Spark基础学习笔记19:RDD的依赖与Stage划分
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark基础学习笔记19:RDD的依赖与Stage划分相关的知识,希望对你有一定的参考价值。
文章目录
零、本讲学习目标
- 理解RDD的宽依赖与窄依赖
- 理解Spark根据DAG将计算划分多个阶段
一、RDD的依赖
- 在Spark中,对RDD的每一次转化操作都会生成一个新的RDD,由于RDD的
懒加载特性,新的RDD会依赖原有RDD,因此RDD之间存在类似流水线的前后依赖关系。这种依赖关系分为两种:窄依赖和宽依赖。
(一)窄依赖
- 窄依赖是指父RDD的一个分区最多被子RDD的一个分区所用。也就是说,父RDD的分区与子RDD的分区的对应关系为一对一或多对一。例如,map()、filter()、union()、join()等操作都会产生窄依赖。
1、map()与filter()算子
- 一对一的依赖
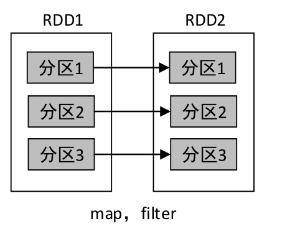
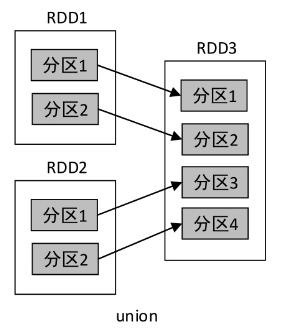
2、union()算子
- 多对一的依赖
3、join()算子
- 多对一的依赖
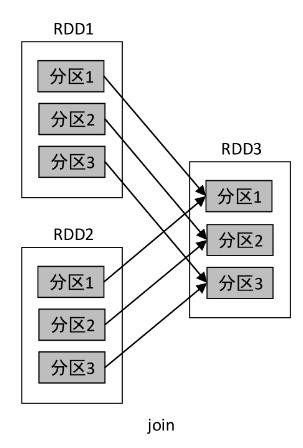
- 对于窄依赖的RDD,根据父RDD的分区进行流水线操作,即可计算出子RDD的分区数据,整个操作可以在集群的一个节点上执行。
(二)宽依赖
- 宽依赖是指父RDD的一个分区被子RDD的多个分区所用。也就是说,父RDD的分区与子RDD的分区的对应关系为多对多。例如,groupByKey()、reduceByKey()、sortByKey()等操作都会产生宽依赖。
1、groupBy()算子
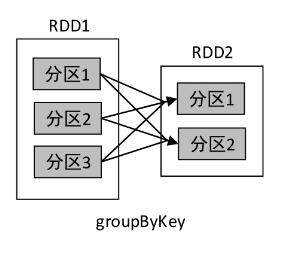
2、join()算子
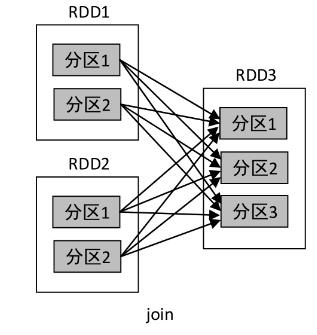
- join()操作的依赖关系分两种情况:RDD的一个分区仅和另一个RDD中已知个数的分区进行组合,这种类型的join()操作是窄依赖,其他情况则是宽依赖。
- 在宽依赖关系中,RDD会根据每条记录的key进行不同分区的数据聚集,数据聚集的过程称作Shuffle,类似MapReduce中的Shuffle过程。举个生活中的例子,4个人一起打牌,打完牌后需要进行洗牌,这4个人相当于4个分区,每个人手里的牌则相当于分区里的数据,洗牌的过程可以理解为Shuffle。因此,Shuffle其实就是不同分区之间的数据聚集或者说数据混洗。Shuffle是一项耗费资源的操作,因为它涉及磁盘I/O、数据序列化和网络I/O。
3、reduceByKey()算子
- 对一个RDD进行reduceByKey()操作,RDD中相同key的所有记录将进行聚合,而key相同的所有记录可能不在同一个分区中,甚至不在同一个节点上,但是该操作必须将这些记录聚集到一起进行计算才能保证结果准确,因此reduceByKey()操作会产生Shuffle,也会产生宽依赖。
(三)两种依赖的比较
- 在数据容错方面,窄依赖要优于宽依赖。当子RDD的某一个分区的数据丢失时,若是窄依赖,则只需重算和该分区对应的父RDD分区即可,而宽依赖需要重算父RDD的所有分区。在groupByKey()操作中,若RDD2的分区1丢失,则需要重新计算RDD1的所有分区(分区1、分区2、分区3)才能对其进行恢复。此外,宽依赖在进行Shuffle之前,需要计算好所有父分区的数据,若某个父分区的数据未计算完毕,则需要等待。
以上是关于Spark基础学习笔记19:RDD的依赖与Stage划分的主要内容,如果未能解决你的问题,请参考以下文章