AI - MLCC - 01 - 问题构建 (Framing):机器学习主要术语
Posted anliven
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI - MLCC - 01 - 问题构建 (Framing):机器学习主要术语相关的知识,希望对你有一定的参考价值。
什么是(监督式)机器学习?
简单来说,它的定义:机器学习系统通过学习如何组合输入信息来对从未见过的数据做出有用的预测。
问题构建 (Framing):机器学习主要术语
标签
标签是要预测的事物,即简单线性回归中的 y 变量。
标签可以是小麦未来的价格、图片中显示的动物品种、音频剪辑的含义或任何事物。
特征
特征是输入变量,即简单线性回归中的 x 变量。
简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征,按如下方式指定:
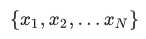
在垃圾邮件检测器示例中,特征可能包括:
- 电子邮件文本中的字词
- 发件人的地址
- 发送电子邮件的时段
- 电子邮件中包含“一种奇怪的把戏”这样的短语。
样本
样本是指数据的特定实例:x。(采用粗体 x 表示它是一个矢量)。样本分为两类:有标签样本和无标签样本。
有标签样本同时包含特征和标签。即:labeled examples: {features, label}: (x, y)
使用有标签样本来训练模型。
在垃圾邮件检测器示例中,有标签样本是用户明确标记为“垃圾邮件”或“非垃圾邮件”的各个电子邮件。
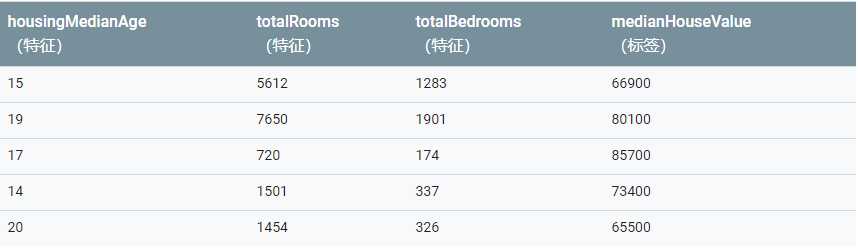
例如,下表显示了从包含加利福尼亚州房价信息的数据集中抽取的 5 个有标签样本:
无标签样本包含特征,但不包含标签。即:unlabeled examples: {features, ?}: (x, ?)
在使用有标签样本训练了模型之后,使用该模型来预测无标签样本的标签。在垃圾邮件检测器示例中,无标签样本是用户尚未添加标签的新电子邮件。
模型
模型定义了特征与标签之间的关系。
例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。
重点介绍一下模型生命周期的两个阶段:
-
训练表示创建或学习模型。也就是说,向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。
-
推断表示将训练后的模型应用于无标签样本。也就是说,使用训练后的模型来做出有用的预测 (
y‘)。例如,在推断期间,可以针对新的无标签样本预测medianHouseValue。
回归与分类
回归模型可预测连续值。例如,回归模型做出的预测可回答如下问题:
-
加利福尼亚州一栋房产的价值是多少?
-
用户点击此广告的概率是多少?
分类模型可预测离散值。例如,分类模型做出的预测可回答如下问题:
-
某个指定电子邮件是垃圾邮件还是非垃圾邮件?
-
这是一张狗、猫还是仓鼠图片?
涉及到的关键字词
分类模型 (classification model)
一种机器学习模型,用于区分两种或多种离散类别。
例如,某个自然语言处理分类模型可以确定输入的句子是法语、西班牙语还是意大利语。
请与回归模型进行比较。
回归模型 (regression model)
一种模型,能够输出连续的值(通常为浮点值)。
请与分类模型进行比较,分类模型会输出离散值,例如“黄花菜”或“虎皮百合”。
样本 (example)
数据集的一行。一个样本包含一个或多个特征,此外还可能包含一个标签。
另请参阅有标签样本和无标签样本。
特征 (feature)
在进行预测时使用的输入变量。
推断 (inference)
在机器学习中,推断通常指以下过程:通过将训练过的模型应用于无标签样本来做出预测。
在统计学中,推断是指在某些观测数据条件下拟合分布参数的过程。(请参阅维基百科中有关统计学推断的文章。)
标签 (label)
在监督式学习中,标签指样本的“答案”或“结果”部分。
有标签数据集中的每个样本都包含一个或多个特征以及一个标签。
例如,在房屋数据集中,特征可能包括卧室数、卫生间数以及房龄,而标签则可能是房价。
在垃圾邮件检测数据集中,特征可能包括主题行、发件人以及电子邮件本身,而标签则可能是“垃圾邮件”或“非垃圾邮件”。
模型 (model)
机器学习系统从训练数据学到的内容的表示形式。
多含义术语,可以理解为“一种TensorFlow图,用于表示预测的计算结构”或者“该TensorFlow图的特定权重和偏差,通过训练决定"。
训练 (training)
确定构成模型的理想参数的过程。
问题构建 (Framing):检查理解情况
问题
假设您想开发一种监督式机器学习模型来预测指定的电子邮件是“垃圾邮件”还是“非垃圾邮件”。以下哪些表述正确?
- 主题标头中的字词适合做标签。
- 未标记为“垃圾邮件”或“非垃圾邮件”的电子邮件是无标签样本。
- 我们将使用无标签样本来训练模型。
- 有些标签可能不可靠。
假设一家在线鞋店希望创建一种监督式机器学习模型,以便为用户提供合乎个人需求的鞋子推荐。也就是说,该模型会向小马推荐某些鞋子,而向小美推荐另外一些鞋子。以下哪些表述正确?
- 鞋码是一项实用特征。
- “用户点击鞋子描述”是一项实用标签。
- 鞋的美观程度是一项实用特征。
- 用户喜欢的鞋子是一种实用标签。
解答
假设您想开发一种监督式机器学习模型来预测指定的电子邮件是“垃圾邮件”还是“非垃圾邮件”。以下哪些表述正确?
- 主题标头中的字词可能是优质特征,但不适合做标签。
- 由于标签由“垃圾邮件”和“非垃圾邮件”这两个值组成,因此任何尚未标记为垃圾邮件或非垃圾邮件的电子邮件都是无标签样本。
- 将使用有标签样本来训练模型。然后,可以对无标签样本运行训练后的模型,以推理无标签的电子邮件是垃圾邮件还是非垃圾邮件。
- 当然。此数据集的标签可能来自将特定电子邮件标记为垃圾邮件的电子邮件用户。由于很少的用户会将每一封可疑的电子邮件都标记为垃圾邮件,因此可能很难知道某封电子邮件是否是垃圾邮件。此外,有些垃圾内容发布者或僵尸网络可能会故意提供错误标签来误导模型。
假设一家在线鞋店希望创建一种监督式机器学习模型,以便为用户提供合乎个人需求的鞋子推荐。也就是说,该模型会向小马推荐某些鞋子,而向小美推荐另外一些鞋子。以下哪些表述正确?
- 鞋码是一种可量化的标志,可能对用户是否喜欢推荐的鞋子有很大影响。例如,如果小马穿 43 码的鞋,则该模型不应该推荐 39 码的鞋。
- 用户可能只是想要详细了解他们喜欢的鞋子。因此,用户点击次数是可观察且可量化的指标,可用来训练合适的标签。
- 合适的特征应该是具体且可量化的。美观程度是一种过于模糊的概念,不能作为实用特征。美观程度可能是某些具体特征(例如样式和颜色)的综合表现。样式和颜色都比美观程度更适合用作特征。
- 喜好不是可观察且可量化的指标。我们能做到最好的就是针对用户的喜好来搜索可观察的代理指标。
以上是关于AI - MLCC - 01 - 问题构建 (Framing):机器学习主要术语的主要内容,如果未能解决你的问题,请参考以下文章
AI - MLCC08 - 表示法 (Representation)
AI - MLCC - 02 - 深入了解机器学习 (Descending into ML)