深度学习基础之优化器(optimizer)的介绍
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习基础之优化器(optimizer)的介绍相关的知识,希望对你有一定的参考价值。
文章目录
前言
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为最优化(optimization)。
遗憾的是,神经网络的最优化问题非常难。这是因为参数空间非常复杂,无法轻易找到最优解(无法使用那种通过解数学式一下子就求得最小值的方法)。而且,在深度神经网络中,参数的数量非常庞大,导致最优化问题更加复杂。
优化器的角色就是用来更新模型参数的方法,例如SGD、Adam等都能充当优化器的角色。
首先我们先看这么一个函数:

假设我们需要求解这个函数的最小值。
我们可以用代码先画出这个函数的图像:
import numpy as np
import matplotlib.pyplot as plt #绘图用的模块
from mpl_toolkits.mplot3d import Axes3D #绘制3D坐标的函数
#%matplotlib inline
def fun(x,y): ## 定义XYZ函数
return np.power(x,2) / 20 +np.power(y,2)
fig1=plt.figure() ## 展示图片的窗口
ax=Axes3D(fig1) ## 显示3D坐标
X=np.arange(-10,10,0.1) ## xy在底面
Y=np.arange(-10,10,0.1) #创建了从-2到2,步长为0.1的arange对象
X,Y=np.meshgrid(X,Y)
Z=fun(X,Y)
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=plt.cm.coolwarm)#用取样点(x,y,z)去构建曲面
ax.contourf(X,Y,Z, zdir='z',offset=-2, cmap=plt.cm.coolwarm)## 等高线图,zdir沿着哪个轴压缩
ax.set_xlabel('x label', color='r')
ax.set_ylabel('y label', color='g')
ax.set_zlabel('z label', color='b')
plt.title('fig6-1 left')
plt.show()
结果如下:
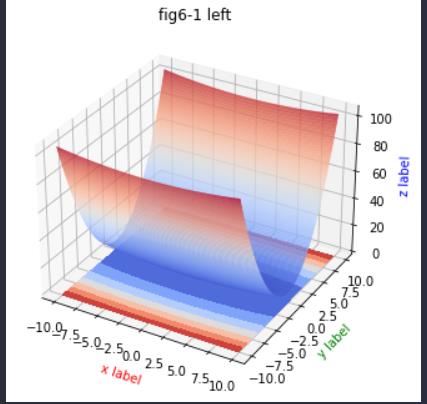
这是一个三维的图,可以观察到函数值z的最小值就是0。
我们可以尝试从上往下看,这样就能直观的反应梯度了。
# 在二维平面中画出他的等高线
# 计算x,y坐标对应的高度值
def f(x, y):
return np.power(x,2) / 20 + np.power(y,2)
# 生成x,y的数据
X = np.arange(-10, 10, 0.1) ## X的取值
Y = np.arange(-10, 10, 0.1) ## Y的取值
# 把x,y数据生成mesh网格状的数据,因为等高线的显示是在网格的基础上添加上高度值
X, Y = np.meshgrid(X, Y)
# 填充等高线
plt.contourf(X, Y, f(X, Y), cmap=plt.cm.coolwarm)
plt.xlabel('x')
plt.ylabel('y')
# 显示图表
plt.title('fig6-1 right')
plt.show()
输出:
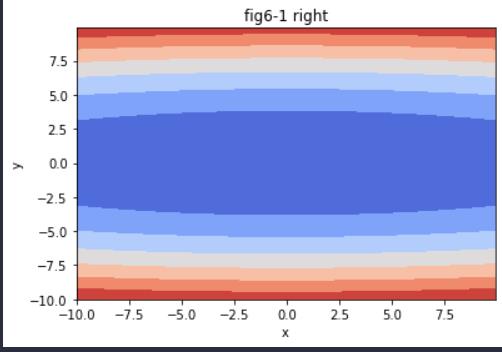
我们可以发现这个函数的特征是在y轴上的梯度变化大,在x轴上的梯度变化小。
下面将介绍一些优化器。
SGD(随机梯度下降法)
为了找到最优参数,我们将参数的梯度(导数)作为了线索。使用参数的梯度,沿梯度方向更新参数,并重复这个步骤多次,从而逐渐靠近最优参数,这个过程称为随机梯度下降法(stochastic gradient descent),简称SGD。
SGD是一个简单的方法,不过比起胡乱地搜索参数空间,也算是“聪明”的方法。但是,根据不同的问题,也存在比SGD更加聪明的方法。
SGD的数学公式如下:
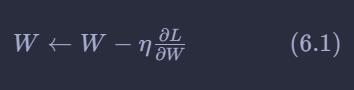
代码实现如下:
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
由于随机梯度下降法从当前梯度进行更新,我们可以画出各个点的负梯度。
#从pyplot导入MultipleLocator类,这个类用于设置刻度间隔
from matplotlib.pyplot import MultipleLocator
#画出负梯度特征图
X = np.arange(-10, 11, 1)
Y = np.arange(-10, 12, 2)
U, V = np.meshgrid(-X/10, -2*Y) ## x的偏导,y的偏导
Y1=np.zeros(X.shape[0])#21个0组成的一维数组
Y2=Y1+4
Y3=Y1-4
fig, ax = plt.subplots()
q = ax.quiver(X, Y, U, V)
#ax.quiverkey(q, X=0.3, Y=1.1, U=10,label='Quiver key, length = 10', labelpos='E')
#plt.plot(X, Y1,'b--')#把横线y=0画出来
#plt.plot(X, Y2,'b--')#把横线y=4画出来
#plt.plot(X, Y3,'b--')#把横线y=-4画出来
plt.xlabel('x')
plt.ylabel('y')
#把x轴的刻度间隔设置为2,并存在变量里
x_major_locator=MultipleLocator(2)
#把y轴的刻度间隔设置为2,并存在变量里
y_major_locator=MultipleLocator(2)
#ax为两条坐标轴的实例
ax=plt.gca()
#把x轴的主刻度设置为2的倍数
ax.xaxis.set_major_locator(x_major_locator)
#把y轴的主刻度设置为2的倍数
ax.yaxis.set_major_locator(y_major_locator)
plt.xlim(-10,10)
plt.ylim(-6,6)
plt.grid()
plt.title('fig6-2')
plt.show()
输出:
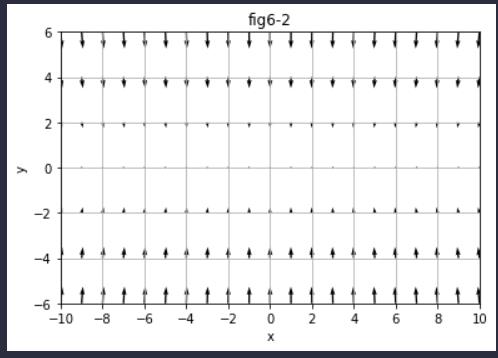
通过图可以发现,(0,0)是最小值的位置,但是很多点的梯度并没有指向(0,0),这说明SGD在面对函数的形状非均向的时候,效率并不高,因为下降的方向并不是最小的方向。
下面用代码实现SGD对此函数的最小值求解:
#假设我们按照SGD的思路,从(-7.0, 2.0)起,步长为0.9,前进
X_SGD = [-7.0]#保存点的横坐标坐标
Y_SGD = [2.0]#保存点的纵坐标坐标
x = - 7.0
y = 2.0
N = 40
lr = 0.95
for i in range (N):
x -= x/10*lr#更新x的值
y -= 2*y*lr#更新y的值
X_SGD.append(x)
Y_SGD.append(y)
#我们在等高线的基础上,画出点的移动
def f(x, y):
return np.power(x,2) / 20 + np.power(y,2)
X = np.arange(-10, 10, 0.01)
Y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(X, Y)
plt.plot(X_SGD, Y_SGD, color='red', marker='o', linestyle='solid')#把每一步梯度下降的点用折线连接起来画出
plt.contourf(X, Y, f(X, Y), cmap=plt.cm.coolwarm)
plt.xlabel('x')
plt.ylabel('y')
plt.xlim(-10, 10)
plt.ylim(-10, 10)
plt.title('fig6-3')
plt.show()
输出结果:

SGD呈“之”字形向使函数取得最小值的(0,0)处移动。SGD低效的根本原因是,梯度的方向并没有指向最小值的方向。
为了改正SGD的缺点,我们将继续介绍其他的一些方法。
Momentum
Momentum是“动量”的意思,和物理有关。用数学式表示Momentum方法,如下所示:


因为初始速度为0,所以第一次更新时其实和SGD是一样的,当第二次更新时,Momentum也便发挥作用,因为第一次更新留下一个“速度”,会影响第二次更新的幅度。
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v =
for key, val in params.items():
self.v[key] = np.zeros_like(val)#存放权重、偏置的数组,数组的形状和对应的权重、偏置形状一致,数组元素值都为0
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
用这个方法求解一下函数的最小值:
#假设我们按照momentum的思路,从(-7.0, 2.0)起,前进
X_momentum = [-7.0]#保存点的横坐标坐标
Y_momentum = [2.0]#保存点的纵坐标坐标
x = - 7.0
y = 2.0
N = 40
lr = 0.1
momentum=0.9
vx=0 # 初始速度为0
vy=0
for i in range (N):#对x和y分别更新值
vx=momentum*vx-x/10*lr
x += vx
vy=momentum*vy-2*y*lr
y += vy
X_momentum.append(x)
Y_momentum.append(y)
#我们在等高线的基础上,画出点的移动
def f(x, y):
return np.power(x,2) / 20 + np.power(y,2)
X = np.arange(-10, 10, 0.01)
Y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(X, Y)
plt.plot(X_momentum, Y_momentum, color='red', marker='o', linestyle='solid')#把每一步梯度下降的点用折线连接起来画出
plt.contourf(X, Y, f(X, Y), cmap=plt.cm.coolwarm)
plt.xlabel('x')
plt.ylabel('y')
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.title('fig6-5')
plt.show()
输出结果:
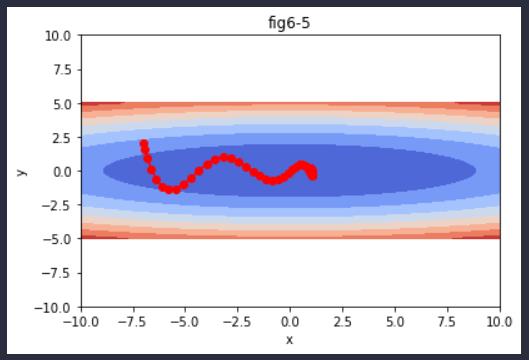
图6-5中,更新路径就像小球在碗中滚动一样。和SGD相比,我们发现“之”字形的“程度”减轻了。这是因为虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以y轴方向上的速度不稳定。因此,和SGD时的情形相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。
AdaGrad
在神经网络的学习中,学习率(数学式中记为η)的值很重要。学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能正确进行。
在关于学习率的有效技巧中,有一种被称为学习率衰减(learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多”学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。
逐渐减小学习率的想法,相当于将“全体”参数的学习率值一起降低。而AdaGrad 进一步发展了这个想法,针对“一个一个”的参数,赋予其“定制”的值。
AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习(AdaGrad的Ada来自英文单词Adaptive,即“适当的”的意思)。下面,让我们用数学式表示AdaGrad的更新方法。
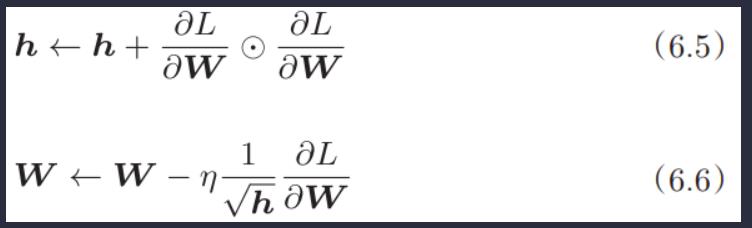

首先我们先实现一下AdaGrad:
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h =
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
这里需要注意的是,最后一行加上了微小值1e-7。这是为了防止当self.h[key]中有0时,将0用作除数的情况。在很多深度学习的框架中,这个微小值也可以设定为参数,但这里我们用的是1e-7这个固定值。现在,让我们试着使用AdaGrad解决函数的最优化问题。
#假设我们按照AdaGrad的思路,从(-7.0, 2.0)起,前进
X_AdaGrad = [-7.0]#保存点的横坐标坐标
Y_AdaGrad = [2.0]#保存点的纵坐标坐标
x = - 7.0
y = 2.0
N = 40
lr = 1.5
hx=0
hy=0
for i in range (N):
hx+=x/10*x/10#保存了以前的所有梯度值x/10的平方和
x-=x/10*lr/ (np.sqrt(hx) + 1e-7)
hy+=2*y*2*y##保存了以前的所有梯度值2*y的平方和
y-=2*y*lr/(np.sqrt(hy) + 1e-7)
X_AdaGrad.append(x)
Y_AdaGrad.append(y)
#我们在等高线的基础上,画出点的移动
def f(x, y):
return np.power(x,2) / 20 + np.power(y,2)
X = np.arange(-10, 10, 0.01)
Y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(X, Y)
plt.plot(X_AdaGrad, Y_AdaGrad, color='red', marker='o', linestyle='solid')#把每一步梯度下降的点用折线连接起来画出
plt.contourf(X, Y, f(X, Y), cmap=plt.cm.coolwarm)
plt.xlabel('x')
plt.ylabel('y')
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.title('fig6-6')
plt.show()
输出如下:
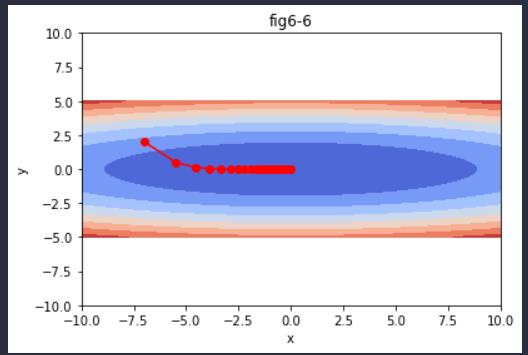 由图6-6由此可知,函数的取值高效地向着最小值移动。由于y轴方向上的梯度较大,因此刚开始变动较大,但是后面会根据这个较大的变动按比例进行调整,减小更新的步伐。因此,y轴方向上的更新程度被减弱,“之”字形的变动程度有所衰减。
由图6-6由此可知,函数的取值高效地向着最小值移动。由于y轴方向上的梯度较大,因此刚开始变动较大,但是后面会根据这个较大的变动按比例进行调整,减小更新的步伐。因此,y轴方向上的更新程度被减弱,“之”字形的变动程度有所衰减。
RMSprop
AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。实际上,如果无止境地学习,更新量就会变为 0,完全不再更新。为了改善这个问题,可以使用 RMSProp方法。RMSProp方法并不是将过去所有的梯度一视同仁地相加,而是逐渐地遗忘过去的梯度,在做加法运算时将新梯度的信息更多地反映出来。这种操作从专业上讲,称为“指数移动平均”,呈指数函数式地减小过去的梯度的尺度。
更新公式如下:

类实现:
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h =
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
对上述函数最优化求解:
#假设我们按照RMSprop的思路,从(-7.0, 2.0)起,步长为0.9,前进
X_RMSprop = [-7.0]#保存点的横坐标坐标
Y_RMSprop = [2.0]#保存点的纵坐标坐标
x = - 7.0
y = 2.0
N = 40
lr = 0.1
decay_rate = 0.99
hx=0
hy=0
for i in range (N):
hx*=decay_rate
hx+=(1 - decay_rate)*x/10*x/10#保存了以前的所有梯度值x/10的平方和的衰减值
#print(hx)
x-=lr * x/10 / (np.sqrt(hx) + 1e-7)
hy*=decay_rate
hy+=(1 - decay_rate)*2*y*2*y##保存了以前的所有梯度值2*y的平方和的衰减值
y-=2*y*lr/(np.sqrt(hy) + 1e-7)
X_RMSprop.append(x)
Y_RMSprop.append(y)
#我们在等高线的基础上,画出点的移动
def f(x, y):
return np.power(x,2) / 20 + np.power(y,2)
X = np.arange(-10, 10, 0.01)
Y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(X, Y)
plt.plot(X_RMSprop, Y_RMSprop, color='red', marker='o', linestyle='solid')#把每一步梯度下降的点用折线连接起来画出
plt.contourf(X, Y, f(X, Y