ansible基础-安装与配置
Posted mauricewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ansible基础-安装与配置相关的知识,希望对你有一定的参考价值。
一 安装
1.1 ansible架构
ansible是一个非常简单的自动化部署项目,由python编写并且开源。用于提供自动化云配置、配置文件管理、应用部署、服务编排和很多其他的IT自动化需求。
ansible实现的自动化部署是多层次的,通过描述系统之间的逻辑关系来构建业务所需要的基础架构模型,而不仅仅用于管理一个单独的系统;也就是说ansible不仅仅能部署一个或多个独立的服务,它还能对这些服务做关联、对部署顺序做编排等,一个完美的ansible部署项目应该是层次分明、顺序有秩的。
另外,ansible是Serverless和Agentless项目,在部署工具准备阶段基本上是零成本,而且ansible使用YAML写playbooks,这使playbook看起来通俗易懂,一目了然。
ansible这个后起之秀在开源社区上也是非常火爆的,可以说是部署工具届的网红一枚。现在很多很火的开源项目都在使用ansible作为部署工具,例如我熟悉的openstack-ansible、openshift-ansible等等
架构图:
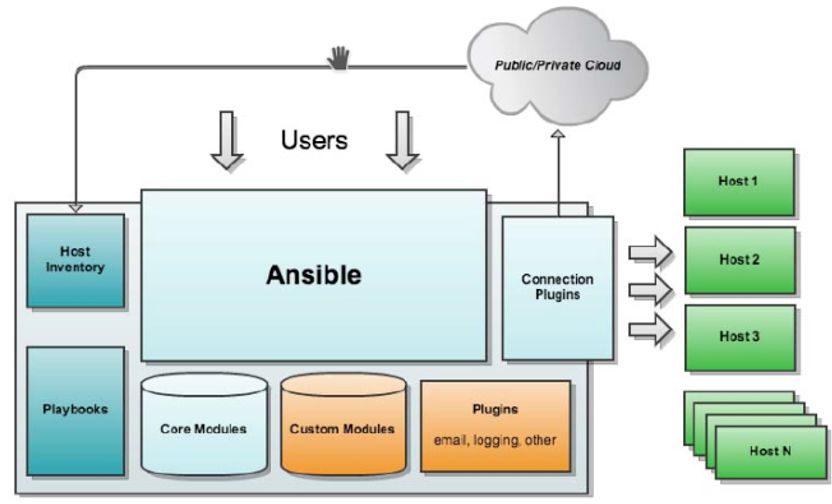
通过架构图我们可以看到ansible主要由以下部分组成:
Core Modules
核心模块,每个模块可以看成是一个小程序,用于实现具体的部署动作,也能指定被纳管服务的期望状态。
Custom Modules
自定义模块,与核心模块相似,不同之处在于人家是官方的,自己是民间(自定义)的。
Plugins
是为了增强ansible核心功能的代码片段,可以将其看作为一个函数,作用范围小,很实用。
Inventory
一个文件(INI类型)或者目录,主要作用是配置被纳管的主机和主机组,如果是目录也可以放置组变量group_vars和主机变量host_vars
Playbooks
用于存放play,每个play可以对指定的主机或主机组进行批量的部署动作,上面说到的服务的部署、关联、编排就是在playbook内实现的。
Connection Plugins
控制节点与被纳管节点的通讯插件,linux系统默认使用SSH进行通讯。
1.2 节点安装
被管理节点安装
依赖于python环境,python版本应该满足2.6或2.7或>=3.5与控制节点的通讯服务,通常是sshd服务
控制节点安装
python环境需求同被管理节点一致,windows不能作为控制节点
支持的操作系统包括但不限于Red Hat, Debian, CentOS, OS X, BSDs
安装方式根据操作系统的不同而定,比较简单,以centos为例,配置好yum源后可以通过命令yum install ansible -y进行安装。其他类型操作系统不一一列举了,可以参考官方文档https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html
二 配置文件
2.1 配置文件位置
ansible配置文件可以存放在不同地方,按优先级由高到低排序:
- 命令行-c 或 --config指定的配置文件路径
- 环境变量ANSIBLE_CONFIG
- 执行playbook所在目录下的ansible.cnf
- 当前执行用户家目录下.ansible.cnf(即~/.ansible.cnf)
- 默认配置文件存放路径/etc/ansible/ansible.cnf
当我们执行playbook时,ansible会按照上面列表的路径依次查找,如果高优先级的文件被找到则会被使用。
查看当前正在使用的配置文件路径:
? lab-ansible ansible --version
ansible 2.5.2
config file = /Users/weim/DevOps/lab-ansible/ansible.cfg
configured module search path = [u‘/Users/weim/.ansible/plugins/modules‘, u‘/usr/share/ansible/plugins/modules‘]
ansible python module location = /usr/local/Cellar/ansible/2.5.2/libexec/lib/python2.7/site-packages/ansible
executable location = /usr/local/bin/ansible
python version = 2.7.14 (default, Apr 27 2018, 19:33:14) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.37)]
2.2 配置文件参数
因配置文件参数太多,下面只列举一些比较常用的参数;表格中defaults/inventory代表[defaults]章节下的inventory参数,其他依此类推
| 参数 | 含义 |
| defaults/inventory | inventory文件(夹)路径,默认值/etc/ansible/hosts |
| defaults/roles_path | roles文件路径,默认值/etc/ansible/roles |
| defaults/remote_user | 指定连接被管理主机的用户,默认值root |
| defaults/forks | 同一时间操作目的主机的数量,默认值5 |
| defaluts/remote_port | 目的主机远程连接的端口,默认值22 |
| defaults/timeout | 连接目的主机的超时时间,默认值10 |
| ?privilege_escalation/become | 是否允许当前执行用户提升权限,默认值True |
| privilege_escalation/become_method | 提权使用的方法,默认值sudo |
| privilege_escalation/become_user | 当defaults/remote_user不是root用户时,该用户提权后所变成的用户,默认值root |
| privilege_escalation/become_ask_pass | 提权时是否要交互式输入密码,默认值False |
三 inventory
3.1 主机与主机组
主机和主机组
我们可以将inventory定义为一个INI文件或YAML类型的文件,文件里面可以定义主机和主机组,以INI类型文件为例:
node1
node2
[first_group]
node1
[second_group]
node2
[nodes]
node1
node2
node[3:10]
node[a:f]
上面的示例可以看出:
- 节点可以单独定义,不从属于任何组
- 连续数字或字母的主机可以使用[]扩起来表示
- 同一个主机是可以从属不同主机组的
默认主机组
ansible默认有两个主机组:all和ungrouped,all组包含所有主机,ungrouped包含的主机只属于all组且不属于其他任何一组。自定义组、all组、ungrouped组关系如图:
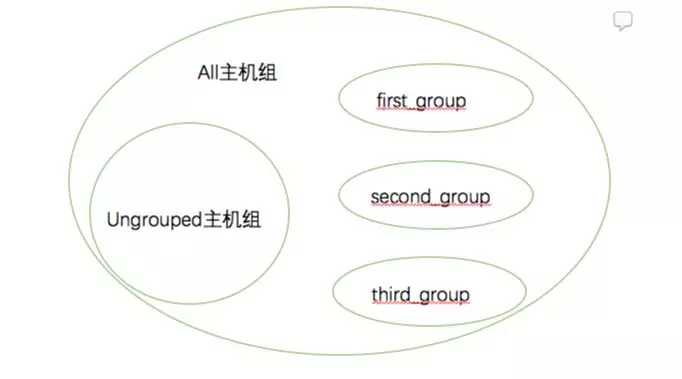
主机组的继承
主机组是可以继承的,写法如下:
[A_group]
node1
node2
[B_group:children]
A_group
上面示例中B组继承了A组,A组的变量定义在B组内同样可以使用。
关于主机组的继承要记住的知识点:
- all组是任何主机组的父主机组
- 主机组继承,对应的主机变量和组变量也会继承,如果变量冲突,子主机组的变量会覆盖父主机组的变量
变量
ansible能够定义变量的地方可以很多,所有的变量都可以归类为主机变量或组变量。
主机变量是针对某个主机的,例如:
[web]
web1 http_port = 8080 maxRequestsPerChild = 404
web2 http_port = 80 maxRequestsPerChild = 404
组变量是针对某个主机组的,例如:
[db]
db1
db2
[db:vars]
db_port = 3306
bind_ip = 127.0.0.1
变量的分离
生产上如果有大规模的服务器,那么将变量和主机定义写在一起就不太合适了,根据需求我们可以将变量写在单独的文件中。
主机变量可以放在inventory/host_vars目录,组变量可以放在inventory/group_vars目录,ansible会通过主机名与host_vars目录下的文件名称来识别哪个文件存放的是该主机的变量;同理,主机组也是通过组名和文件名称来对应关系。
可能有点蒙圈,看个例子就懂了:
inventory目录结构:
.
├── group_vars
│ ├── all.yml
│ ├── db.yml
│ └── web.yml
├── host_vars
│ ├── web1.yml
│ └── web2.yml
└── hosts
hosts文件内容如下:
[web]
web1
web2
[db]
db1
db2
上述示例中,我们可以看到:
group_vars下的web.yml和db.yml分别对应hosts文件中定义的web和db组,因为all组是默认所有组的父组,所以all.yml也是web组和db组的变量定义文件,如果与db.yml和web.yml变量定义有冲突,db和web有效。
同理,host_vars下的web1.yml 和 web2.yml 分别是web1和web2主机的变量定义,如果与group_vars下的web.yml变量有冲突,host_vars目录下的变量定义有效。
变量的优先级
在inventory文件内,如果变量定义冲突,那么优先级是这样的:
- 对于主机组,子组的变量会覆盖父组的变量
- 对于主机,主机变量会覆盖组变量
3.2 动态inventory
在3.1章节中我们介绍和使用的都是静态inventory,ansible也可以使用动态incentory,那么动态inventory是什么呢?
动态inventory是指可以从一个公共仓库pull下来,简单配置一些参数后就能直接使用的inventory。因为动态inventory是对某一项目的通用模版,所以这种类型的inventory通常在大型的开源项目比较常用。例如:AWS EC2, Cobbler, OpenStack等等。
动态inventory pull下来后是一个python脚本,可以通过添加执行权限后./xxx.py --list查看都包含哪些主机。
关于动态inventory,这里不在扩展。如果有机会,在后续的ansible进阶章节在着重介绍。
四 Ad Hoc 命令
在ansible基础-理解篇中,笔者已经阐述过,ansible相对于puppet有一个优势,就是CLI更加丰富,除了让ansible执行写好的playbook外,我们也可以使用ansible命令对指定的主机或主机组执行批量的动作,这里要注意一下,ansible命令可以使用Core Modules,但是inventory里定义的主机变量和组变量不能生效。
命令帮助如下:
? inventory ansible --help
Usage: ansible <host-pattern> [options]
如果不用-m指定模块,ansible命令默认使用command模块。
示例1: 查看nodes主机组的主机名
? lab-ansible ansible nodes -a ‘hostname‘
node2 | SUCCESS | rc=0 >>
node2
node1 | SUCCESS | rc=0 >>
node1
ansible命令也可以指定很多附加参数,例如指定remote_user(- u)、forks数量(- f)、提权(-b)、提权是否要输入密码(--ask-become-pass)等等,其他参数请使用ansible --help命令查看。
示例2: 使用copy模块将本地test.txt文件拷贝到目的主机/etc/test.txt,设定使用student用户登陆,并且要求提权,提权方式为sudo,要求交互式输入提权密码。
? lab-ansible ansible nodes -m copy -a ‘src=./test.txt dest=/etc/test.txt‘ --user=student --become --become-user=root --become-method=sudo --ask-sudo-pass
命令行传入的参数优先级是最高的,包括连接参数和变量,关于变量优先级,在后续的“ansible基础-变量”会详细阐述。
五 本节应该掌握的技能
- 使用ansible前控制节点和被纳管节点环境需求,会安装部署ansible
- 配置文件可以存在的位置和常用的配置文件参数的含义
- 会写inventory,掌握inventory目录结构和各文件作用
- 简单了解动态inventory的概念
- 会使用ansible命令对目的主机批量处理
- 会使用常用的Core Module
六 参考链接
- https://docs.ansible.com/ansible/2.5/dev_guide/overview_architecture.html
- https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html
- https://docs.ansible.com/ansible/latest/user_guide/intro_inventory.html
- https://docs.ansible.com/ansible/latest/user_guide/intro_dynamic_inventory.html#intro-dynamic-inventory
欢迎大家关注我的公众号:

以上是关于ansible基础-安装与配置的主要内容,如果未能解决你的问题,请参考以下文章