深度优先搜索和广度优先搜索的深入讨论
(一)深度优先搜索的特点是:
(1)无论问题的内容和性质以及求解要求如何不同,它们的程序结构都是相同的,即都是深度优先算法(一)和深度优先算法(二)中描述的算法结构,不相同的仅仅是存储结点数据结构和产生规则以及输出要求。
(2)深度优先搜索法有递归以及非递归两种设计方法。一般的,当搜索深度较小、问题递归方式比较明显时,用递归方法设计好,它可以使得程序结构更简捷易懂。当搜索深度较大时,当数据量较大时,由于系统堆栈容量的限制,递归容易产生溢出,用非递归方法设计比较好。
(3)深度优先搜索方法有广义和狭义两种理解。广义的理解是,只要最新产生的结点(即深度最大的结点)先进行扩展的方法,就称为深度优先搜索方法。在这种理解情况下,深度优先搜索算法有全部保留和不全部保留产生的结点的两种情况。而狭义的理解是,仅仅只保留全部产生结点的算法。本书取前一种广义的理解。不保留全部结点的算法属于一般的回溯算法范畴。保留全部结点的算法,实际上是在数据库中产生一个结点之间的搜索树,因此也属于图搜索算法的范畴。
(4)不保留全部结点的深度优先搜索法,由于把扩展望的结点从数据库中弹出删除,这样,一般在数据库中存储的结点数就是深度值,因此它占用的空间较少,所以,当搜索树的结点较多,用其他方法易产生内存溢出时,深度优先搜索不失为一种有效的算法。
(5)从输出结果可看出,深度优先搜索找到的第一个解并不一定是最优解。
如果要求出最优解的话,一种方法将是后面要介绍的动态规划法,另一种方法是修改原算法:把原输出过程的地方改为记录过程,即记录达到当前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优的,等全部搜索完成后,才把保留的最优解输出。
二、广度优先搜索法的显著特点是:
(1)在产生新的子结点时,深度越小的结点越先得到扩展,即先产生它的子结点。为使算法便于实现,存放结点的数据库一般用队列的结构。
(2)无论问题性质如何不同,利用广度优先搜索法解题的基本算法是相同的,但数据库中每一结点内容,产生式规则,根据不同的问题,有不同的内容和结构,就是同一问题也可以有不同的表示方法。
(3)当结点到跟结点的费用(有的书称为耗散值)和结点的深度成正比时,特别是当每一结点到根结点的费用等于深度时,用广度优先法得到的解是最优解,但如果不成正比,则得到的解不一定是最优解。这一类问题要求出最优解,一种方法是使用后面要介绍的其他方法求解,另外一种方法是改进前面深度(或广度)优先搜索算法:找到一个目标后,不是立即退出,而是记录下目标结点的路径和费用,如果有多个目标结点,就加以比较,留下较优的结点。把所有可能的路径都搜索完后,才输出记录的最优路径。
(4)广度优先搜索算法,一般需要存储产生的所有结点,占的存储空间要比深度优先大得多,因此程序设计中,必须考虑溢出和节省内存空间得问题。
(5)比较深度优先和广度优先两种搜索法,广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索算法法要快些。
总之,一般情况下,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快,在距离和深度成正比的情况下能较快地求出最优解。因此在选择用哪种算法时,要综合考虑。决定取舍。
三、基本搜索算法比较和搜索算法的优化
搜索算法是利用计算机的高性能来有目的的穷举一个问题的部分或所有的可能情况,从而求出问题的解的一种方法。搜索过程实际上是根据初始条件和扩展规则构造一棵解答树并寻找符合目标状态的节点的过程。所有的搜索算法从其最终的算法实现上来看,都可以划分成两个部分──控制结构和产生系统,而所有的算法的优化和改进主要都是通过修改其控制结构来完成的。现在主要对其控制结构进行讨论,因此对其产生系统作如下约定:
Function ExpendNode(Situation:Tsituation;ExpendWayNo:Integer):TSituation;
表示对给出的节点状态Sitution采用第ExpendWayNo种扩展规则进行扩展,并且返回扩展后的状态。
(本文所采用的算法描述语言为类Pascal。)
第一部分 基本搜索算法
一、回溯算法
回溯算法是所有搜索算法中最为基本的一种算法,其采用了一种“走不通就掉头”思想作为其控制结构,其相当于采用了先根遍历的方法来构造解答树,可用于找解或所有解以及最优解。具体的算法描述如下:(略)
范例:一个M*M的棋盘上某一点上有一个马,要求寻找一条从这一点出发不重复的跳完棋盘上所有的点的路线。
评价:回溯算法对空间的消耗较少,当其与分枝定界法一起使用时,对于所求解在解答树中层次较深的问题有较好的效果。但应避免在后继节点可能与前继节点相同的问题中使用,以免产生循环。
二、深度搜索与广度搜索
深度搜索与广度搜索的控制结构和产生系统很相似,唯一的区别在于对扩展节点选取上。由于其保留了所有的前继节点,所以在产生后继节点时可以去掉一部分重复的节点,从而提高了搜索效率。这两种算法每次都扩展一个节点的所有子节点,而不同的是,深度搜索下一次扩展的是本次扩展出来的子节点中的一个,而广度搜索扩展的则是本次扩展的节点的兄弟节点。在具体实现上为了提高效率,所以采用了不同的数据结构.
三、初探队与广度优先搜索:
1、队的定义:
队是特殊的线性表之一,它只允许在队的一端插入,在队的另一端删除。插入一端叫队尾(T),删除一端叫队首(H),没有任何元素的队叫做空队。队列遵循"先进先出"原则,排队购物、买票等,就是最常见的队。
2、队的基本操作:
(1)队的描述:
type queue=array[1..100] of integer;
var a:queue; {定义数组}
h,d:integer; {队首、队尾指针}
(2) 初始化(图1):
procedure start;
begin
h:=1; d:=1;
end;
(3) 入队操作(图2):
procedure enter;
begin
read(s); {读入数据}
inc(d); {队尾加一}
a[d]:=s;
end;
(4) 出队操作(图3):
procedure out;
begin
inc(h); {队首加一}
a[h]:=0;
end;
广度优先搜索类似于树的按层次遍历的过程。它和队有很多相似之处,运用了队的许多思想,其实就是对队的深入一步研究,它的基本操作和队列几乎一样。
第二部分 搜索算法的优化
一、双向广度搜索
广度搜索虽然可以得到最优解,但是其空间消耗增长太快。但如果从正反两个方向进行广度搜索,理想情况下可以减少二分之一的搜索量,从而提高搜索速度。
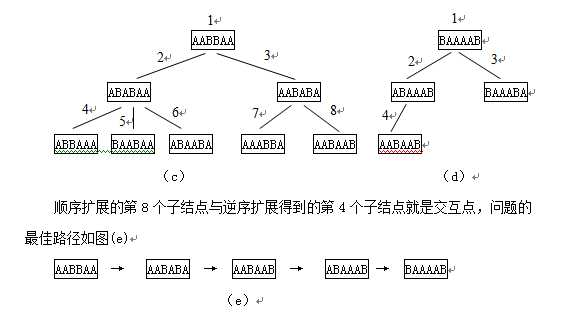
范例:移动一个只含字母A和B的字符串中的字母,给定初始状态为(a)表,目标状态为(b)表,给定移动规则为:只能互相对换相邻字母。请找出一条移动最少步数的办法。
AABBAA BAAAAB
(a) (b)
问题分析:从初始状态和目标状态均按照广度优先搜索扩展接点,当达到以下状态时,出现相交点,如图(c),接点序号表示生成顺序。
双向扩展结点:
利用双向搜索对广度搜索算法的改进:
1、添加一张节点表,作为反向扩展表。
2、在while循环体中在正向扩展代码后加入反向扩展代码,其扩展过程不能与正向过程共享一个for循环。
3、在正向扩展出一个节点后,需在反向表中查找是否有重合节点。反向扩展时与之相同。
对双向广度搜索算法的改进: 略微修改一下控制结构,每次while循环时只扩展正反两个方向中节点数目较少的一个,可以使两边的发展速度保持一定的平衡,从而减少总扩展节点的个数,加快搜索速度。
二、分支定界
分支定界实际上是A*算法的一种雏形,其对于每个扩展出来的节点给出一个预期值,如果这个预期值不如当前已经搜索出来的结果好的话,则将这个节点(包括其子节点)从解答树中删去,从而达到加快搜索速度的目的。
范例:在一个商店中购物,设第I种商品的价格为Ci。但商店提供一种折扣,即给出一组商品的组合,如果一次性购买了这一组商品,则可以享受较优惠的价格。现在给出一张购买清单和商店所提供的折扣清单,要求利用这些折扣,使所付款最少。
问题分析:显然,折扣使用的顺序与最终结果无关,所以可以先将所有的折扣按折扣率从大到小排序,然后采用回溯法的控制结构,对每个折扣从其最大可能使用次数向零递减搜索,设A为已打完折扣后优惠的价格,C为当前未打折扣的商品零售价之和,则其预期值为A+a*C,其中a为下一个折扣的折扣率。如当前已是最后一个折扣,则a=1。
对回溯算法的改进:
1、添加一个全局变量BestAnswer,记录当前最优解。
2、在每次生成一个节点时,计算其预期值,并与BestAnswer比较。如果不好,则调用回溯过程。
三、A*算法
A*算法中更一般的引入了一个估价函数f,其定义为f=g+h。其中g为到达当前节点的耗费,而h表示对从当前节点到达目标节点的耗费的估计。其必须满足两个条件:
1、h必须小于等于实际的从当前节点到达目标节点的最小耗费h*。
2、f必须保持单调递增。
A*算法的控制结构与广度搜索的十分类似,只是每次扩展的都是当前待扩展节点中f值最小的一个,如果扩展出来的节点与已扩展的节点重复,则删去这个节点。如果与待扩展节点重复,如果这个节点的估价函数值较小,则用其代替原待扩展节点,具体算法描述如下:
范例:一个3*3的棋盘中有1-8八个数字和一个空格,现给出一个初始态和一个目标态,要求利用这个空格,用最少的步数,使其到达目标态。
问题分析:预期值定义为h=|x-dx|+|y-dy|。
估价函数定义为f=g+h。
<Type>
Node(节点类型)=Record
Situtation:TSituation(当前节点状态);
g:Integer;(到达当前状态的耗费)
h:Integer;(预计的耗费)
f:Real;(估价函数值)
Last:Integer;(父节点)
End
<Var>
List(节点表):Array[1..Max(最多节点数)] of Node(节点类型);
open(总节点数):Integer;
close(待扩展节点编号):Integer;
New-S:Tsituation;(新节点)
<Init>
List<-0;
open<-1;
close<-0;
List[1].Situation<- 初始状态;
<Main Program>
While (close<open(还有未扩展节点)) and
(open<Max(空间未用完)) and
(未找到目标节点) do
Begin
Begin
close:=close+1;
For I:=close+1 to open do (寻找估价函数值最小的节点)
Begin
if List[i].f<List[close].f then
Begin
交换List[i]和List[close];
End-If;
End-For;
End;
For I:=1 to TotalExpendMethod do(扩展一层子节点)
Begin
New-S:=ExpendNode(List[close].Situation,I)
If Not (New-S in List[1..close]) then
(扩展出的节点未与已扩展的节点重复)
Begin
If Not (New-S in List[close+1..open]) then
(扩展出的节点未与待扩展的节点重复)
Begin
open:=open+1;
List[open].Situation:=New-S;
List[open].Last:=close;
List[open].g:=List[close].g+cost;
List[open].h:=GetH(List[open].Situation);
List[open].f:=List[open].h+List[open].g;
End-If
Else Begin
If List[close].g+cost+GetH(New-S)<List[same].f then
(扩展出来的节点的估价函数值小于与其相同的节点)
Begin
List[same].Situation:= New-S;
List[same].Last:=close;
List[same].g:=List[close].g+cost;
List[same].h:=GetH(List[open].Situation);
List[same].f:=List[open].h+List[open].g;
End-If;
End-Else;
End-If
End-For;
End-While;
对A*算法的改进--分阶段A*:
当A*算法出现数据溢出时,从待扩展节点中取出若干个估价函数值较小的节点,然后放弃其余的待扩展节点,从而可以使搜索进一步的进行下去。