各种优化器Optimizer的总结与比较
Posted bigcome
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了各种优化器Optimizer的总结与比较相关的知识,希望对你有一定的参考价值。
1.梯度下降法(Gradient Descent)
梯度下降法是最基本的一类优化器,目前主要分为三种梯度下降法:
标准梯度下降法(GD, Gradient Descent)
随机梯度下降法(SGD, Stochastic Gradient Descent)
批量梯度下降法(BGD, Batch Gradient Descent)
class tf.train.GradientDescentOptimizer 使用梯度下降算法的Optimizer
标准梯度下降法(GD)
假设要学习训练的模型参数为W,代价函数为J(W),则代价函数关于模型参数的偏导数即相关梯度为ΔJ(W),学习率为ηt,则使用梯度下降法更新参数为
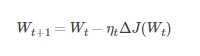
其中,Wt表示tt时刻的模型参数
从表达式来看,模型参数的更新调整,与代价函数关于模型参数的梯度有关,即沿着梯度的方向不断减小模型参数,从而最小化代价函数
基本策略可以理解为”在有限视距内寻找最快路径下山“,因此每走一步,参考当前位置最陡的方向(即梯度)进而迈出下一步
评价:标准梯度下降法主要有两个缺点:
训练速度慢:
每走一步都要要计算调整下一步的方向,下山的速度变慢
在应用于大型数据集中,每输入一个样本都要更新一次参数,且每次迭代都要遍历所有的样本
会使得训练过程及其缓慢,需要花费很长时间才能得到收敛解
容易陷入局部最优解:
由于是在有限视距内寻找下山的反向
当陷入平坦的洼地,会误以为到达了山地的最低点,从而不会继续往下走
所谓的局部最优解就是鞍点。落入鞍点,梯度为0,使得模型参数不在继续更新
批量梯度下降法(BGD)
假设批量训练样本总数为nn,每次输入和输出的样本分别为X(i),Y(i),模型参数为W,代价函数为J(W)
每输入一个样本ii代价函数关于W的梯度为ΔJi(Wt,X(i),Y(i)),学习率为ηt,则使用批量梯度下降法更新参数表达式为
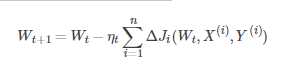
其中,WtWt表示tt时刻的模型参数
从表达式来看,模型参数的调整更新与全部输入样本的代价函数的和(即批量/全局误差)有关。
即每次权值调整发生在批量样本输入之后,而不是每输入一个样本就更新一次模型参数。这样就会大大加快训练速度。
基本策略可以理解为,在下山之前掌握了附近的地势情况,选择总体平均梯度最小的方向下山
评价:
批量梯度下降法比标准梯度下降法训练时间短,且每次下降的方向都很正确
随机梯度下降法(SGD)
对比批量梯度下降法,假设从一批训练样本n中随机选取一个样本is。
模型参数为W,代价函数为J(W),梯度为ΔJ(W),学习率为ηt,则使用随机梯度下降法更新参数表达式为
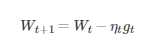
其中,gt=ΔJis(Wt;X(is);X(is)), is∈{1,2,...,n}表示随机选择的一个梯度方向,Wt表示t时刻的模型参数
E(gt)=ΔJ(Wt)E(gt)=ΔJ(Wt),这里虽然引入了随机性和噪声,但期望仍然等于正确的梯度下降
基本策略可以理解为随机梯度下降像是一个盲人下山,不用每走一步计算一次梯度,但是他总能下到山底,只不过过程会显得扭扭曲曲
评价:
优点:
虽然SGD需要走很多步的样子,但是对梯度的要求很低(计算梯度快)。而对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD都能很好地收敛。
应用大型数据集时,训练速度很快。比如每次从百万数据样本中,取几百个数据点,算一个SGD梯度,更新一下模型参数。
相比于标准梯度下降法的遍历全部样本,每输入一个样本更新一次参数,要快得多。
缺点:
SGD在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确。
此外,SGD也没能单独克服局部最优解的问题。
2.动量优化法
动量优化方法是在梯度下降法的基础上进行的改变,具有加速梯度下降的作用。一般有标准动量优化方法Momentum、NAG(Nesterov accelerated gradient)动量优化方法
NAG在Tensorflow中与Momentum合并在同一函数tf.train.MomentumOptimizer中,可以通过参数配置启用
Momentum
使用动量(Momentum)的随机梯度下降法(SGD),主要思想是引入一个积攒历史梯度信息动量来加速SGD
从训练集中取一个大小为nn的小批量{X(1),X(2),...,X(n)}样本,对应的真实值分别为Y(i),则Momentum优化表达式为:
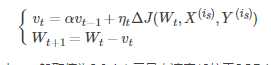
其中,vt表示t时刻积攒的加速度。α表示动力的大小,一般取值为0.9(表示最大速度10倍于SGD)。ΔJ(Wt,X(is),Y(is))含义见SGD算法。Wt表示t时刻模型参数
动量主要解决SGD的两个问题:一是随机梯度的方法(引入的噪声);二是Hessian矩阵病态问题(可以理解为SGD在收敛过程中和正确梯度相比来回摆动比较大的问题)。
理解策略为:由于当前权值的改变会受到上一次权值改变的影响,类似于小球向下滚动的时候带上了惯性。这样可以加快小球向下滚动的速度
NAG
牛顿加速梯度(NAG, Nesterov accelerated gradient)算法,是Momentum动量算法的变种。更新模型参数表达式如下
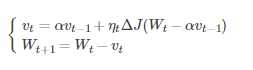
其中,vt表示t时刻积攒的加速度;α表示动力的大小;ηt表示学习率,Wt表示t时刻的模型参数,ΔJ(Wt?αvt?1)表示代价函数关于Wt的梯度
Nesterov动量梯度的计算在模型参数施加当前速度之后,因此可以理解为往标准动量中添加了一个校正因子
理解策略:在Momentun中小球会盲目地跟从下坡的梯度,容易发生错误。所以需要一个更聪明的小球,能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。
计算Wt?αvt?1可以表示小球下一个位置大概在哪里。从而可以提前知道下一个位置的梯度,然后使用到当前位置来更新参数
在凸批量梯度的情况下,Nesterov动量将额外误差收敛率从O(1/k)(k步后)改进到O(1/k2)。然而,在随机梯度情况下,Nesterov动量对收敛率的作用却不是很大
3.自适应学习率优化算法
自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法
AdaGrad算法
思想:
AdaGrad算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根
具有代价函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降。
算法描述:
AdaGrad算法优化策略一般可以表示为:
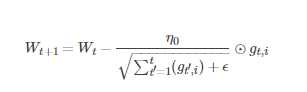
假定一个多分类问题,i表示第i个分类,t表示第t迭代同时也表示分类i累计出现的次数。η0表示初始的学习率取值一般为0.01,?是一个取值很小的数(一般为1e-8)为了避免分母为0。
Wt表示t时刻即第t迭代模型的参数,gt,i=ΔJ(Wt,i)表示t时刻,指定分类ii,代价函数J(?)关于W的梯度。
从表达式可以看出,对出现比较多的类别数据,Adagrad给予越来越小的学习率,而对于比较少的类别数据,会给予较大的学习率。因此Adagrad适用于数据稀疏或者分布不平衡的数据集。
Adagrad 的主要优势在于不需要人为的调节学习率,它可以自动调节;缺点在于,随着迭代次数增多,学习率会越来越小,最终会趋近于0
RMSProp算法
思想:
RMSProp算法修改了AdaGrad的梯度积累为指数加权的移动平均,使得其在非凸设定下效果更好。
算法描述:
RMSProp算法的一般策略可以表示为:
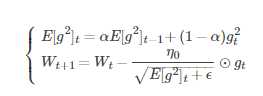
其中,Wt表示tt时刻即第t迭代模型的参数,gt=ΔJ(Wt)表示t次迭代代价函数关于W的梯度大小,E[g2]t表示前t次的梯度平方的均值。
α表示动力(通常设置为0.9),η0表示全局初始学习率。?是一个取值很小的数(一般为1e-8)为了避免分母为0
RMSProp借鉴了Adagrad的思想,观察表达式,分母为√E[g2]t+?。由于取了个加权平均,避免了学习率越来越低的的问题,而且能自适应地调节学习率。
RMSProp算法在经验上已经被证明是一种有效且实用的深度神经网络优化算法。目前它是深度学习从业者经常采用的优化方法之一
AdaDelta算法
思想:AdaGrad算法和RMSProp算法都需要指定全局学习率,AdaDelta算法结合两种算法每次参数的更新步长即
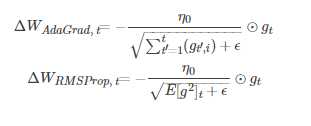
算法描述:
AdaDelta算法策略可以表示为:
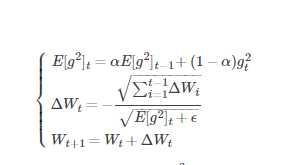
其中Wt为第t次迭代的模型参数,gt=ΔJ(Wt)为代价函数关于W的梯度。E[g2]t表示前t次的梯度平方的均值。∑t?1i=1ΔWi表示前t?1t?1次模型参数每次的更新步长累加求根。
从表达式可以看出,AdaDelta不需要设置一个默认的全局学习率。
评价:
在模型训练的初期和中期,AdaDelta表现很好,加速效果不错,训练速度快。
在模型训练的后期,模型会反复地在局部最小值附近抖动。
Adam算法
https://blog.csdn.net/shenxiaoming77/article/details/77169756
https://blog.csdn.net/weixin_40170902/article/details/80092628
以上是关于各种优化器Optimizer的总结与比较的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch自定义优化器Optimizer简单总结(附AdamW代码分析)
Pytorch自定义优化器Optimizer简单总结(附AdamW代码分析)