初识spark的MLP模型
Posted smilingeye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识spark的MLP模型相关的知识,希望对你有一定的参考价值。
初识Spark的MLP模型
1. MLP介绍
Multi-layer Perceptron(MLP),即多层感知器,是一个前馈式的、具有监督的人工神经网络结构。通过多层感知器可包含多个隐藏层,实现对非线性数据的分类建模。MLP将数据分为训练集、测试集、检验集。其中,训练集用来拟合网络的参数,测试集防止训练过度,检验集用来评估网络的效果,并应用于总样本集。当因变量是分类型的数值,MLP神经网络则根据所输入的数据,将记录划分为最适合类型。常被MLP用来进行学习的反向传播算法,在模式识别的领域中算是标准监督学习算法,并在计算神经学及并行分布式处理领域中,持续成为被研究的课题。MLP已被证明是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题。
2. 使用Java进行开发
2.1开发环境准备
- 基本Java开发环境
Eclipse,Maven,Jdk1.7
- spark开发需要环境
Windows操作系统保存训练模型必须要依赖于hadoop-common-2.2.0-bin-master,如果不保存模型不需要配置此环境,linux操作系统不需要配置此环境。
配置此环境有以下两种方法:
- 直接在代码最开始写
System.setProperty("hadoop.home.dir", "D:\\Programe\\hadoop-common-2.2.0-bin-master");
- 配置入环境变量
直接在Windows的系统变量里面配置HADOOP_HOME,然后在PATH里面配置HADOOP_HOME/bin
2.2项目搭建
- 创建简单的maven项目
- 在pom下增加下列jar
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.3</version>
<scope>runtime</scope>
</dependency>
注意:本例使用jdk1.7,spark2.2.x要求jdk1.8。
2.3官网实例
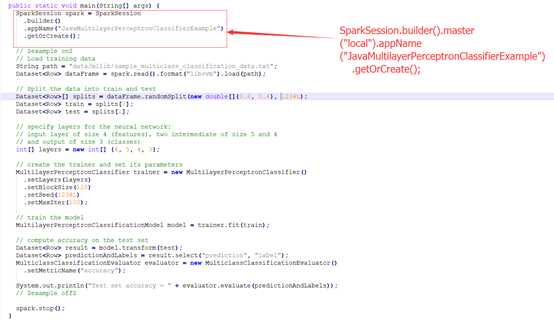
注意:创建SparkSession时添加.master(“local”)
2.4保存训练模型
上例是直接使用数据训练模型之后进行预测,大多数情况是模型只需训练一次,之后就可以直接使用,于是Spark提供了保存模型的方法。
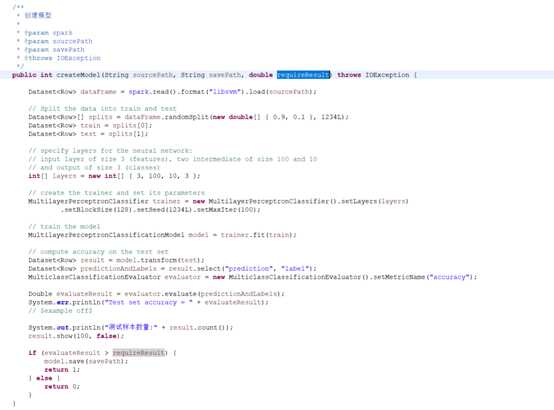
2.5获取训练模型

2.6其他相关知识
- Java类型数据转换为Spark数据类型
略
- 如何从word生成Spark可加载的libsvm的文档
略
3. 参考文档
hadoop-common-2.2.0-bin-master下载地址
https://github.com/srccodes/hadoop-common-2.2.0-bin
Spark的MPL例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
代码例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples
以上是关于初识spark的MLP模型的主要内容,如果未能解决你的问题,请参考以下文章