阿里如何做到百万量级硬件故障自愈?
Posted zhaowei121
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里如何做到百万量级硬件故障自愈?相关的知识,希望对你有一定的参考价值。
随着阿里大数据产品业务的增长,服务器数量不断增多,IT运维压力也成比例增大。各种软、硬件故障而造成的业务中断,成为稳定性影响的重要因素之一。本文详细解读阿里如何实现硬件故障预测、服务器自动下线、服务自愈以及集群的自平衡重建,真正在影响业务之前实现硬件故障自动闭环策略,对于常见的硬件故障无需人工干预即可自动闭环解决。
1.背景
1.1.面临挑战
对于承载阿里巴巴集团95%数据存储及计算的离线计算平台MaxCompute,随着业务增长,服务器规模已达到数十万台,而离线作业的特性导致硬件故障不容易在软件层面被发现,同时集团统一的硬件报障阈值常常会遗漏一些对应用有影响的硬件故障,对于每一起漏报,都对集群的稳定性构成极大的挑战。
针对挑战,我们面对两个问题:硬件故障的及时发现与故障机的业务迁移。下面我们会围绕这两个问题进行分析,并详细介绍落地的自动化硬件自愈平台——DAM。在介绍之前我们先了解下飞天操作系统的应用管理体系——天基(Tianji)。
1.2.天基应用管理
MaxCompute是构建在阿里数据中心操作系统——飞天(Apsara)之上,飞天的所有应用均由天基管理。天基是一套自动化数据中心管理系统,管理数据中心中的硬件生命周期与各类静态资源(程序、配置、操作系统镜像、数据等)。而我们的硬件自愈体系正是与天基紧密结合,利用天基的Healing机制构建面向复杂业务的硬件故障发现、自愈维修闭环体系。
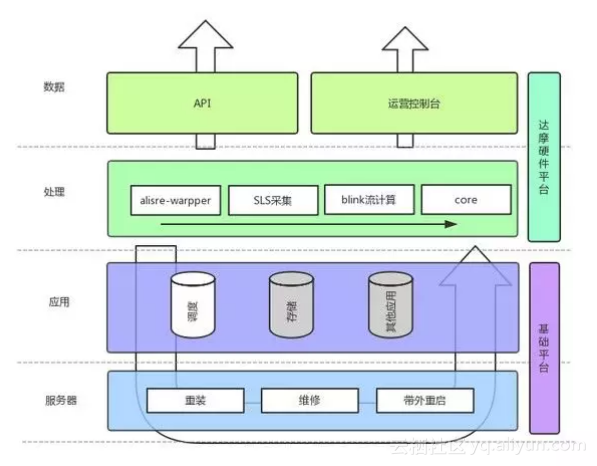
透过天基,我们可以将各种物理机的指令(重启、重装、维修)下发,天基会将其翻译给这台物理机上每个应用,由应用根据自身业务特性及自愈场景决策如何响应指令。
2.硬件故障发现
2.1.如何发现
我们所关注的硬件问题主要包含:硬盘、内存、CPU、网卡电源等,下面列举对于常见硬件问题发现的一些手段和主要工具:
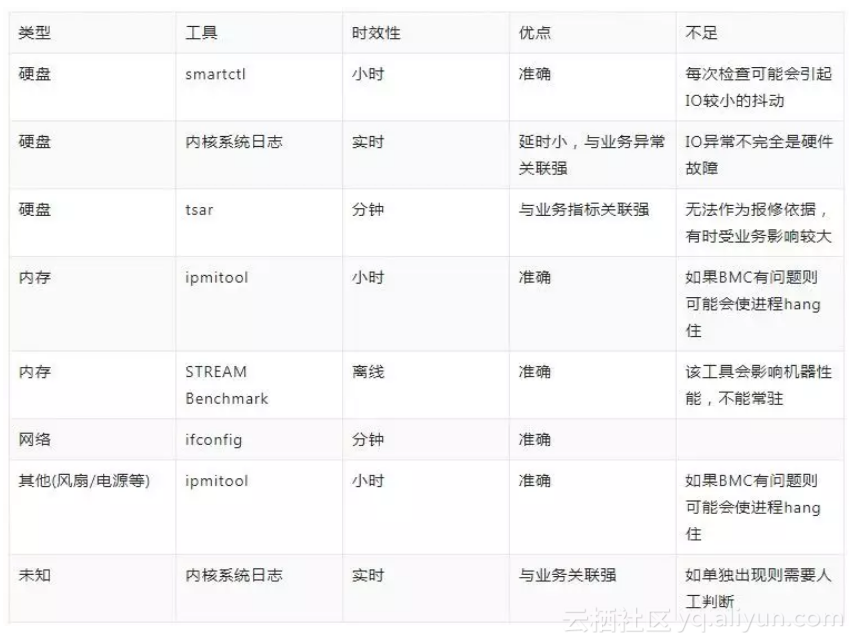
在所有硬件故障中,硬盘故障占比50%以上,下面分析一下最常见的一类故障:硬盘媒介故障。通常这个问题表象就是文件读写失败/卡住/慢。但读写问题却不一定是媒介故障产生,所以我们有必要说明一下媒介故障的在各层的表象。
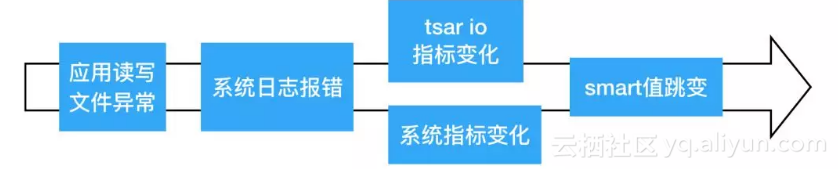
a. 系统日志报错是指在/var/log/messages中能够找到类似下面这样的报错
Sep 3 20:39:56 host1.a1 kernel: : [61959097.553029] Buffer I/O error on device sdi1, logical block 796203507b. tsar io指标变化是指rs/ws/await/svctm/util等这些指标的变化或突变,由于报错期间会引起读写的停顿,所以通常会体现在iostat上,继而被采集到tsar中。
● 在tsar io指标中,存在这样一条规则让我们区分硬盘工作是否正常 qps=ws+rs<100 & util>90,假如没有大规模的kernel问题,这种情况一般都是硬盘故障引起的。
c. 系统指标变化通常也由于io变化引起,比如D住引起load升高等。
d. smart值跳变具体是指197(Current_Pending_Sector)/5(Reallocated_Sector_Ct)的跳变。这两个值和读写异常的关系是:
● 媒介读写异常后,在smart上能观察到197(pending) +1,表明有一个扇区待确认。
● 随后在硬盘空闲的时候,他会对这个197(pending)中攒的各种待确认扇区做确认,如果读写通过了,则197(pending) -1,如果读写不通过则 197(pending)-1 且 5(reallocate)+1。
总结下来,在整条报错链路中,只观察一个阶段是不够的,需要多个阶段综合分析来证明硬件问题。由于我们可以严格证明媒介故障,我们也可以反向推导,当存在未知问题的时候能迅速地区分出是软件还是硬件问题。
上述的工具是结合运维经验和故障场景沉淀出来,同时我们也深知单纯的一个发现源是远远不够的,因此我们也引入了其他的硬件故障发现源,将多种检查手段结合到一起来最终确诊硬件故障。
2.2.如何收敛
上一章节提到的很多工具和路径用来发现硬件故障,但并不是每次发现都一定报故障,我们进行硬件问题收敛的时候,保持了下面几个原则:
● 指标尽可能与应用/业务无关:有些应用指标和硬件故障相关性大,但只上监控,不作为硬件问题的发现来源。 举一个例子,当io util大于90%的时候硬盘特别繁忙,但不代表硬盘就存在问题,可能只是存在读写热点。我们只认为io util>90且iops<30 超过10分钟的硬盘可能存在硬件问题。
● 采集敏感,收敛谨慎:对于可能的硬件故障特征都进行采集,但最终自动收敛分析的时候,大多数采集项只做参考,不作为报修依据。 还是上一个硬盘io util的例子,如果单纯出现io util>90且iops<30的情况,我们不会自动报修硬盘,因为kernel问题也可能会出现这个情况。只有当 smartctl超时/故障扇区 等明确故障项出现后,两者关联才确诊硬盘故障,否则只是隔离观察,不报修。
2.3.覆盖率
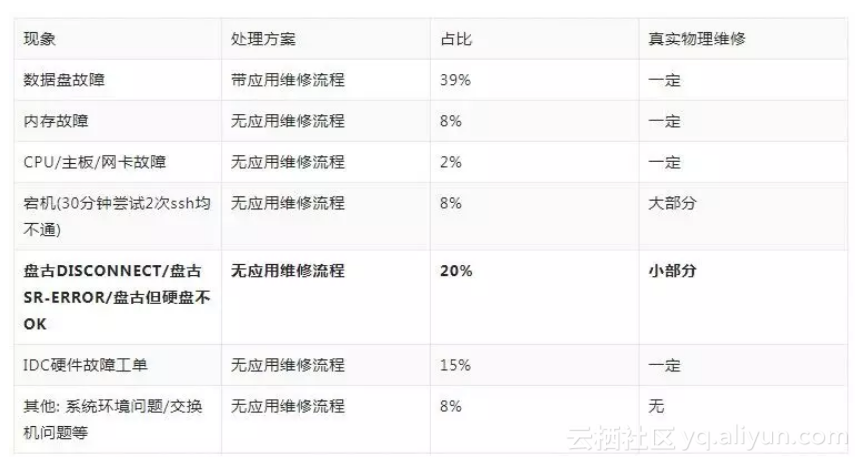
以某生产集群,在20xx年x月的IDC工单为例,硬件故障及工单统计如下:
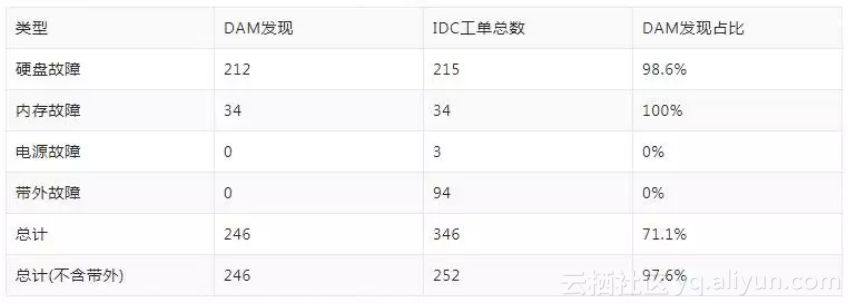
去除带外故障的问题,我们的硬件故障发现占比为97.6%。
3.硬件故障自愈
3.1 自愈流程
针对每台机器的硬件问题,我们会开一个自动轮转工单来跟进,当前存在两套自愈流程:【带应用维修流程】和【无应用维修流程】,前者针对的是可热拔插的硬盘故障,后者是针对余下所有的整机维修硬件故障。
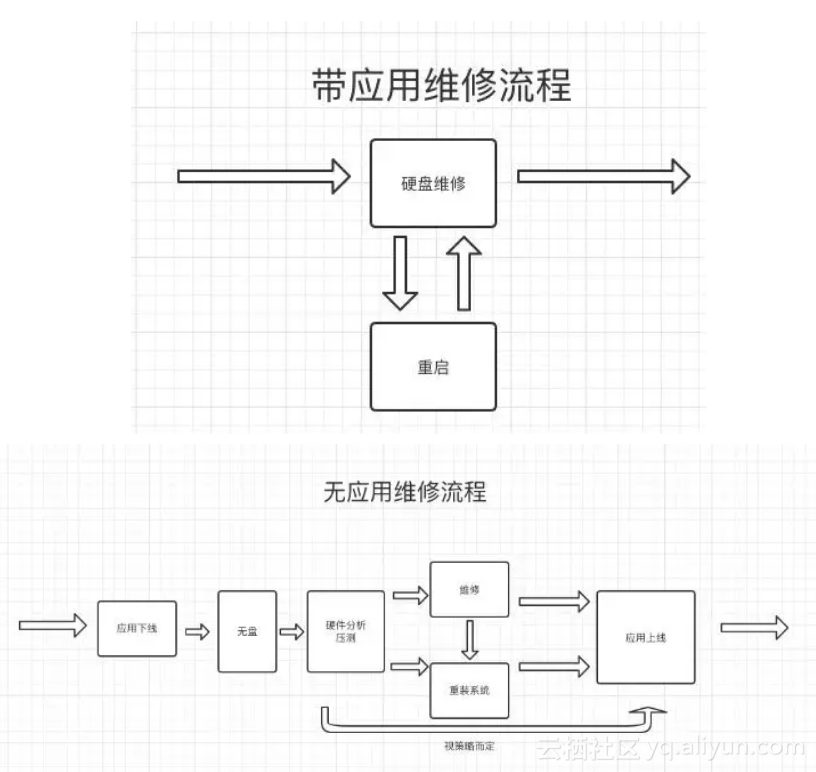
在我们的自动化流程中,有几个比较巧妙的设计:
a. 无盘诊断
● 对于宕机的机器而言,无法进无盘(ramos)才开【无故宕机】维修工单,这样能够大量地减少误报,减少服务台同学负担。
● 无盘中的压测可以完全消除当前版本的kernel或软件的影响,真实地判断出硬件是否存在性能问题。
b. 影响面判断/影响升级
● 对于带应用的维修,我们也会进行进程是否D住的判断。如果存在进程D住时间超过10分钟,我们认为这个硬盘故障的影响面已扩大到了整机,需要进行重启消除影响。
● 在重启的时候如果出现了无法启动的情况,也无需进行人工干预,直接进行影响升级,【带应用维修流程】直接升级成【无应用维修流程】。
c. 未知问题自动化兜底
● 在运行过程中,会出现一些机器宕机后可以进无盘,但压测也无法发现任何硬件问题,这个时候就只能让机器再进行一次装机,有小部分的机器确实在装机过程中,发现了硬件问题继而被修复了。
d. 宕机分析
● 整个流程巧妙的设计,使得我们在处理硬件故障的时候,同时具备了宕机分析的能力。
● 不过整机流程还以解决问题为主导向,宕机分析只是副产品。
● 同时,我们也自动引入了集团的宕机诊断结果进行分析,达到了1+1>2的效果。
3.2.流程统计分析
如果是同样的硬件问题反复触发自愈,那么在流程工单的统计,能够发现问题。例如联想RD640的虚拟串口问题,在还未定位出根因前,我们就通过统计发现了:同个机型的机器存在反复宕机自愈的情况,即使机器重装之后,问题也还是会出现。接下来我们就隔离了这批机器,保障集群稳定的同时,为调查争取时间。
3.3.业务关联误区
事实上,有了上面这套完整的自愈体系之后,某些业务上/kernel上/软件上需要处理的问题,也可以进入这个自愈体系,然后走未知问题这个分支。其实硬件自愈解决业务问题,有点饮鸩止渴,容易使越来越多还没想清楚的问题,尝试通过这种方式来解决兜底。
当前我们逐步地移除对于非硬件问题的处理,回归面向硬件自愈的场景(面向软件的通用自愈也有系统在承载,这类场景与业务的耦合性较大,无法面向集团通用化),这样也更利于软硬件问题分类和未知问题发现。
4.架构演进
4.1.云化
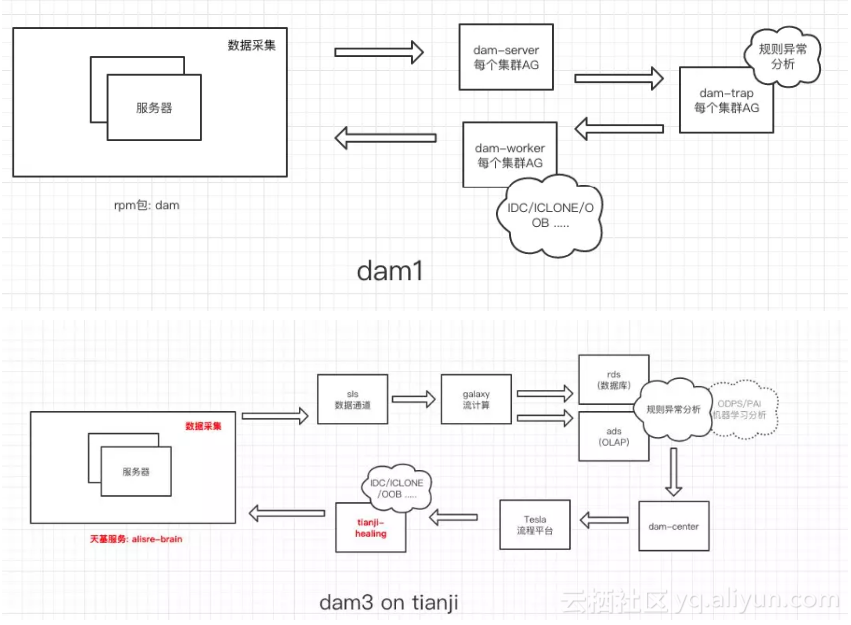
最初版本的自愈架构是在每个集群的控制机上实现,因为一开始时候运维同学也是在控制机上处理各种问题。但随着自动化地不断深入,发现这样的架构严重阻碍了数据的开放。于是我们采用中心化架构进行了一次重构,但中心化架构又会遇到海量数据的处理问题,单纯几个服务端根本处理不过来。
因此我们对系统进一步进行分布式服务化的重构,以支撑海量业务场景,将架构中的各个模块进行拆解,引入了 阿里云日志服务(sls)/阿里云流计算(blink)/阿里云分析数据库(ads) 三大神器,将各个采集分析任务由云产品分担,服务端只留最核心的硬件故障分析和决策功能。
下面是DAM1与DAM3的架构对比
4.2.数据化
随着自愈体系的不断深入,各阶段的数据也有了稳定的产出,针对这些数据的更高维分析,能让我们发现更多有价值且明确的信息。同时,我们也将高维的分析结果进行降维,采用健康分给每台机器打标。通过健康分,运维的同学可以快速知晓单台机器、某个机柜、某个集群的硬件情况。
4.3.服务化
基于对全链路数据的掌控,我们将整个故障自愈体系,作为一个硬件全生命周期标准化服务,提供给不同的产品线。基于对决策的充分抽象,自愈体系提供各类感知阈值,支持不同产品线的定制,形成适合个性化的全生命周期服务。
5.故障自愈闭环体系
在AIOps的感知、决策、执行闭环体系中,软件/硬件的故障自愈是最常见的应用场景,行业中大家也都选择故障自愈作为首个AIOps落地点。在我们看来,提供一套通用的故障自愈闭环体系是实现AIOps、乃至NoOps(无人值守运维)的基石,应对海量系统运维,智能自愈闭环体系尤为重要。
5.1.必要性
在一个复杂的分布式系统中,各种架构间不可避免地会出现运行上的冲突,而这些冲突的本质就在于信息不对称。而信息不对称的原因是,每种分布式软件架构在设计都是内敛闭环的。现在,通过各种机制各种运维工具,可以抹平这些冲突,然而这种方式就像是在打补丁,伴随着架构的不断升级,补丁似乎一直都打不完,而且越打越多。因此,我们有必要将这个行为抽象成自愈这样一个行为,在架构层面显式地声明这个行为,让各软件参与到自愈的整个流程中,将原本的冲突通过这种方式转化为协同。
当前我们围绕运维场景中最大的冲突点:硬件与软件冲突,进行架构和产品设计,通过自愈的方式提升复杂的分布式系统的整体鲁棒性。
5.2.普适性
透过大量机器的硬件自愈轮转,我们发现:
● 被纳入自愈体系的运维工具的副作用逐渐降低(由于大量地使用运维工具,运维工具中的操作逐渐趋于精细化)。
● 被纳入自愈体系的人工运维行为也逐渐变成了自动化。
● 每种运维动作都有了稳定的SLA承诺时间,不再是随时可能运行报错的运维脚本。
因此,自愈实际上是在复杂的分布式系统上,将运维自动化进行充分抽象后,再构筑一层闭环的架构,使得架构生态形成更大的协调统一。
阅读原文???????
更多技术干货 请关注阿里云云栖社区微信号 :yunqiinsight
以上是关于阿里如何做到百万量级硬件故障自愈?的主要内容,如果未能解决你的问题,请参考以下文章