Spark计算模型
Posted miranda-wu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark计算模型相关的知识,希望对你有一定的参考价值。
通过一个经典的程序来说明
//输入与构造 RDD val file=sc.textFile("***") //转换Transformation val errors=file.filter(line=>line.contains("ERRORS")) //输出 Action error.count()
从RDD的转换和存储角度看这个过程:
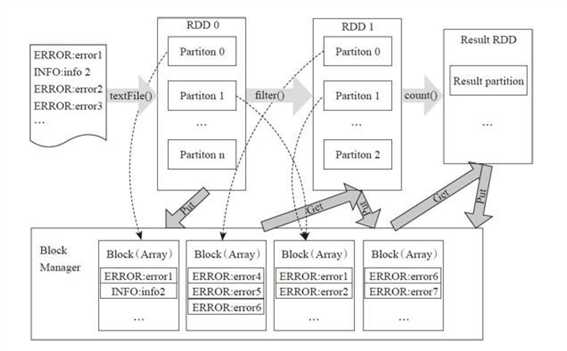
用户程序对RDD通过多个函数进行操作,将RDD进行转换。
Block-Manager管理RDD的物理分区,每个Block就是节点上对应的一个数据块,可以存储在内存或者磁盘。
而RDD中的partition是一个逻辑数据块,对应相应的物理块Block。
本质上一个RDD在代码中相当于是数据的一个元数据结构,存储着数据分区及其逻辑结构映射关系,存储着RDD之前的依赖转换关系。
后面依次介绍此模型中的各个关键组件
以上是关于Spark计算模型的主要内容,如果未能解决你的问题,请参考以下文章
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段