人脸核身技术原理架构与开发
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人脸核身技术原理架构与开发相关的知识,希望对你有一定的参考价值。
1. 概述
人脸核身指通过×××OCR等技术来构建包含用户真实身份信息的底库,通过指定方式获取用户真实照片,利用人脸比对技术秒级确认用户身份的技术。
人脸核身技术可用于远程身份认证、刷脸门禁考勤、安防监控等场景。图 1的思维导图简单描述了人脸核身面临的问题和包含的技术。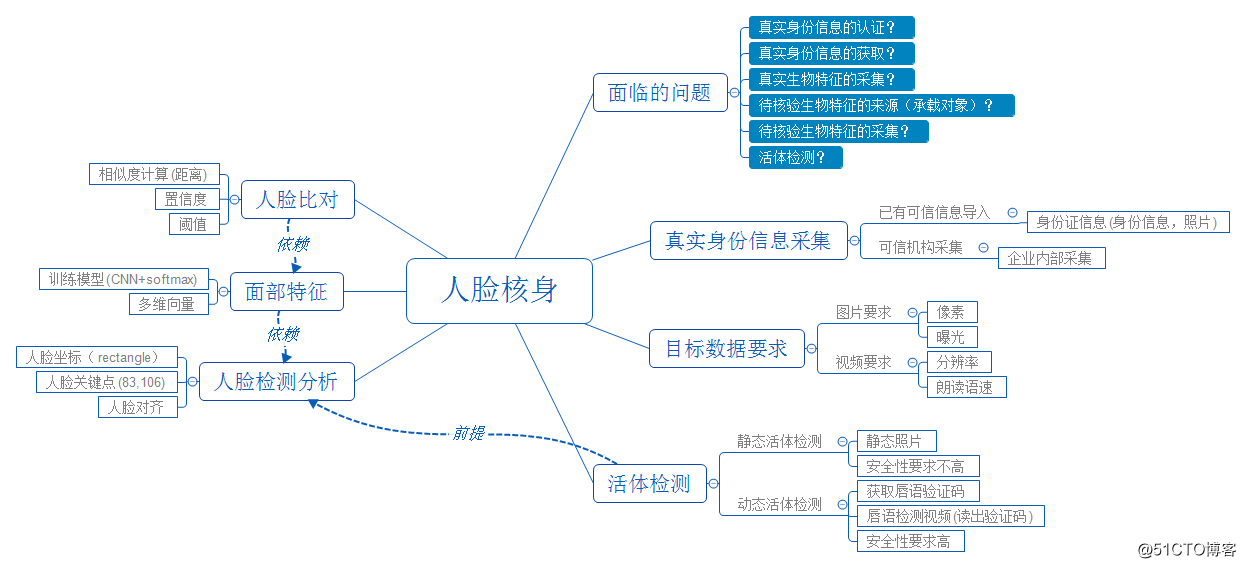
2. 涉及技术
2.1. 用户身份采集
采集真实用户身份信息与图片构成人脸比对的底库。使用用户×××OCR技术实现用户身份信息的自动采集是目前较常用的方式。
对于特定领域范围内的应用(如企业内部的人脸门禁),可由可信机构使用人脸采集设备进行离线采集。
对于使用云服务的第三方应用,可由第三方应用使用云服务建立用户信息库,由应用采集用户信息存入云服务中。
2.2. 活体检测
人脸活体检测技术在人脸识别过程中判断操作用户是否为真人,有效抵御照片、视频、模具等作弊***,保障业务安全。
百度云网站上[1]描述了下面几种活体检测方法:
- 动作配合式活体检测:SDK给出指定动作要求,用户需配合完成,通过实时检测用户眼睛,嘴巴,头部姿态的状态,来判断是否是活体。支持7种预设动作,可自定义哪些生效以及检测顺序。
- 在线图片活体检测:基于图片中人像的破绽(摩尔纹、成像畸形等)来判断目标对象是否为活体,可有效防止屏幕二次翻拍等作弊***,可使用单张或多张判断逻辑。
- H5视频活体检测:用户上传一个现场录制的视频,录制时读出随机分配的语音校验码。然后通过分析这个视频的人脸信息以及语音校验码是否匹配,完成活体检测判断。
- 离线RGB活体检测:在线图片活体的离线版本,相对于在线接口方式,本地处理速度更快,无需担心是否有网络,也无需考虑接口调用次数等消耗。
- 离线近红外活体检测:利用近红外成像原理,实现夜间或无自然光条件下的活体判断。其成像特点(如屏幕无法成像,不同材质反射率不同等)可以实现高鲁棒性的活体判断。
- 离线3D结构光活体检测:基于3D结构光成像原理,通过人脸表面反射光线构建深度图像,判断目标对象是否为活体,可强效防御图片、视频、屏幕、模具等***。
2.3. 人脸识别
人脸识别是人脸检测,人脸对齐,人脸特征提取,人脸分析,人脸比对技术的综合应用。
使用机器学习(实际应用中使用的算法可以不同)进行人脸识别的原理[2,3]简单描述如下:- 在图像中找出人脸部分:将图像转换为黑白图像,使用方向梯度直方图(Histogram of Oriented Gradients,简称 HOG)的方法:将像素从明向暗变化的方向定义为梯度,将图像分割成一些 16×16 像素的小方块,通过计算每个小方块中的梯度(以指向性最强的方向代替小方块)将图像表示为HOG 形式,以捕获图像的主要特征。通过将目标图像的HOG与已训练好的HOG进行相似度的比较,可以判断出目标图像的人脸区域。
- 人脸对齐:脸上普遍存在的特定点被称为特征点(landmarks),一般被定义为68个(如图 2所示)。可使用机器学习算法找到人脸上的这68个特征点,使用那些能够保持图片相对平行的基本图像变换,例如旋转和缩放(称为仿射变换)可使得即使目标人脸具有不同的姿态,都能将眼睛和嘴巴向中间挪动到大致相同的位置,为下一步的面部特征提取做好准备。
- 人脸特征提取:使用三元组(一张已知的人的面部训练图像,同一个人的另一张照片,另外一个人的照片)训练一个深度卷积神经网络,让它为脸部生成 n 个测量值(同一人的测量值相近,而不同人的测量值有差异),这里把每张脸的n个测量值称为一个嵌入(embedding)。机器学习将一个复杂的图像转换为一个数字向量(embedding)用于计算。
- 人脸比对:使用目标人脸在底库中比对的过程可视为一个分类过程,需要训练一个分类器(可使用一个简单的线性 SVM 分类器),使用人脸测量值(embedding)作为输入进行训练,而输出的每一个类别就代表底库中的每一个人。

卷积神经网络近年来在人脸识别技术中被广泛应用,如使用DeepID[4,5]这样的学习模型将人脸图片转换为一个多维向量描述的面部特征。
图 3显示了DeepID的特征提取流程。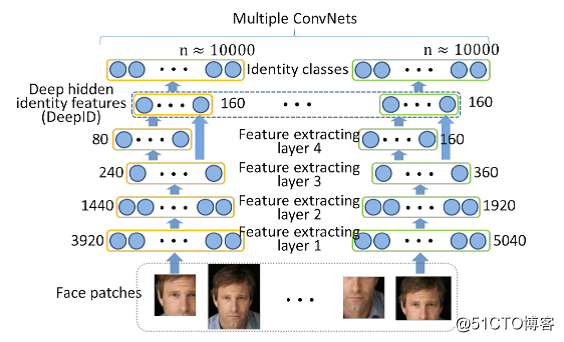
DeepID将一张人脸图片分为对应人脸10个区域的60个块(face patchs)作为输入,每个块为39×31×k(RGB值时k为3,灰度值时k为1)的长方形或31×31×k的正方形。每个人脸块作为一个卷积网络的输入进行训练,网络的最后一个隐藏层神经元做为所抽取的特征,这些特征被输出为n(如10000)个身份类别。DeepID使用60个卷积网络进行训练和预测,每个卷积网络对每个输入块抽取出两个160维的向量,这样对于一张人脸的特征向量长度为19200维(160×2×60)。
图 4显示了DeepID中的卷积网络架构。可以看到底层网络的特征随着层数的递进而减少,第4层以后剩下的已经是高层次的人脸特征了。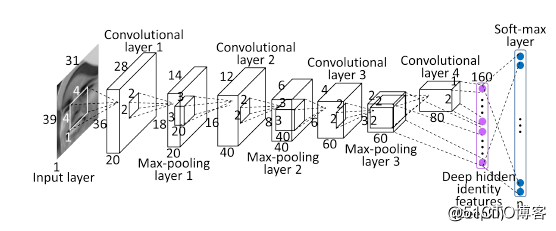
得到到特征向量后,进行人脸的识别(比对)可以有多种方法。在论文[4]中除了介绍联合贝叶斯(Joint Bayesian)分类方法外,还介绍了一种神经网络分类方法,如图 5所示。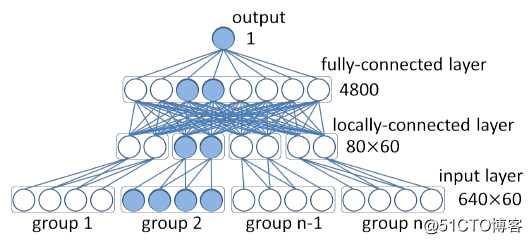
该神经网络的输入层为使用DeepID抽取的特征向量。将输入向量分为60组,每个组中包含目标图片和底库图片对应同一输入块的特征向量(一张图片的这个块特征向量为160×2维,两张则为640维)。输出只有一个神经元,即为这两张图片的相似度。3. 应用架构
本文将人脸核身系统的架构分为三种:在线架构、离线架构、混合架构。
3.1. 在线架构
在线架构适合网络条件良好、人脸库庞大(万级别以上)、需要跨地域人脸库同步等场景。常用于大规模级别的人脸识别业务。系统架构如图 6所示。
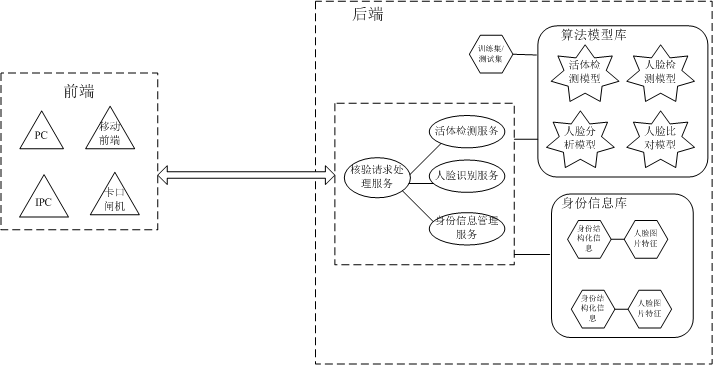
在线架构的人脸核身流程通常为:前端设备根据支持的活体检测手段向后端提交视频(如唇语验证码手段)或图像(静态检测),活体检测通过后,后端将从提交的视频或图像中检测出的人脸图像与后端的身份信息库(底库)中用户人脸特征进行1:1比对,比对结果超过设定阈值则认为核身通过。
在线架构的一种变形模式是前端设备向后端传递的不是原始的图像数据,而是使用人脸特征提取模型计算得到人脸特征数据,这种方式能降低通讯开销和后端的运算负载,但要求前后端使用的计算模型相同,且需要保持模型的同步更新。3.2. 离线架构
离线架构适合于网络条件不稳定、无网、数据安全性要求高、人脸库较小(通常为1万人以下)单台设备的人脸识别场景。常见于人证核验机、人脸门禁/闸机、企业考勤机、自助柜机等。
离线架构中根据是否存贮底库数据分为无底库模式与有底库模式。3.2.1. 无底库模式
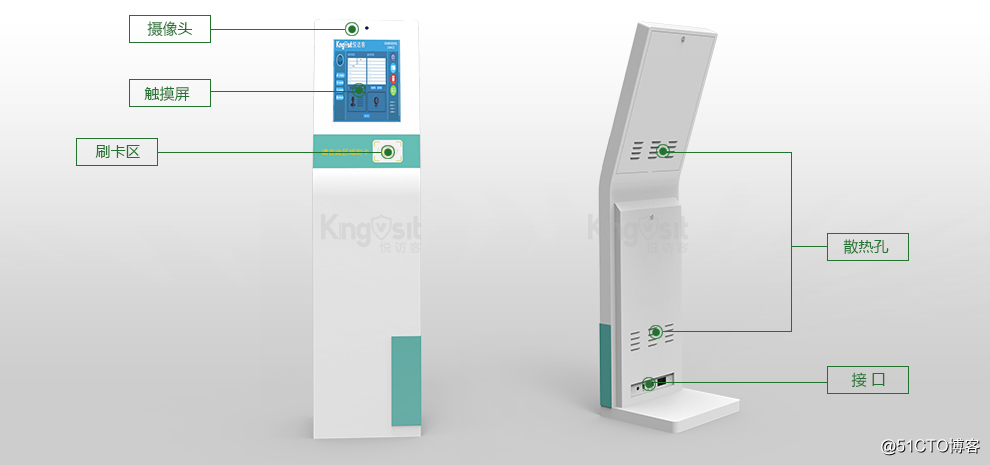
无底库模式适用于实时采集底库人脸图像与目标人脸图像进行比对的场景,一个典型的用例是人证核验一体机:该终端包含×××读卡器,可实时读取×××中的身份信息与人脸图片,并包含摄像头实时采集目标人脸图像,与读卡器得到的×××人脸图片进行比对完成认证合一验证的功能。图 7展示了一个人证核验一体机。
3.2.2. 有底库模式
办公楼宇/生活小区的人脸门禁/闸机可使用有底库模式的离线架构。在人脸门禁中保存一个允许通过的白名单底库,底库中存储着白名单人员的身份信息与人脸图片(特征)。当目标经过人脸门禁时,人脸门禁在本地的白名单底库中实现1:N的人脸搜索比对。通过离线人脸搜索,完成通行者身份核验,避免网络因素等干扰,确保业务稳定高效运行。
3.3. 混合架构
混合结构适合于网络条件较好,人脸库较小(1万以下)但变更频繁的场景,如授权人员变更频繁的商业楼宇人脸门禁,这时人脸门禁可由后端的人员库更新通知,及时更新本地人脸门禁中存储的白名单底库。
这里把混合架构分为几种模式。3.3.1. 前端1:N比对模式
这种模式的架构如图 8所示。
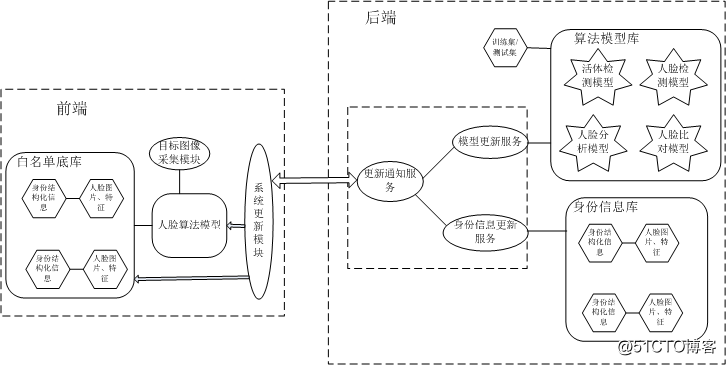
这种模式下,前端维护一个白名单底库和系列人脸算法模型,目标人脸的1:N比对在前端完成。后端主要提供算法模型与身份信息库对前端的更新,当后端的算法模型优化演进后,可由后端通知到前端,有前端进行更新;当后端的身份信息库发生更新时,也可以实时通知到前端进行更新,实现实时的人脸核证更新。3.3.2. 前端1:1比对模式
这种模式的架构如图 9所示。
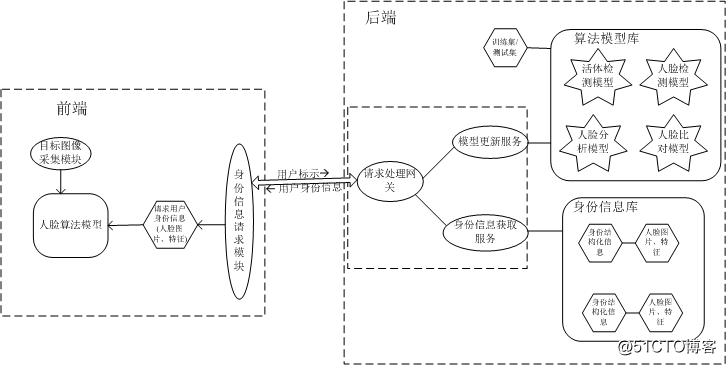
这种模式下,前端不再维护白名单底库,在需要进行比对时,实时从后端获取目标图像对应用户的身份信息(人脸图片、特征)实现1:1比对。这种模式需要前端在向后端请求用户身份信息时携带用户标识。4. 云服务与开源
4.1. 开源软件
4.1.1. opencv
OpenCV(开源计算机视觉库)是在BSD许可下发布的,因此对学术和商业使用都是免费的。它有c++、Python和Java接口,支持Windows、Linux、Mac OS、ios和android。OpenCV是为计算效率而设计的,并且非常注重实时应用。用优化的C/ c++编写的库可以利用多核处理。使用OpenCL,它可以利用底层异构计算平台的硬件加速。
从OpenCV2.4开始,加入了新的类FaceRecognizer,可以使用它便捷地进行人脸识别。
其github地址为:https://github.com/opencv
OpenCV目前最新的版本为4.0版本,图 10显示了OpenCV中与人脸有关的类: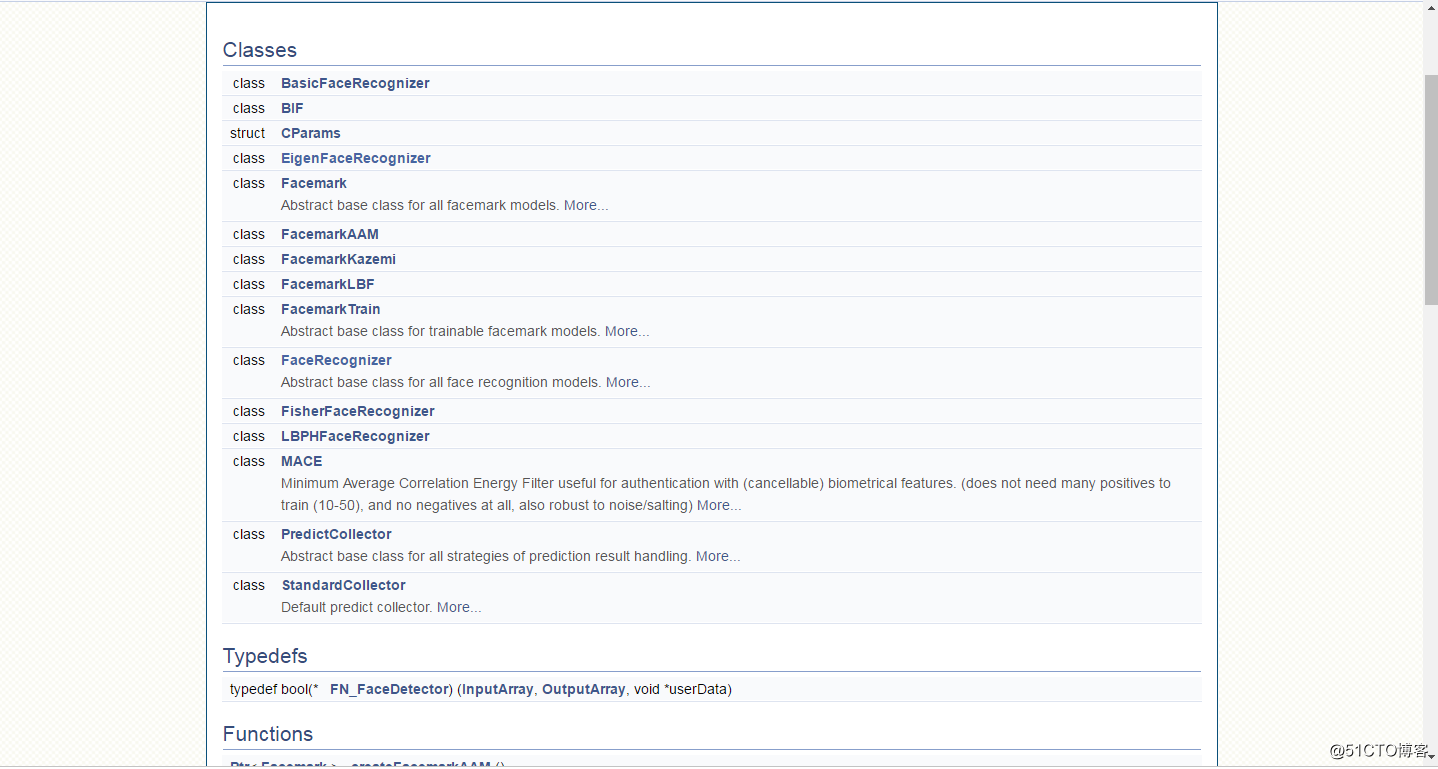
为支持web应用,OpenCV.js利用Emscripten将OpenCV函数编译成asm.js或WebAssembly目标,并提供可访问的JS API。OpenCV.js是针对web平台对OpenCV函数选定子集的javascript绑定。它使得web前端应用得益于OpenCV强大的多媒体处理功能。
可以看看OpenCV.js能够提供什么功能[6]:
- 读取和显示图像和视频(使用WebRTC和canvas元素实现视频的捕获);
- 提供丰富的图像处理功能,如:改变颜色,图像的几何变换,图像阈值化,图像平滑化,形态变换,发现图像梯度,Canny边缘检测,图像金字塔,图像的傅里叶变换、余弦变换, Hough转换,图像分割、前景提取等;
- 提供视频处理功能,如:视频中对象轨迹跟踪(Meanshift和Camshift算法),背景处理等;
- 提供人脸检测(使用预先学习好的模型,载入对应的xml文件,可在视频流中检测)功能。
4.1.2. Dlib
Dlib是一个包含机器学习算法和工具的现代c++工具包,用于在c++中创建复杂的软件来解决现实世界中的问题。。
其github地址为:https://github.com/davisking/dlib
其文档地址为:http://dlib.net
dlib可提供C++和python的调用,其提供的算法库中包括高质量的人脸识别[7]算法。4.1.3. OpenFace
OpenFace是一个使用python语言和Torch框架开发的基于深度神经网络的开源人脸识别系统。该系统的理论基础基于谷歌的文章《FaceNet: A Unified Embedding for Face Recognition and Clustering》[8]。
其github地址为:https://github.com/cmusatyalab/openface
其文档地址为:http://cmusatyalab.github.io/openface/
其工作流程如下:- 用dlib或OpenCV的预先训练好的模型来检测人脸。
- 为神经网络的计算而变换人脸(对齐)。使用dlib的实时姿态估计和OpenCV的仿射变换,试图使眼睛和下唇出现在每个图像的相同位置。
- 使用深度神经网络将人脸表示为128维超球面单元 (unit hypersphere)。这种表示具有一个特性:即两个面部特征向量之间的距离越大,就意味着这两张脸可能不是同一个人的,该特性使得聚类、相似性检测和分类任务更容易。
- 可将适用的聚类或分类技术应用到特征向量上,完成识别任务。
示意图如图 11所示。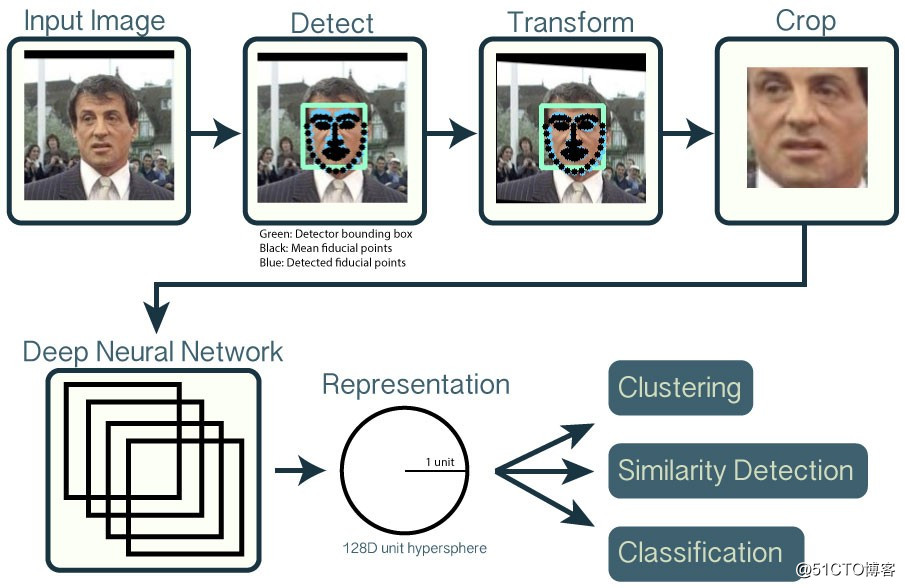
OpenFace中主要的package如下表所示。
| 类名 | 功能 |
|---|---|
| openface.AlignDlib | 使用dlib的特征点估计来对齐人脸,面向神经网络输入进行预处理。人脸被调整到相同的大小(如96x96),并进行转换,使特征点(如眼睛和鼻子)出现在每张图像的相同位置。 |
| openface.TorchNeuralNet | 使用Torch子流程进行特征提取。 |
| openface.data module | 对象包含图像元数据的对象。 |
| openface.helper module | 帮助模块。 |
4.1.4. SeetaFaceEngine
SeetaFace Engine是一个开源的人脸识别引擎,由中科院计算所山世光研究员带领的人脸识别研究组研发,使用C++实现,包含了人脸相关的一整套过程,包括:人脸检测、人脸对齐、人脸识别。
其github地址为:https://github.com/seetaface/SeetaFaceEngine
其开源代码可被编译为3个动态库(FaceDetection.dll,FaceAlignment.dll,Identification.dll)进行调用。
4.2. 云服务
4.2.1. 旷世科技
旷世科技提供人脸识别的云服务[9]接口,其API定义如图 12所示: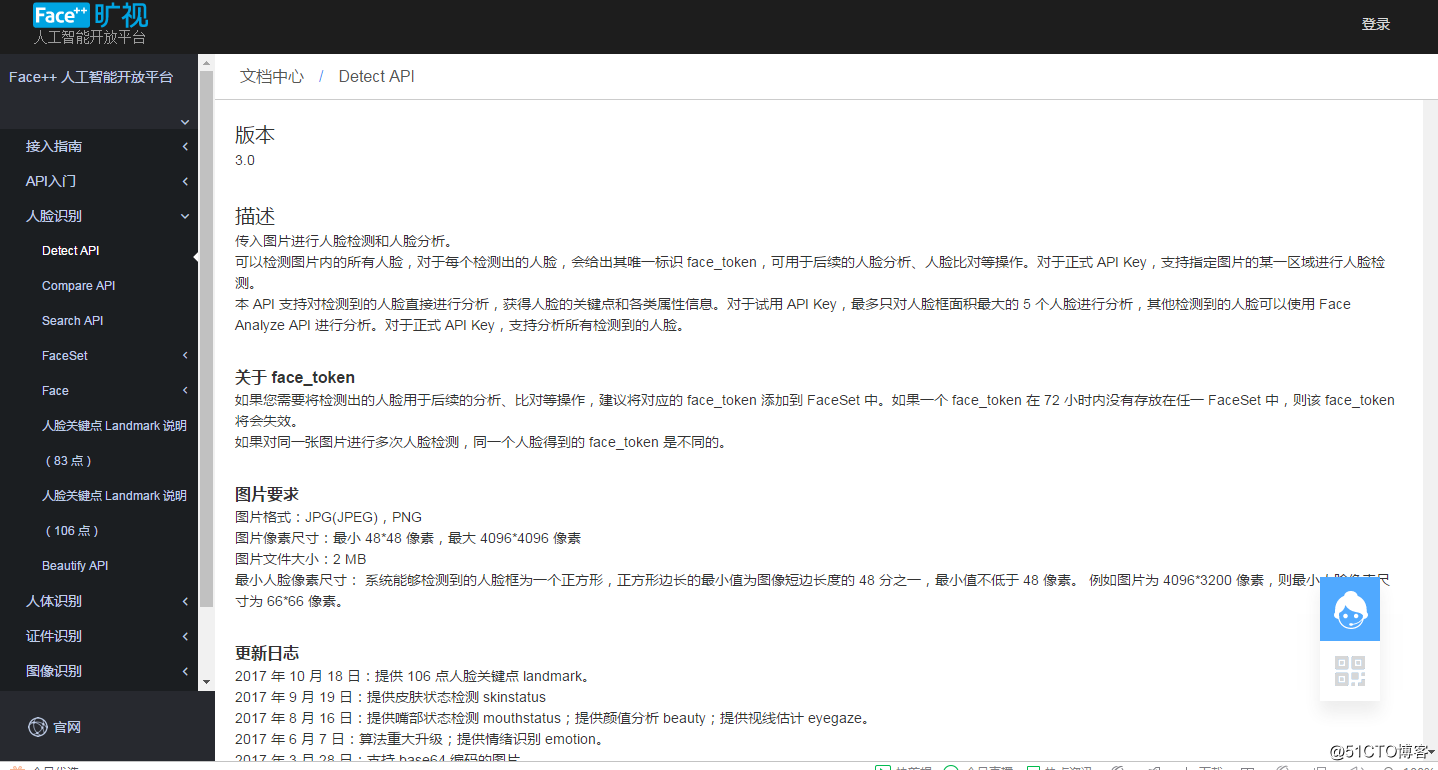
可以看到提供的服务接口能够实现人脸检测、人脸比对、识别功能,也提供云端人脸库的构建功能。
4.2.2. 腾讯云
腾讯云提供人脸识别的云服务[10]接口,其API定义如图 13所示: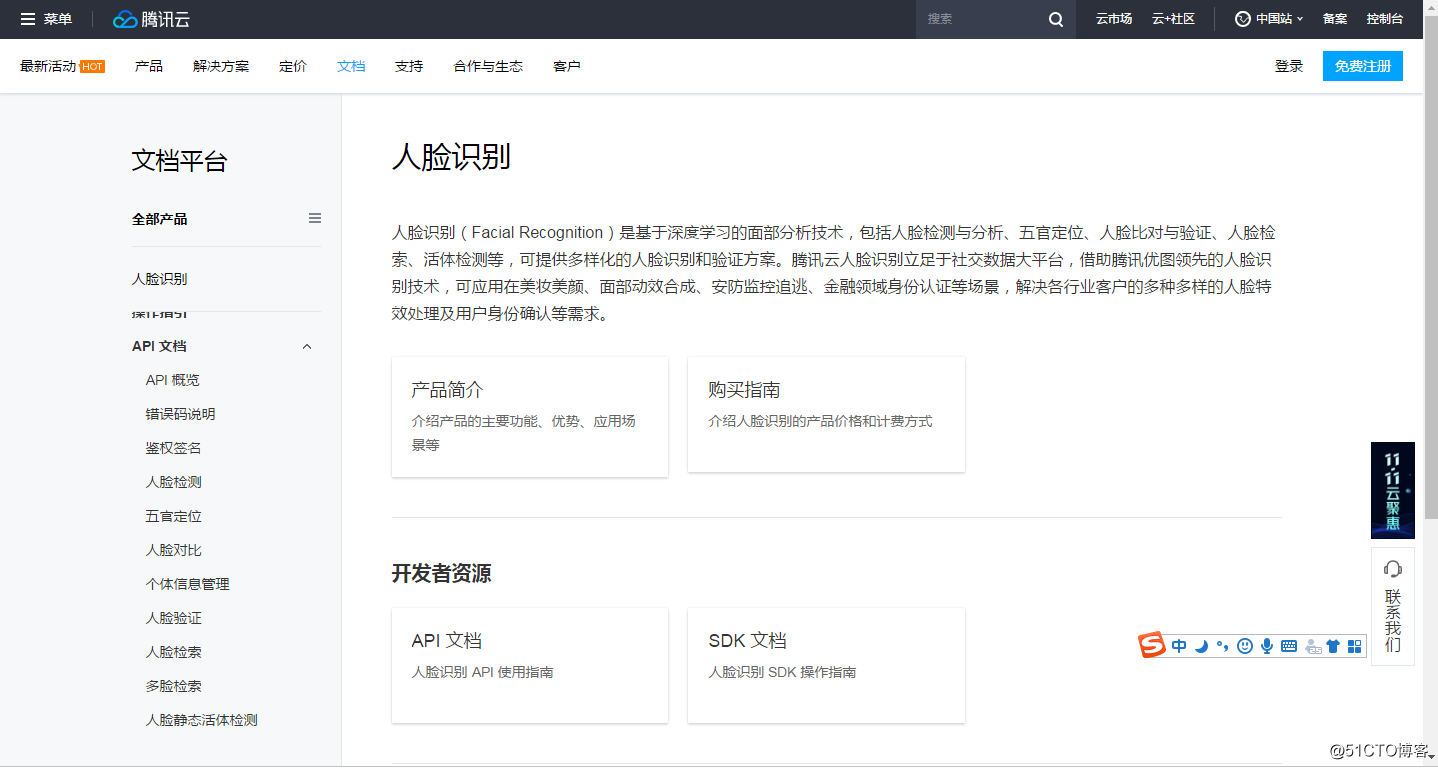
可以看到提供的服务接口能够实现人脸检测、人脸对比、验证功能,也提供云端个体信息管理(底库管理)功能。
4.2.3. 阿里云
阿里云提供人脸识别的云服务[11]接口,其API定义如图 13所示:
可以看到阿里云提供的服务接口能够实现人脸检测、人脸比对功能。
4.2.4. 百度云
百度云提供丰富的人脸识别服务接口[12],如图 15所示。
5. 参考文献
- https://cloud.baidu.com/product/face
- Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks,https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
- Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning, https://www.colabug.com/3548846.html
- Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898.
- DeepID人脸识别算法之三代,https://www.cnblogs.com/mfrbuaa/p/5394742.html
- https://docs.opencv.org/4.0.0/d5/d10/tutorial_js_root.html
- http://dlib.net/dnn_face_recognition_ex.cpp.html
- FaceNet: A Unified Embedding for Face Recognition and Clustering ,http://www.cv-foundation.org/openaccess/content_cvpr_2015/app/1A_089.pdf
- https://console.faceplusplus.com.cn/documents/4888373
- https://cloud.tencent.com/document/product/867
- https://help.aliyun.com/product/53257.html
- http://ai.baidu.com/docs#/Face-Detect-V3/top
以上是关于人脸核身技术原理架构与开发的主要内容,如果未能解决你的问题,请参考以下文章