spark调优之数据倾斜
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark调优之数据倾斜相关的知识,希望对你有一定的参考价值。
(1)数据倾斜的介绍
1)数据分区的策略:
- 随机分区:每一个数据分配的任意一个分区的概率是均等的
- Hash分区:使用数据的Hash分区值,%分区数。(导致数据倾斜的原因)
- 范围分区:将数据范围划分,数据分配到不同的范围中(分布式的全局排序)
2)数据倾斜的原因:
Shuffle数据之后导致数据分布不均匀,但是所有节点的机器的性能都是一样的,程序也是一样的,就是数据量不一致,所以决定了task的执行时长就被数据量决定了。
3)定位数据倾斜的代码:
数据倾斜发生在shuffle过程,有shuffle过程的算子有:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。或者查看哪一个task执行缓慢、内存溢出...
4)查看数据倾斜的key的分布情况:
//使用spark中的抽样算子sample,查看相应的key的分布
val sampledPairs = pairs.sample(false, 0.1) //抽样
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))
(2)数据倾斜的解决方案
1)过滤掉少数数据倾斜的key:
如果发现导致数据倾斜的key是极少数,并且对计算本身影响不大,那么这种方案比较适用。
实现原理:通过spark的sample算子,定位到数据倾斜的key,然后使用filter算子将其过滤即可。
2)提高shuffle的并行度:
这是一种尝试性策略:就是提高增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。
3)两阶段的聚合(局部聚合和全局聚合):
适用场景:对RDD执行reduceByKey等这类有聚合操作的shuffle算子或者spark SQL使用使用group by语句进行分组聚合,比较适用。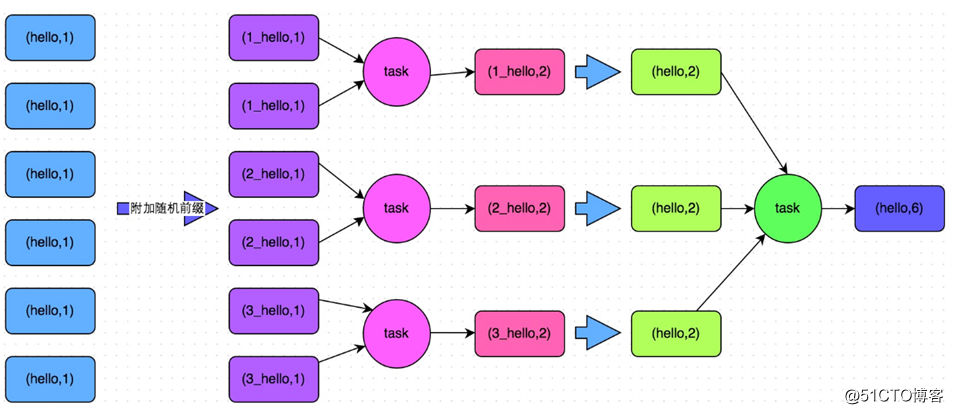
原理:将原本相同的key通过附加随机前缀的方式,变成多个不同key,就可以让原本被一个task处理的数据分散到多个task上做局部聚合,进行解决单个task处理数据量过多的问题。接着去除随机前缀,再次进行全局的聚合,就可以得到最终的结果。
代码实现:
object _01SparkDataSkewTwoStageOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
val sc = SparkUtil.sparkContext("local[2]", "_01SparkDataSkewTwoStageOps")
val list = List(
"hello you hello hello me",
"hello you hello hello shit",
"oh hello she study"
)
val listRDD = sc.parallelize(list)
val pairsRDD = listRDD.flatMap(line => line.split("\s+")).map((_, 1))
//step 1 找到发生数据倾斜key
val sampleRDD = pairsRDD.sample(false, 0.6)
val cbk= sampleRDD.countByKey()
// cbkRDD.foreach(println)
val sortedInfo = cbk.toBuffer.sortWith((t1, t2) => t1._2 > t2._2)
val dataSkewKey = sortedInfo.head._1
// sortedInfo.foreach(println)
println("发生了数据倾斜的Key:" + dataSkewKey)
//step 2 给对应的key打上N以内的随机前缀
val prefixPairsRDD = pairsRDD.map{case (word, count) => {
if(word.equals(dataSkewKey)) {
val random = new Random()
val prefix = random.nextInt(2)//0 1
(s"${prefix}_${word}", count)
} else {
(word, count)
}
}}
prefixPairsRDD.foreach(println)
//step 3 局部聚合
val partAggrInfo = prefixPairsRDD.reduceByKey(_+_)
println("===============>局部聚合之后的结果:")
partAggrInfo.foreach(println)
//step 4 全局聚合
//step 4.1 去掉前缀
val unPrefixPairRDD = partAggrInfo.map{case (word, count) => {
if(word.contains("_")) {
(word.substring(word.indexOf("_") + 1), count)
} else {
(word, count)
}
}}
println("================>去掉随机前缀之后的结果:")
unPrefixPairRDD.foreach(println)
// step 4.2 全局聚合
val fullAggrInfo = unPrefixPairRDD.reduceByKey(_+_)
println("===============>全局聚合之后的结果:")
fullAggrInfo.foreach(println)
sc.stop()
}
}4)将reduce join 转换为map join(大小表):
适用场景:在对RDD使用join操作,或者是在sparksql 中使用join语句的时候,而且join操作中的一个RDD或者表的数据量比较小,此方法适用
实现原理:有reduce join的过程一定有shuffle,有shuffle就可能出现数据的倾斜,所以将reduce join使用map join 代替。如果一个RDD是比较小的,那么可以使用广播变量的方式,将小RDD发送到各个worker的executor中,实现本地的连接
代码实现:
object _02SparkRDDBroadcastOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName(s"${_02SparkRDDBroadcastOps.getClass.getSimpleName}")
val sc = new SparkContext(conf)
val stu = List(
"1 郑祥楷 1",
"2 王佳豪 1",
"3 刘鹰 2",
"4 宋志华 3",
"5 刘帆 4",
"6 OLDLi 5"
)
val cls = List(
"1 1807bd-bj",
"2 1807bd-sz",
"3 1807bd-wh",
"4 1807bd-xa",
"7 1805bd-bj"
)
/*
使用广播变量来完成上述操作
一般用户表都比较大,而班级表相对很小,符合我们在共享变量中提出的第一个假设
所以我们可以尝试使用广播变量来进行解决
*/
val stuRDD = sc.parallelize(stu)
//cls-->map---->
val map = cls.map{case line => {
(line.substring(0, line.indexOf(" ")), line.substring(line.indexOf(" ")).trim)
}}.toMap
//map--->broadcast
val clsMapBC:Broadcast[Map[String, String]] = sc.broadcast(map)
stuRDD.map{case line => {
val map = clsMapBC.value
val fields = line.split("\s+")
val cid = fields(2)
// map.get(cid)
val className = map.getOrElse(cid, "UnKnown")
s"${fields(0)} ${fields(1)} ${className}"//在mr中学习到的map join
}}.foreach(println)
sc.stop()
}5)采样倾斜的key并拆分join操作(大大表):
适用场景:在hive两张表进行join的时候,如果两张表的数据都很大,并且,一张表的数据很均匀,但是另一张表的数据有少量的key数据量过大,此时使用这个解决方案
实现原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。
代码实现:
一张表中:
Id num
1 100W
2 10
3 10
4 10
5 10可以使用union的方式来启动多个job并行执行:
//通过分离数据量大key来解决数据倾斜
select count(*) from t_test where id !=1 group by id
union
select count(*) from t_test where id ==1 group by id6)使用随机前缀和扩容RDD进行join(大量key的数据倾斜):
适用场景:如果进行join操作时,RDD中有大量的key导致数据倾斜,那么进行拆分可以也没有意义,此时使用这种方法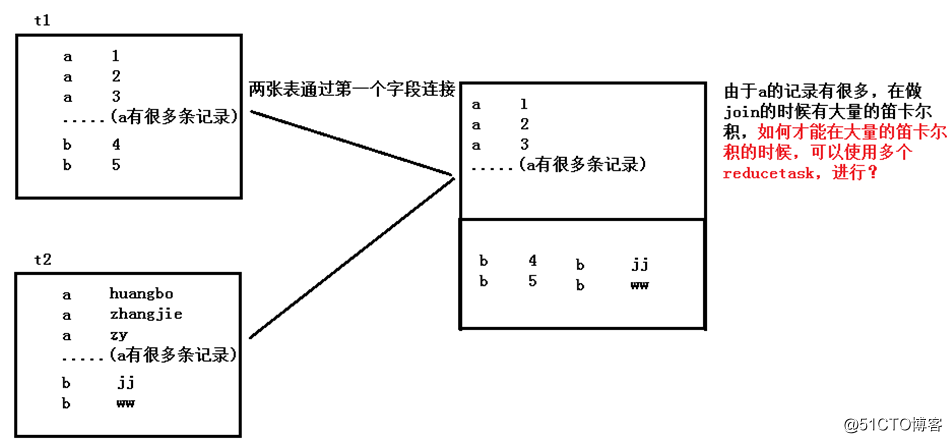
实现原理:这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
代码实现: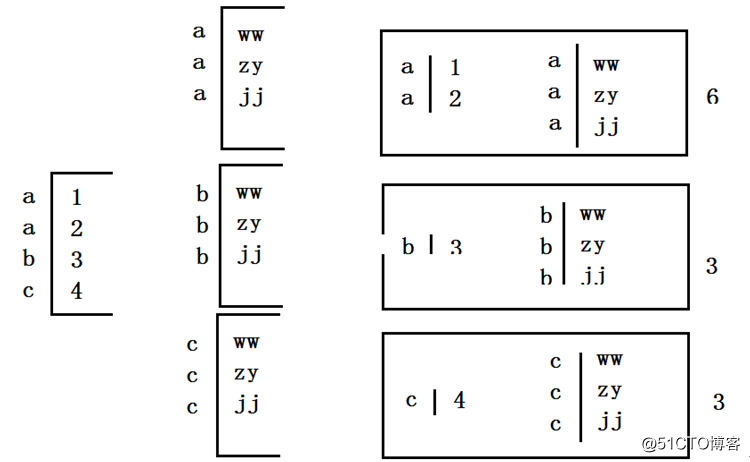
左表的连接条件的值,可以在某个范围内进行随机,并且这个随机值有多少个,那么右表的数据就要复制多少份。
object _03SparkJoinDataSkewOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
val sc = SparkUtil.sparkContext("local[2]", "_03SparkJoinDataSkewOps")
val list1 = List(
"hello 1",
"hello 2",
"hello 3",
"hello 4",
"you 1",
"me 2"
)
val list2 = List(
"hello zhangsan dfsadfasdfsa",
"hello lisi adfasdfasd",
"you wangwu adfasdfs",
"me zhouqi adfadfa"
)
//<key, value>
val listRDD1 = sc.parallelize(list1).map(line => {
val fields = line.split("\s+")
(fields(0), fields(1))
})
//<key, value>
val listRDD2 = sc.parallelize(list2).map(line => {
val fields = line.split("\s+")
(fields(0), fields(1))
})
val joinRDD: RDD[(String, (String, String))] = dataSkewRDDJoin(sc, listRDD1, listRDD2)
println("最后进行join的结果:")
joinRDD.foreach(println)
sc.stop()
}
private def dataSkewRDDJoin(sc: SparkContext, listRDD1: RDD[(String, String)], listRDD2: RDD[(String, String)]) = {
//假设listRDD1中的部分key有数据倾斜,所以我在进行join操作的时候,需要进行拆分计算
//step 1 找到发生数据倾斜的key
val dataSkewKeys = listRDD1.sample(false, 0.6).countByKey().toList.sortWith((t1, t2) => t1._2 > t2._2).take(1).map(t => t._1)
println("通过sample算子得到的可能发生数据倾斜的key:" + dataSkewKeys)
//step 2 对listRDD1和listRDD2中的数据按照dataSkewKeys各拆分成两个部分
//step 2.1 讲dataSkewKeys进行广播
val dskBC = sc.broadcast(dataSkewKeys)
// step 2.2 进行拆分
val dataSkewRDD1 = listRDD1.filter { case (word, value) => {
//有数据倾斜的rdd--->dataskewRDD1
val dsks = dskBC.value
dsks.contains(word)
}
}
val commonRDD1 = listRDD1.filter { case (word, value) => {
//没有数据倾斜的rdd--->commonRDD1
val dsks = dskBC.value
!dsks.contains(word)
}
}
val dataSkewRDD2 = listRDD2.filter { case (word, value) => {
//有数据倾斜的rdd--->dataskewRDD1
val dsks = dskBC.value
dsks.contains(word)
}
}
val commonRDD2 = listRDD2.filter { case (word, value) => {
//没有数据倾斜的rdd--->commonRDD1
val dsks = dskBC.value
!dsks.contains(word)
}
}
}
//step 3 对dataskewRDD进行添加N以内随机前缀
// step 3.1 添加随机前缀
val prefixDSRDD1:RDD[(String, String)] = dataSkewRDD1.map { case (word, value) => {
val random = new Random()
val prefix = random.nextInt(2)
(s"${prefix}_${word}", value)
}
}
// step 3.2 另一个rdd进行扩容
val prefixDSRDD2:RDD[(String, String)] = dataSkewRDD2.flatMap { case (word, value) => {
val ab = ArrayBuffer[(String, String)]()
for (i <- 0 until 2) {
ab.append((s"${i}_${word}", value))
}
ab
}
}
println("---->有数据倾斜RDD1添加前缀成prefixDSRDD1的结果:" + prefixDSRDD1.collect().mkString(","))
println("---->有数据倾斜RDD2扩容之后成prefixDSRDD2的结果:" + prefixDSRDD2.collect().mkString(","))
// step 4 分步进行join操作
// step 4.1 有数据倾斜的prefixDSRDD1和prefixDSRDD2进行join
val prefixJoinDSRDD = prefixDSRDD1.join(prefixDSRDD2)
//ste 4.2 无数据倾斜的commonRDD1和commonRDD2进行join
val commonJoinRDD = commonRDD1.join(commonRDD2)
// step 4.3 将随机前缀去除
val dsJionRDD = prefixJoinDSRDD.map { case (word, (value1, value2)) => {
(word.substring(2), (value1, value2))
}
}
//step 5 将拆分进行join之后的结果进行union连接,得到最后的结果 sql union all
val joinRDD = dsJionRDD.union(commonJoinRDD)
joinRDD
}
}本博文参考至美团的spark调优:https://tech.meituan.com/
以上是关于spark调优之数据倾斜的主要内容,如果未能解决你的问题,请参考以下文章