AI - MLCC08 - 表示法 (Representation)
Posted anliven
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI - MLCC08 - 表示法 (Representation)相关的知识,希望对你有一定的参考价值。
原文链接:https://developers.google.com/machine-learning/crash-course/representation/
1- 特征工程
机器学习的关注点是特征表示,也就是说,开发者通过添加和改善特征来调整模型。
将原始数据映射到特征
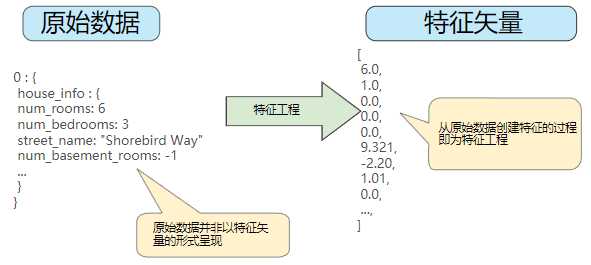
左侧表示来自输入数据源的原始数据,右侧表示特征矢量,也就是组成数据集中样本的浮点值集。
特征工程指的是将原始数据转换为特征矢量,也就是说,是将原始数据映射到机器学习特征。
进行特征工程预计需要大量时间。
许多机器学习模型都必须将特征表示为实数向量,因为特征值必须与模型权重相乘。
映射数值
整数和浮点数据不需要特殊编码,因为它们可以与数字权重相乘。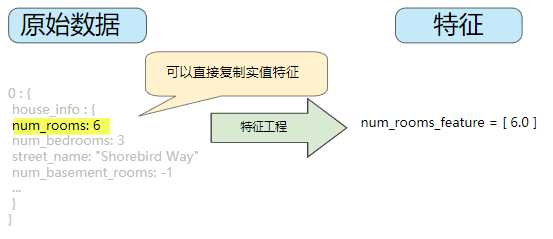
映射分类值
分类特征具有一组离散的可能值。
由于模型不能将字符串与学习到的权重相乘,因此使用特征工程将字符串转换为数字值。
实现方法:
- 定义一个从特征值(可能值的词汇表)到整数的映射。
- 将所有其他可能值词汇分组为一个全部包罗的“其他”类别,称为 OOV(词汇表外)分桶。
但如果将这些索引数字直接纳入到模型中,将会造成一些可能存在问题的限制:
- 模型没有灵活地学习不同的权重,而是学习了适用于所有可能值的单一权重
- 特征值可能有多个值
如何去除以上限制?
可以为模型中的每个分类特征创建一个二元向量来表示这些值
- 对于适用于样本的值,将相应向量元素设为 1。
- 将所有其他元素设为 0。
该向量的长度等于词汇表中的元素数。
当只有一个值为 1 时,这种表示法称为独热编码;当有多个值为 1 时,这种表示法称为多热编码。
该方法能够有效地为每个特征值创建布尔变量。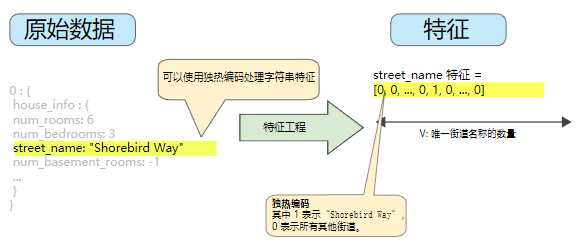
稀疏表示法 (sparse representation)
一种张量表示法,仅存储非零元素。
可以避免占用大量的存储空间并耗费很长的计算时间。
在稀疏表示法中,仍然为每个特征值学习独立的模型权重。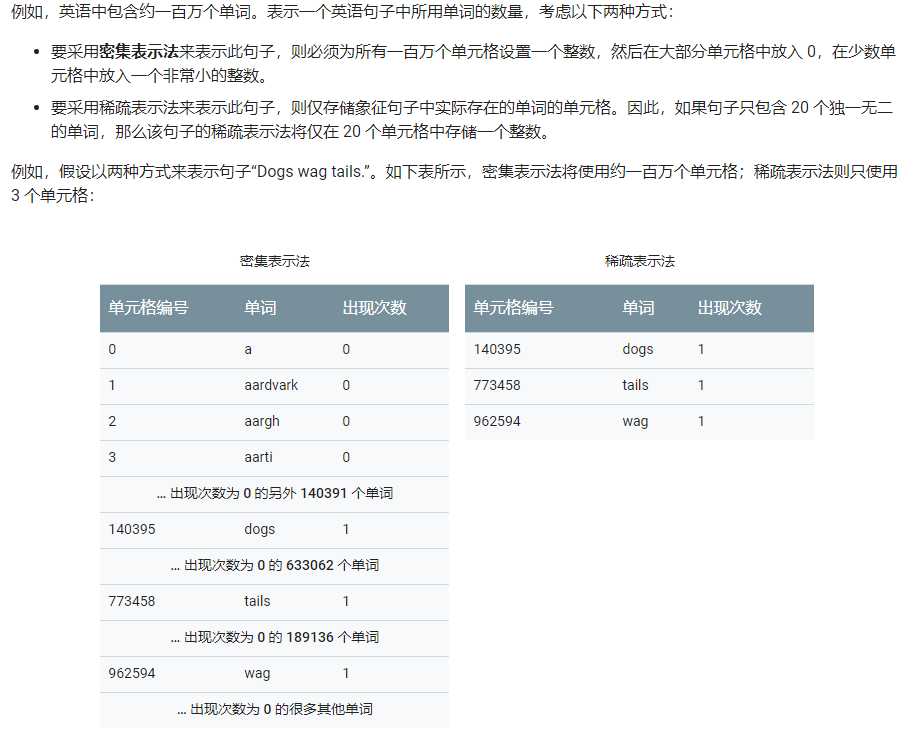
2- 良好特征的特点
什么样的值才算特征矢量中良好的特征?
避免很少使用的离散特征值
良好的特征值应该在数据集中出现大约 5 次以上,模型就可以学习该特征值与标签是如何关联的。
也就是说,大量离散值相同的样本可让模型有机会了解不同设置中的特征,从而判断何时可以对标签很好地做出预测。
相反,如果某个特征的值仅出现一次或者很少出现,则模型就无法根据该特征进行预测。
最好具有清晰明确的含义
每个特征对于项目中的任何人来说都应该具有清晰明确的含义。
在某些情况下,混乱的数据(而不是糟糕的工程选择)会导致含义不清晰的值。
不要将“神奇”的值与实际数据混为一谈
良好的浮点特征不包含超出范围的异常断点或“神奇”的值。
如果某个特征的值包含“神奇值”,为解决这个问题,需将该特征转换为两个特征:
- 一个特征只存储特征的值,但不含神奇值
- 一个特征存储布尔值,表示是否提供了该特征
考虑上游不稳定性
特征的定义不应随时间发生变化。
例如,城市名称一般不会改变,但城市的电话号码前缀这种表示在未来运行其他模型时可能轻易发生变化。
以上是关于AI - MLCC08 - 表示法 (Representation)的主要内容,如果未能解决你的问题,请参考以下文章