一、mapTask并行度的决定机制
1.概述
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:
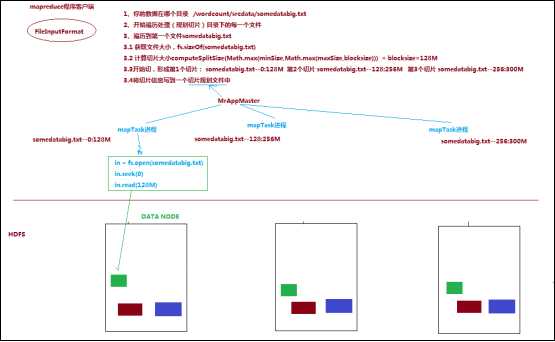
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split,然后每一个split分配一个mapTask并行实例处理
这段逻辑及形成的切片规划描述文件,由FileInputFormat实现类的getSplits()方法完成,其过程如下图:
// 完整的笔记介绍,参考:http://blog.csdn.net/qq_26442553/article/details/78774061
2.FileInputFormat切片机制
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于block大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
相关的切片机制,可以参考相关博文:http://blog.csdn.net/m0_37746890/article/details/78834603