基于cifar10实现卷积神经网络图像识别
Posted yszd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于cifar10实现卷积神经网络图像识别相关的知识,希望对你有一定的参考价值。
1 import tensorflow as tf 2 import numpy as np 3 import math 4 import time 5 import cifar10 6 import cifar10_input 7 """ 8 Created on Tue Nov 27 17:31:35 2018 9 @author: zhen 10 """ 11 max_steps = 1000 12 # 下载cifar10数据集的默认路径 13 batch_size = 128 14 data_dir = "C:/Users/zhen/.spyder-py3/cifar/cifar-10/cifar-10-batches/cifar-10-batches-bin" 15 16 def variable_with_weight_losses(shape, stddev, wl): 17 # 定义初始化weights的函数 18 var = tf.Variable(tf.truncated_normal(shape, stddev=stddev)) 19 if wl is not None: 20 weight_loss = tf.multiply(tf.nn.l2_loss(var), wl, name=‘weight_loss‘) 21 tf.add_to_collection("losses", weight_loss) 22 return var 23 24 # 下载数据 25 cifar10.maybe_download_and_extract() 26 # 加载训练数据 27 images_train, labels_train = cifar10_input.distorted_inputs(data_dir=data_dir, batch_size=batch_size) 28 # 生成测试数据 29 images_test, labels_test = cifar10_input.inputs(eval_data=True, data_dir=data_dir, batch_size=batch_size) 30 31 image_holder = tf.placeholder(tf.float32, [batch_size, 24, 24, 3]) 32 label_holder = tf.placeholder(tf.int32, [batch_size]) 33 34 # 设置第一层卷积层 35 weight_1 = variable_with_weight_losses(shape=[5, 5, 3, 64], stddev=5e-2, wl=0.0) 36 kernel_1 = tf.nn.conv2d(image_holder, filter=weight_1, strides=[1, 1, 1, 1], padding=‘SAME‘) 37 bias_1 = tf.Variable(tf.constant(0.0, shape=[64])) 38 # 卷积 39 conv_1 = tf.nn.relu(tf.nn.bias_add(kernel_1, bias_1)) 40 # 池化 41 pool_1 = tf.nn.max_pool(conv_1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding=‘SAME‘) 42 norm_1 = tf.nn.lrn(pool_1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75) 43 44 # 设置第二层卷积层 45 weight_2 = variable_with_weight_losses(shape=[5, 5, 64, 64], stddev=5e-2, wl=0.0) 46 kernel_2 = tf.nn.conv2d(norm_1, weight_2, [1, 1, 1, 1], padding=‘SAME‘) 47 bias_2 = tf.Variable(tf.constant(0.1, shape=[64])) 48 49 conv_2 = tf.nn.relu(tf.nn.bias_add(kernel_2, bias_2)) 50 norm_2 = tf.nn.lrn(conv_2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75) 51 pool_2 = tf.nn.max_pool(norm_2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding=‘SAME‘) 52 53 # 全连接层 54 reshape = tf.reshape(pool_2, [batch_size, -1]) 55 dim = reshape.get_shape()[1].value 56 57 weight_3 = variable_with_weight_losses(shape=[dim, 384], stddev=0.04, wl=0.004) 58 bias_3 = tf.Variable(tf.constant(0.1, shape=[384])) 59 local_3 = tf.nn.relu(tf.matmul(reshape, weight_3) + bias_3) 60 61 # 第二层全连接层 62 weight_4 = variable_with_weight_losses(shape=[384, 192], stddev=0.04, wl=0.004) 63 bias_4 = tf.Variable(tf.constant(0.1, shape=[192])) 64 local_4 = tf.nn.relu(tf.matmul(local_3, weight_4) + bias_4) 65 66 # 结果层 67 weight_5 = variable_with_weight_losses(shape=[192, 10], stddev=1/192.0, wl=0.0) 68 bias_5 = tf.Variable(tf.constant(0.0, shape=[10])) 69 logits = tf.add(tf.matmul(local_4, weight_5), bias_5) 70 71 def loss(logits, labels): 72 labels = tf.cast(labels, tf.int64) 73 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits( 74 logits=logits, 75 labels=labels, 76 name="cross_entropy_per_example" 77 ) 78 cross_entropy_mean = tf.reduce_mean(cross_entropy, name="cross_entropy") 79 tf.add_to_collection("losses", cross_entropy_mean) 80 return tf.add_n(tf.get_collection("losses"), name="total_loss") 81 82 loss = loss(logits=logits, labels=label_holder) 83 train_op = tf.train.AdamOptimizer(1e-3).minimize(loss) 84 top_k_op = tf.nn.in_top_k(logits, label_holder, 1) 85 sess = tf.InteractiveSession() 86 tf.global_variables_initializer().run() 87 tf.train.start_queue_runners() 88 89 # 训练 90 for step in range(max_steps): 91 start_time = time.time() 92 image_batch, label_batch = sess.run([images_train, labels_train]) 93 _, loss_value = sess.run([train_op, loss], feed_dict={image_holder: image_batch, label_holder: label_batch}) 94 duration = time.time() - start_time 95 96 if step % 10 == 0: 97 examples_per_sec = batch_size / duration 98 sec_per_batch = float(duration) 99 100 format_str = "step %d, loss =%.2f (%.1f examples/sec; %.3f sec/batch" 101 print(format_str % (step, loss_value, examples_per_sec, sec_per_batch)) 102 103 # 评估模型 104 num_examples = 10000 105 num_iter = int(math.ceil(num_examples / batch_size)) 106 true_count = 0 107 total_sample_count = num_iter * batch_size 108 step = 0 109 while step < num_iter: 110 image_batch, label_batch = sess.run([images_test, labels_test]) 111 predictions = sess.run([top_k_op], feed_dict={image_holder: image_batch, label_holder: label_batch}) 112 true_count += np.sum(predictions) 113 step += 1 114 115 precision = true_count / total_sample_count 116 print("precision @ 1 = %.3f" % precision)
过程:


Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes. step 0, loss =4.68 (19.0 examples/sec; 6.734 sec/batch step 10, loss =3.58 (62.1 examples/sec; 2.062 sec/batch step 20, loss =3.09 (62.5 examples/sec; 2.047 sec/batch step 30, loss =2.77 (62.5 examples/sec; 2.047 sec/batch step 40, loss =2.48 (62.5 examples/sec; 2.047 sec/batch step 50, loss =2.36 (62.5 examples/sec; 2.047 sec/batch step 60, loss =2.13 (60.2 examples/sec; 2.125 sec/batch step 70, loss =1.95 (63.0 examples/sec; 2.031 sec/batch step 80, loss =2.01 (62.1 examples/sec; 2.062 sec/batch step 90, loss =1.90 (63.5 examples/sec; 2.016 sec/batch step 100, loss =1.93 (62.5 examples/sec; 2.047 sec/batch step 110, loss =1.96 (62.1 examples/sec; 2.062 sec/batch step 120, loss =1.92 (62.3 examples/sec; 2.055 sec/batch step 130, loss =1.81 (63.5 examples/sec; 2.016 sec/batch step 140, loss =1.86 (59.8 examples/sec; 2.141 sec/batch step 150, loss =1.88 (64.0 examples/sec; 2.000 sec/batch step 160, loss =1.87 (62.5 examples/sec; 2.047 sec/batch step 170, loss =1.73 (49.6 examples/sec; 2.578 sec/batch step 180, loss =1.86 (62.1 examples/sec; 2.062 sec/batch step 190, loss =1.71 (62.5 examples/sec; 2.047 sec/batch step 200, loss =1.63 (63.0 examples/sec; 2.031 sec/batch step 210, loss =1.63 (63.5 examples/sec; 2.016 sec/batch step 220, loss =1.67 (62.1 examples/sec; 2.063 sec/batch step 230, loss =1.72 (62.5 examples/sec; 2.047 sec/batch step 240, loss =1.76 (62.1 examples/sec; 2.062 sec/batch step 250, loss =1.67 (61.6 examples/sec; 2.078 sec/batch step 260, loss =1.67 (62.5 examples/sec; 2.047 sec/batch step 270, loss =1.59 (63.0 examples/sec; 2.031 sec/batch step 280, loss =1.55 (62.5 examples/sec; 2.047 sec/batch step 290, loss =1.64 (62.5 examples/sec; 2.047 sec/batch step 300, loss =1.63 (62.1 examples/sec; 2.062 sec/batch step 310, loss =1.49 (62.1 examples/sec; 2.062 sec/batch step 320, loss =1.49 (62.5 examples/sec; 2.047 sec/batch step 330, loss =1.61 (62.1 examples/sec; 2.062 sec/batch step 340, loss =1.55 (61.1 examples/sec; 2.094 sec/batch step 350, loss =1.63 (62.5 examples/sec; 2.047 sec/batch step 360, loss =1.75 (61.6 examples/sec; 2.078 sec/batch step 370, loss =1.54 (61.1 examples/sec; 2.094 sec/batch step 380, loss =1.66 (61.6 examples/sec; 2.078 sec/batch step 390, loss =1.66 (62.1 examples/sec; 2.062 sec/batch step 400, loss =1.74 (62.1 examples/sec; 2.062 sec/batch step 410, loss =1.60 (61.6 examples/sec; 2.078 sec/batch step 420, loss =1.64 (62.5 examples/sec; 2.047 sec/batch step 430, loss =1.59 (61.1 examples/sec; 2.094 sec/batch step 440, loss =1.64 (59.8 examples/sec; 2.141 sec/batch step 450, loss =1.67 (62.5 examples/sec; 2.047 sec/batch step 460, loss =1.35 (60.7 examples/sec; 2.109 sec/batch step 470, loss =1.45 (63.5 examples/sec; 2.016 sec/batch step 480, loss =1.47 (62.5 examples/sec; 2.047 sec/batch step 490, loss =1.37 (61.6 examples/sec; 2.078 sec/batch step 500, loss =1.64 (63.0 examples/sec; 2.031 sec/batch step 510, loss =1.58 (64.0 examples/sec; 2.000 sec/batch step 520, loss =1.36 (63.5 examples/sec; 2.016 sec/batch step 530, loss =1.30 (61.6 examples/sec; 2.078 sec/batch step 540, loss =1.49 (62.5 examples/sec; 2.047 sec/batch step 550, loss =1.46 (62.5 examples/sec; 2.047 sec/batch step 560, loss =1.58 (63.0 examples/sec; 2.031 sec/batch step 570, loss =1.46 (63.5 examples/sec; 2.016 sec/batch step 580, loss =1.49 (64.5 examples/sec; 1.984 sec/batch step 590, loss =1.30 (64.0 examples/sec; 2.000 sec/batch step 600, loss =1.39 (64.5 examples/sec; 1.984 sec/batch step 610, loss =1.62 (63.0 examples/sec; 2.031 sec/batch step 620, loss =1.41 (62.1 examples/sec; 2.062 sec/batch step 630, loss =1.29 (62.5 examples/sec; 2.047 sec/batch step 640, loss =1.42 (63.5 examples/sec; 2.016 sec/batch step 650, loss =1.36 (63.0 examples/sec; 2.031 sec/batch step 660, loss =1.46 (63.5 examples/sec; 2.016 sec/batch step 670, loss =1.26 (63.0 examples/sec; 2.031 sec/batch step 680, loss =1.64 (62.1 examples/sec; 2.062 sec/batch step 690, loss =1.39 (63.0 examples/sec; 2.031 sec/batch step 700, loss =1.32 (61.6 examples/sec; 2.078 sec/batch step 710, loss =1.36 (61.6 examples/sec; 2.078 sec/batch step 720, loss =1.51 (62.1 examples/sec; 2.062 sec/batch step 730, loss =1.48 (63.5 examples/sec; 2.016 sec/batch step 740, loss =1.34 (61.1 examples/sec; 2.094 sec/batch step 750, loss =1.44 (61.1 examples/sec; 2.094 sec/batch step 760, loss =1.34 (60.7 examples/sec; 2.109 sec/batch step 770, loss =1.46 (61.1 examples/sec; 2.094 sec/batch step 780, loss =1.46 (60.7 examples/sec; 2.109 sec/batch step 790, loss =1.42 (61.1 examples/sec; 2.094 sec/batch step 800, loss =1.40 (63.0 examples/sec; 2.031 sec/batch step 810, loss =1.46 (61.6 examples/sec; 2.078 sec/batch step 820, loss =1.32 (62.1 examples/sec; 2.062 sec/batch step 830, loss =1.46 (62.5 examples/sec; 2.047 sec/batch step 840, loss =1.27 (64.0 examples/sec; 2.000 sec/batch step 850, loss =1.38 (62.5 examples/sec; 2.047 sec/batch step 860, loss =1.30 (63.0 examples/sec; 2.031 sec/batch step 870, loss =1.18 (63.0 examples/sec; 2.031 sec/batch step 880, loss =1.39 (62.5 examples/sec; 2.047 sec/batch step 890, loss =1.17 (63.5 examples/sec; 2.016 sec/batch step 900, loss =1.27 (62.1 examples/sec; 2.062 sec/batch step 910, loss =1.38 (60.7 examples/sec; 2.109 sec/batch step 920, loss =1.64 (60.2 examples/sec; 2.125 sec/batch step 930, loss =1.45 (60.7 examples/sec; 2.109 sec/batch step 940, loss =1.39 (61.6 examples/sec; 2.078 sec/batch step 950, loss =1.40 (63.5 examples/sec; 2.016 sec/batch step 960, loss =1.32 (62.1 examples/sec; 2.063 sec/batch step 970, loss =1.32 (63.0 examples/sec; 2.031 sec/batch step 980, loss =1.28 (61.6 examples/sec; 2.078 sec/batch step 990, loss =1.20 (63.5 examples/sec; 2.016 sec/batch
结果:
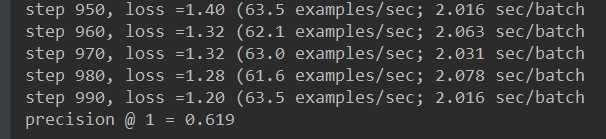
分析:
cifar10数据集比mnist数据集更完整也更复杂,基于cifar数据集进行10分类比mnist有更高的难度,整体的准确率和召回率都普遍偏低,但适当的增加迭代次数和卷积核的大小有助于提升准确度,大概能到80%,要想获得更高的准确度可以增加训练集的数量!
以上是关于基于cifar10实现卷积神经网络图像识别的主要内容,如果未能解决你的问题,请参考以下文章