分类与监督学习,朴素贝叶斯分类算法
Posted cx1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分类与监督学习,朴素贝叶斯分类算法相关的知识,希望对你有一定的参考价值。
1.简述分类与聚类的联系与区别。
分类技术是一种有指导的学习,即每个训练样本的数据对象已经有类标识,对数据进行判断。
聚类是一种无指导学习。也就是说,聚类是在预先不知道欲划分类的情况下,根据信息相似度原则进行信息聚类的一种方法。
简述什么是监督学习与无监督学习。
监督式学习,能够由训练资料中学到或建立一个模式,并依此模式猜測新的实例。
无监督式学习,其目的是去对原始资料进行分类,以便了解资料内部结构。有别于监督式学习网络,无监督式学习网络在学习时并不知道其分类结果是否正确,亦即没有受监 督式增强(告诉它何种学习是正确的)。其特点是仅对此种网络提供输入范例。而它会自己主动从这些范例中找出其潜在类别规则。
2.朴素贝叶斯分类算法实例
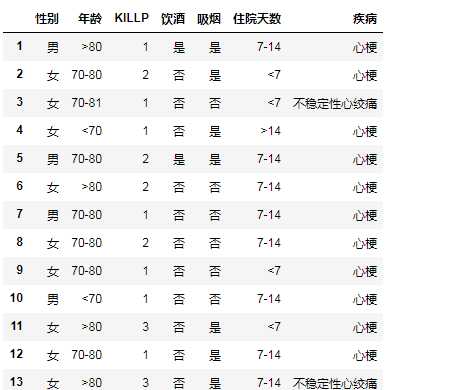
利用关于心脏情患者的临床数据集,建立朴素贝叶斯分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:–心梗–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I‘,饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传演算过程。

3.编程实现朴素贝叶斯分类算法
利用训练数据集,建立分类模型。
输入待分类项,输出分类结果。
可以心脏情患者的临床数据为例,但要对数据预处理。
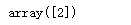
iris.target[55]

from sklearn.naive_bayes import GaussianNB #模型 gnb=GaussianNB() #训练 gnb.fit(iris.data,iris.target) #分类 gnb.predict([[9.5,3.0,5.5,2.3]])
from sklearn.naive_bayes import GaussianNB import numpy as np import pandas data=pandas.read_excel(‘心脏病患者临床数据.xlsx‘) data
#对数据进行预处理 x1=[] for a in data[‘性别‘]: if a==‘男‘: #男是1 x1.append(1) else: x1.append(2) #女是2 x2=[] for b in data[‘年龄‘]: if b ==‘<70‘: #<70是1 x2.append(1) elif b ==‘70-80‘: #70-80是2 x2.append(2) else: x2.append(3) #>80是3 x4=[] for d in data[‘饮酒‘]: if d==‘<7‘: #饮酒是1 x3.append(1) else: x4.append(2) #不饮酒是2 x5=[] for e in data[‘吸烟‘]: if e==‘<7‘: #吸烟是1 x5.append(1) else: x5.append(2) #不吸烟是2 x6=[] for f in data[‘住院天数‘]: if f==‘<7‘: #<7是1 x6.append(1) elif c==‘7-14‘: #7-14是2 x6.append(2) else: x6.append(3) #>14是3

以上是关于分类与监督学习,朴素贝叶斯分类算法的主要内容,如果未能解决你的问题,请参考以下文章