + t._2._2);
40 System.out.println("=================");
41 }
42 });
43
44 jsc.close();
45
46 }
47 }
scala
1 object JoinDemo {
2 def main(args: Array[String]): Unit = {
3 val conf = new SparkConf().setMaster("local").setAppName("joindemo");
4 val sc = new SparkContext(conf);
5
6 val studentArr = Array((1,"tele"),(2,"yeye"),(3,"wyc"));
7 val scoreArr = Array((1,100),(2,80),(3,100));
8
9 val studentRDD = sc.parallelize(studentArr,1);
10 val scoreRDD = sc.parallelize(scoreArr,1);
11
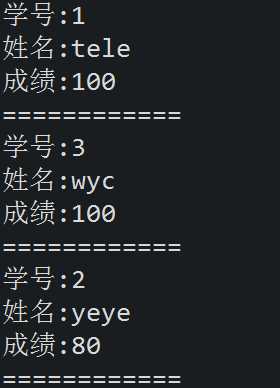
12 val result = studentRDD.join(scoreRDD);
13
14 result.foreach(t=>{
15 println("学号:" + t._1);
16 println("姓名:" + t._2._1);
17 println("成绩:" + t._2._2);
18 println("============")
19 })
20
21 }
22 }
以上是关于spark join算子的主要内容,如果未能解决你的问题,请参考以下文章
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段
Spark RDD常用算子操作 键值对关联操作 subtractByKey, join,fullOuterJoin, rightOuterJoin, leftOuterJoin