关于在本地idea当中提交spark代码到远程的错误总结(第一篇)
Posted gxgd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于在本地idea当中提交spark代码到远程的错误总结(第一篇)相关的知识,希望对你有一定的参考价值。
最近在做将spark的代码提交到远程当中遇到很多坑,各种各样的错误:
我是在window当中使用idea开发将本地的代码提交到远程的spark集群上,没有用到local的模式去做(在实际的生产当中不会用到local的方式去做,所以没考虑)
我是直接run的方式在idea当中提交代码的,这里采用的standlone的模式和 on yarn(yarn-client) 的模式,先说一下原理:
我们在本地运行实际还是相当于我们将代码远程的提交到集群上运行时一样的,还是相当于spark-submit的方式进行运行的,在这里也有参数配置和打jar包的形式(这是个人的一些见解)
首先我们应该将core-site.xml,hdfs-site.xml,hive-site.xml,yarn-site.xml,这些配置文件全部放在工程目录的resources下面,方便程序加载到这些配置文件。
下面是遇到的问题;
(1) 代码提交完成之后在yarn上面也启动了application,但是那就是一直会失败,然后我去看启动的container发现container尝试三次都失败了,这是什么情况,然后在运行期间查看了一下日志,包log包找不到不可能啊报错如下
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/Logger at java.lang.Class.getDeclaredMethods0(Native Method) at java.lang.Class.privateGetDeclaredMethods(Class.java:2570) at java.lang.Class.getMethod0(Class.java:2813) at java.lang.Class.getMethod(Class.java:1663) at sun.launcher.LauncherHelper.getMainMethod(LauncherHelper.java:494) at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:486) Caused by: java.lang.ClassNotFoundException: org.slf4j.Logger at java.net.URLClassLoader$1.run(URLClassLoader.java:366) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at java.lang.ClassLoader.loadClass(ClassLoader.java:425) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308) at java.lang.ClassLoader.loadClass(ClassLoader.java:358) ... 6 more
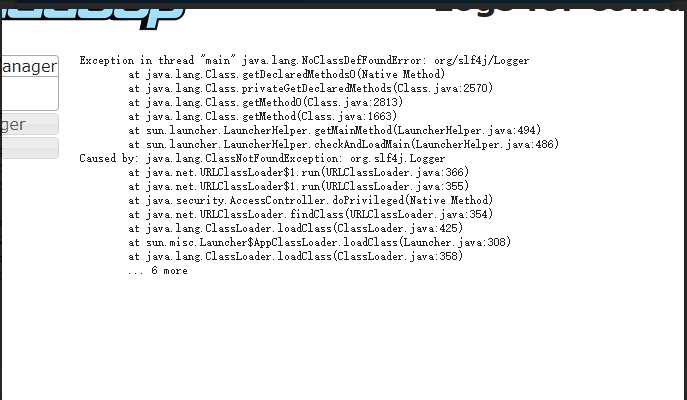
看到上面的这个错误肯定是spark当中没有日志这个类存在,让我就把这些包全部下载下来放在spark的lib包下面,发现好像并没有什么用。
(2)报错信息如下:
java.io.IOException: Cannot run program "/etc/hadoop/conf.cloudera.yarn/topology.py" (in directory "E:datahousespark_on_yarn_demo-mastersparkonstandlone"): CreateProcess error=2, 系统找不到指定的文件。 at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048) at org.apache.hadoop.util.Shell.runCommand(Shell.java:548) at org.apache.hadoop.util.Shell.run(Shell.java:507) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:789) at org.apache.hadoop.net.ScriptBasedMapping$RawScriptBasedMapping.runResolveCommand(ScriptBasedMapping.java:251) at org.apache.hadoop.net.ScriptBasedMapping$RawScriptBasedMapping.resolve(ScriptBasedMapping.java:188) at org.apache.hadoop.net.CachedDNSToSwitchMapping.resolve(CachedDNSToSwitchMapping.java:119) at org.apache.hadoop.yarn.util.RackResolver.coreResolve(RackResolver.java:101) at org.apache.hadoop.yarn.util.RackResolver.resolve(RackResolver.java:81) at org.apache.spark.scheduler.cluster.YarnScheduler.getRackForHost(YarnScheduler.scala:38) at org.apache.spark.scheduler.TaskSchedulerImpl$$anonfun$resourceOffers$1.apply(TaskSchedulerImpl.scala:303) at org.apache.spark.scheduler.TaskSchedulerImpl$$anonfun$resourceOffers$1.apply(TaskSchedulerImpl.scala:292) at scala.collection.Iterator$class.foreach(Iterator.scala:727) at scala.collection.AbstractIterator.foreach(Iterator.scala:1157) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
看到这个错误肯定联想到时我们本地没有这目录,然后去创建这个目录然后再执行,返现好像并不能。
解决办法:
将resources目录下面的core-site.xml里面下面这个配置注释掉:
<property>
<name>net.topology.script.file.name</name>
<value>/etc/hadoop/conf.cloudera.yarn/topology.py</value>
</property>
(3)报错信息如下:
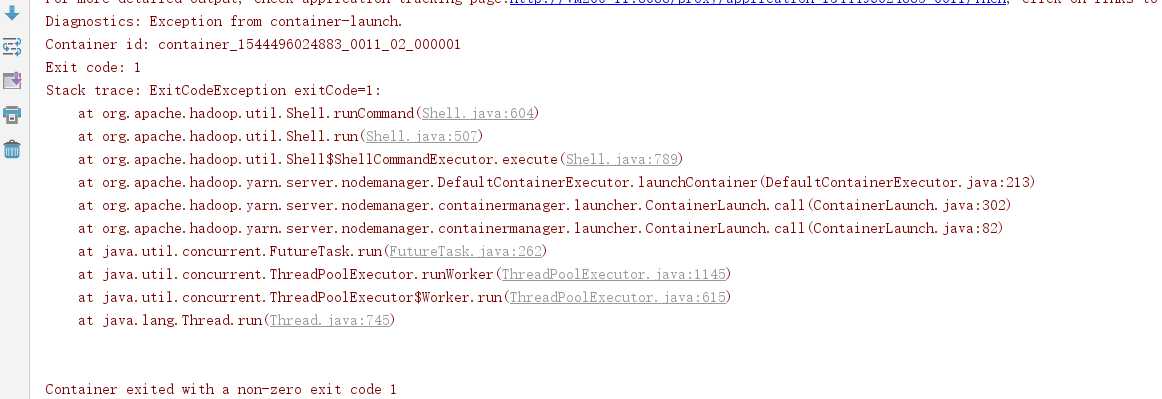
这个好像是一个通用的错误,一旦我们的配置文件出现问题就会爆出这样的错误。这个解决办法在后面一并解决:
(4)报错如下:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/mapreduce/MRJobConfig at org.apache.spark.deploy.yarn.Client$$anonfun$21.apply(Client.scala:1202) at org.apache.spark.deploy.yarn.Client$$anonfun$21.apply(Client.scala:1201) at scala.util.Try$.apply(Try.scala:161) at org.apache.spark.deploy.yarn.Client$.getDefaultMRApplicationClasspath(Client.scala:1201) at org.apache.spark.deploy.yarn.Client$.getMRAppClasspath(Client.scala:1178) at org.apache.spark.deploy.yarn.Client$.populateHadoopClasspath(Client.scala:1163) at org.apache.spark.deploy.yarn.Client$.populateClasspath(Client.scala:1265) at org.apache.spark.deploy.yarn.ExecutorRunnable.prepareEnvironment(ExecutorRunnable.scala:279) at org.apache.spark.deploy.yarn.ExecutorRunnable.launchContextDebugInfo(ExecutorRunnable.scala:70) at org.apache.spark.deploy.yarn.ApplicationMaster$$anonfun$registerAM$1.apply(ApplicationMaster.scala:297) at org.apache.spark.deploy.yarn.ApplicationMaster$$anonfun$registerAM$1.apply(ApplicationMaster.scala:291) at org.apache.spark.Logging$class.logInfo(Logging.scala:58) at org.apache.spark.deploy.yarn.ApplicationMaster.logInfo(ApplicationMaster.scala:51) at org.apache.spark.deploy.yarn.ApplicationMaster.registerAM(ApplicationMaster.scala:291) at org.apache.spark.deploy.yarn.ApplicationMaster.runExecutorLauncher(ApplicationMaster.scala:376) at org.apache.spark.deploy.yarn.ApplicationMaster.run(ApplicationMaster.scala:199) at org.apache.spark.deploy.yarn.ApplicationMaster$$anonfun$main$1.apply$mcV$sp(ApplicationMaster.scala:680) at org.apache.spark.deploy.SparkHadoopUtil$$anon$1.run(SparkHadoopUtil.scala:69) at org.apache.spark.deploy.SparkHadoopUtil$$anon$1.run(SparkHadoopUtil.scala:68) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917) at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:68) at org.apache.spark.deploy.yarn.ApplicationMaster$.main(ApplicationMaster.scala:678) at org.apache.spark.deploy.yarn.ExecutorLauncher$.main(ApplicationMaster.scala:697) at org.apache.spark.deploy.yarn.ExecutorLauncher.main(ApplicationMaster.scala) Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.mapreduce.MRJobConfig at java.net.URLClassLoader$1.run(URLClassLoader.java:366) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at java.lang.ClassLoader.loadClass(ClassLoader.java:425) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308) at java.lang.ClassLoader.loadClass(ClassLoader.java:358) ... 26 more
这个错误就很明显了,在本地启动我们的spark程序的时候与mr有关的包没有加载进来。这个也就是yarn的配置问题yarn-site.xml里面yarn.application.classpath的配置问题。
(1),(3),(4)的问题都是归于这个问题的,我们没有对yarn-site.mxl当中的yarn.application.classpath配置不当造成的。
解决办法如下:
首先来看一下我们装的cm集群的这个配置:

通过这张图片我们没有看到MR的相关的包加载进来,也就是报错(4)他加载不到我们的mr的相关的包。所以就报错了所以解决错误的办法就是配置yarn.application.classpath。配置如下:
$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*, /opt/cloudera/parcels/CDH-5.14.0-1.cdh5.14.0.p0.24/lib/hadoop-mapreduce/*, /opt/cloudera/parcels/CDH-5.14.0-1.cdh5.14.0.p0.24/lib/hadoop-mapreduce/lib/*
MR的包我使用的全路径加载,也可以使用环境变量的形式进行加载。
然后我们在回到错误(1)上面分析一下在整个程序执行的时候的过程,程序在提交到yarn上但是container一直失败:
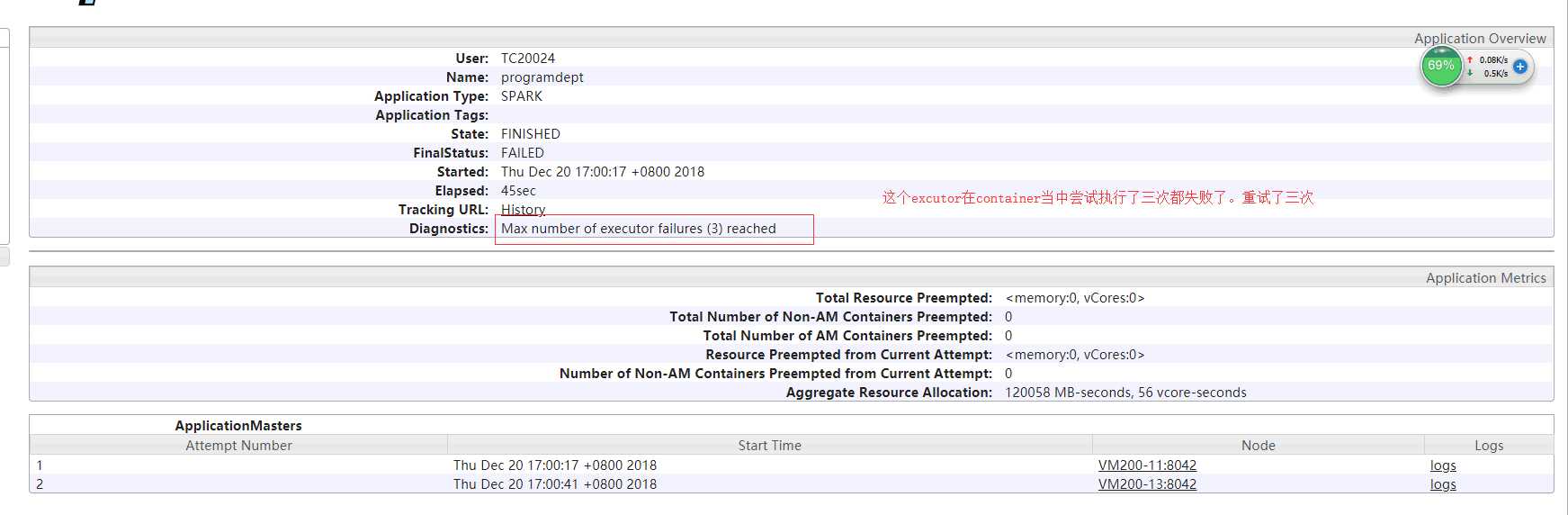
从这里我们看出container在重试了三次之后,依然以报错的形式结束了,然后在集群上执行spark自带的例子然后去看打印的日志日志如下:
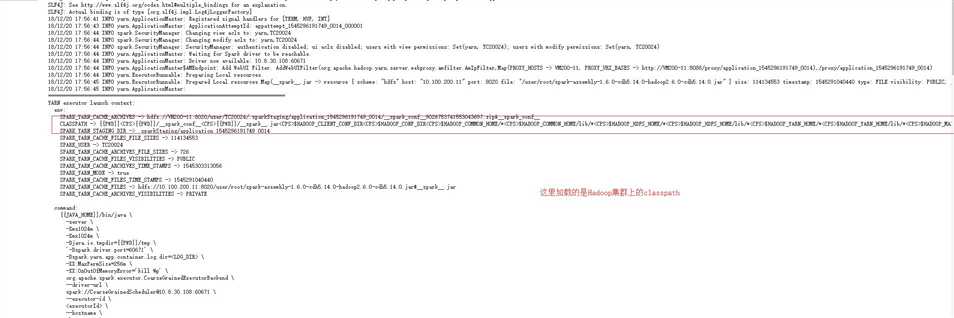
这里清晰的可以看到我们加载的是集群上面的Hadoop相关的jar包。再回过头来看我们提交的代码在集群上的运行加载的classpath:
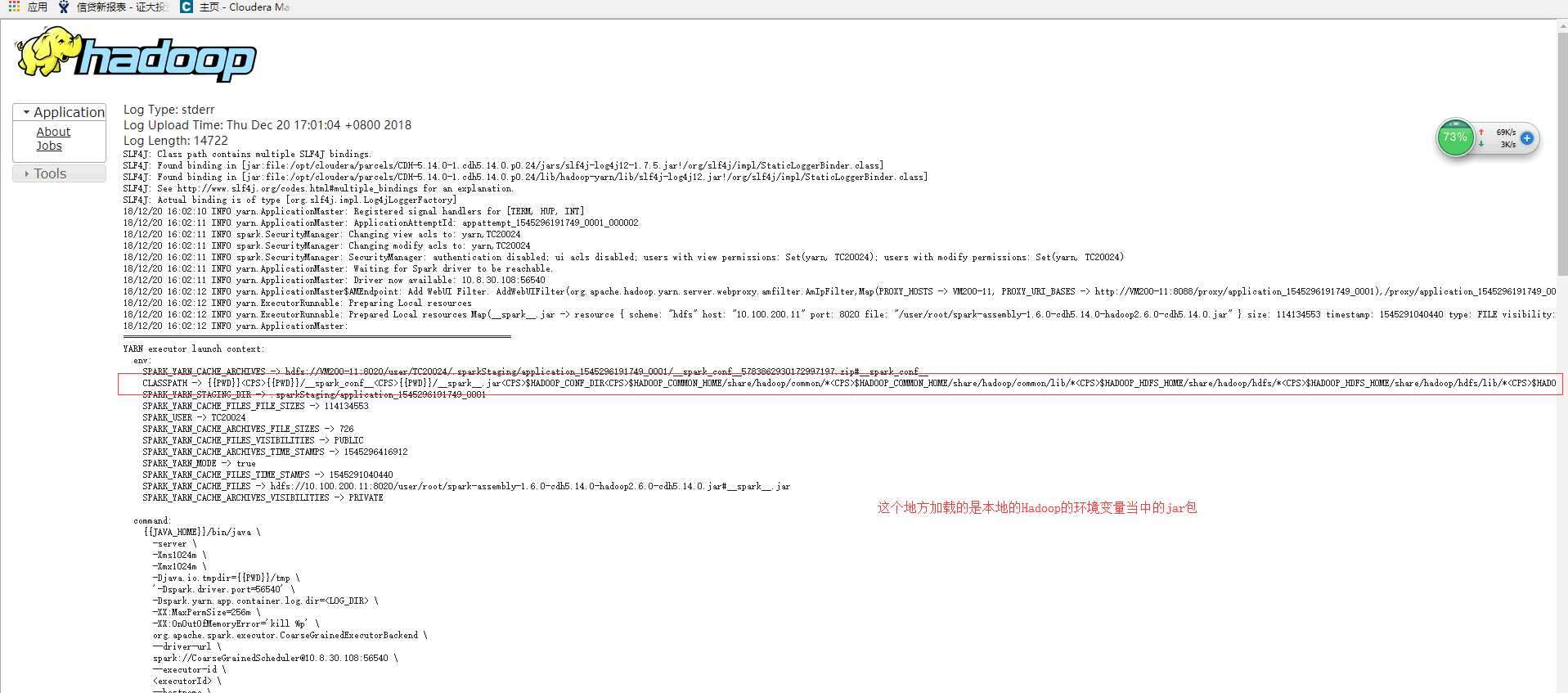
这是什么情况,这里居然加载的是我本地环境变量的Hadoop的所有的jar包。然后就导致了各种问题的出现。不按照常理出牌。
所以我们在配置yarn-site.xml的yarn.application.classpath的时候一定要按照我们集群那种方式去配置。对于这里使用的是相对路径还是绝对路径,在不影响使用的情况下
尽量使用它默认生成的变量。实在不行的情况下换成绝对路径。
以上是关于关于在本地idea当中提交spark代码到远程的错误总结(第一篇)的主要内容,如果未能解决你的问题,请参考以下文章
git:IDEA与git(IDEA提交代码到本地仓库&远程仓库远程仓库克隆代码分支)
如何利用idea提交本地代码到git远程仓库,史上最详细教程,建议收藏!
GitIntelliJ IDEA 提交代码到 GitCode 远程仓库 ( GitCode 创建远程仓库 | 将本地工程推送到 GitCode 远程仓库 | 验证权限 | 生成个人访问令牌 )(代码片