一、并发容器
1.ConcurrentHashMap
为什么要使用ConcurrentHashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表
形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHashMap的一些有用的方法
很多时候我们希望在元素不存在时插入元素,我们一般会像下面那样写代码
synchronized(map){
if (map.get(key) == null){
return map.put(key, value);
} else{
return map.get(key);
}
}
putIfAbsent(key,value)方法原子性的实现了同样的功能
V putIfAbsent(K key, V value)
如果key对应的value不存在,则put进去,返回null。否则不put,返回已存在的value。
boolean remove(Object key, Object value)
如果key对应的值是value,则移除K-V,返回true。否则不移除,返回false。
boolean replace(K key, V oldValue, V newValue)
如果key对应的当前值是oldValue,则替换为newValue,返回true。否则不替换,返回false。
Hash的解释
散列,任意长度的输入,通过一种算法,变换成固定长度的输出。属于压缩的映射。
hash算法示例图演示:
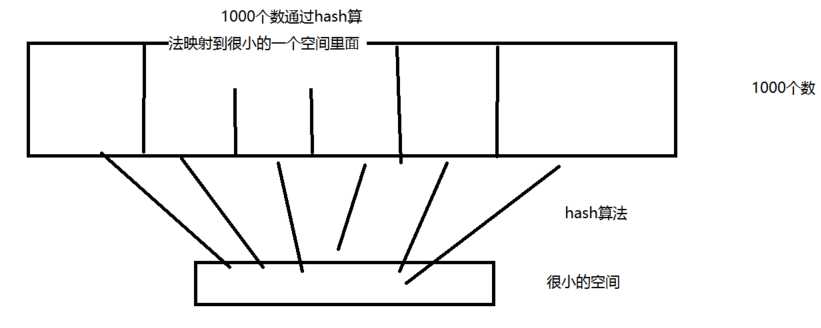
类似于HaspMap的实现就是使用散列,比如把1000个元素放到长度为10的hashmap里面去,放入之前会把这1000个数经过hash算法映射到10个数组里面去,这时候就会存在相同的映射值在一个数组的相同位置,就会产生hash碰撞,此时hashmap就会在产生碰撞的数组的后面使用Entry链表来存储相同映射的值,然后使用equals方法来判断同一个链表存储的值是否一样来获取值,链表就是hashmap用来解决碰撞的方法,所以我们一般在写一个类的时候要写自己的hashcode方法和equals方法,如果键的hashcode相同,再使用键的equals方法判断键内容是不是一样的,一样的就获取值
Md5,Sha,取余都是散列算法,ConcurrentHashMap中是wang/jenkins算法
ConcurrentHashMap在1.7下的实现
分段锁的设计思想。
分段锁的思想示例图:
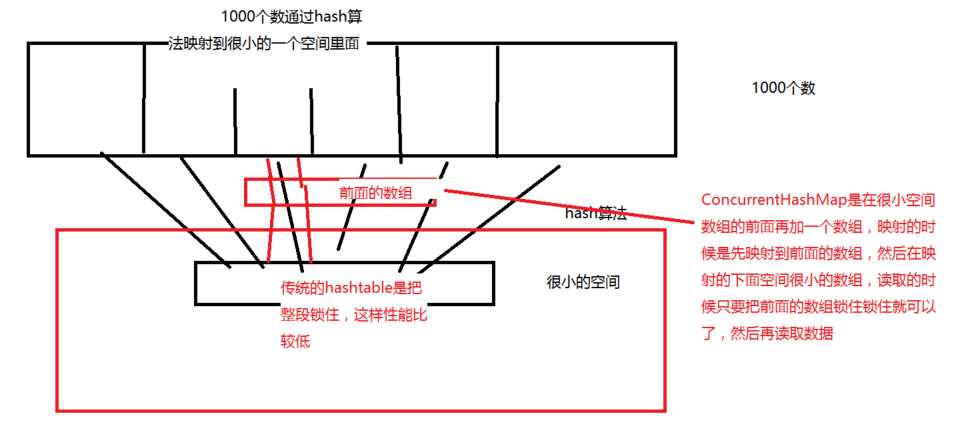
说明:
a)传统的hashtable是很小空间的数组整段锁住,这样性能比较低
b)ConcurrentHashMap是在很小空间数组的前面再加一个数组,映射的时候先映射到前面的数组,然后再映射到后面的很小空间的数组;读取的时候只需要把前面的数组锁住就可以了。这就是分段锁的思想
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment实际是一种可重入锁(ReentrantLock),也就是用于分段的锁。HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
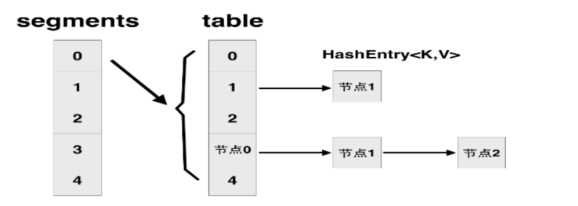
说明:上图存在两次散列的过程:比如插入一个1000的数,首先是把1000的位数(最多是高16位)做一次散列找到在segments数组中的位置,然后再把1000本身做一次散列找到在table中的位置
获取值时一样
ConcurrentHashMap初始化方法是通过initialCapacity、loadFactor和concurrencyLevel(参数concurrencyLevel是用户估计的并发级别,就是说你觉得最多有多少线程共同修改这个map,根据这个来确定Segment数组的大小concurrencyLevel默认是DEFAULT_CONCURRENCY_LEVEL = 16;)。
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,可以看到其中的对象属性要么是final的,要么是volatile的。
总结:ConcurrentHashMap在1.7及以下的实现使用数组+链表的方式,采用了分段锁的思想
ConcurrentHashMap在1.8下的实现
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
总结:ConcurrentHashMap在1.8下的实现使用数组+链表+红黑树的方式,当链表个数超过8的时候就把原来的链表转成红黑树,使用红黑树来存取,采用了元素锁的思想
2. ConcurrentSkipListMap 和ConcurrentSkipListSet
ConcurrentSkipListMap TreeMap的并发实现
ConcurrentSkipListSet TreeSet的并发实现
了解什么是SkipList?
二分查找和AVL树查找
二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存。这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了。
如果需要的是一个能够进行二分查找,又能快速添加和删除元素的数据结构,首先就是二叉查找树,二叉查找树在最坏情况下可能变成一个链表。
于是,就出现了平衡二叉树,根据平衡算法的不同有AVL树,B-Tree,B+Tree,红黑树等,但是AVL树实现起来比较复杂,平衡操作较难理解,这时候就可以用SkipList跳跃表结构。
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要O(n)的时间,查找操作需要O(n)的时间。

如果我们使用上图所示的跳跃表,就可以减少查找所需时间为O(n/2),因为我们可以先通过每个节点的最上面的指针先进行查找,这样子就能跳过一半的节点。
比如我们想查找19,首先和6比较,大于6之后,在和9进行比较,然后在和12进行比较......最后比较到21的时候,发现21大于19,说明查找的点在17和21之间,从这个过程中,我们可以看出,查找的时候跳过了3、7、12等点,因此查找的复杂度为O(n/2)。
跳跃表其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
跳跃表又被称为概率,或者说是随机化的数据结构,目前开源软件 Redis 和 lucence都有用到它。
3. ConcurrentLinkedQueue 无界非阻塞队列
ConcurrentLinkedQueue LinkedList 并发版本
Add,offer:添加元素
Peek():get头元素并不把元素拿走
poll():get头元素把元素拿走
4. CopyOnWriteArrayList和CopyOnWriteArraySet
写的时候进行复制,可以进行并发的读。
适用读多写少的场景:比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。
弱点:内存占用高,数据一致性弱
总结:写的时候重新复制一份数据,然后在复制的数据里面写入数据,写完以后再把原来的数据的引用执行复制的数据,所以存在数据的弱一致性,适用于读多写少的场景