HBase集群环境搭建
Posted zhangyongli2011
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase集群环境搭建相关的知识,希望对你有一定的参考价值。
本文档环境基于ubuntu14.04版本,如果最终不使用SuperMap iServer 9D ,可以不配置geomesa-hbase_2.11-2.0.1-bin.tar.gz
(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)
一、准备
1.1 软件版本
- hadoop-2.6.5
- zookeeper-3.4.10.tar.gz
- hbase-1.3.1-bin.tar.gz
- geomesa-hbase_2.11-2.0.1-bin.tar.gz
1.2 网络规划
本文规划搭建 3 台机器组成集群模式,IP 与计算机名分别为, 如果是单台搭建,只需填写一个即可
192.168.20.122 master
192.168.20.123 slave1
192.168.20.124 slave21.3 软件包拷贝
可将上述软件包拷贝到 3 台机器的 opt 目录下
- JDK 1.8.0
- Hadoop 2.6.5
- zookeeper-3.4.10.tar.gz
- hbase-1.3.1-bin.tar.gz
- geomesa-hbase_2.11-2.0.1-bin.tar.gz
1.4 SSH 设置
修改/etc/ssh/sshd_config 文件,将以下三项开启 yes 状态
PermitRootLogin yes
PermitEmptyPasswords yes
PasswordAuthentication yes重启 ssh 服务
service ssh restart这样 root 用户可直接登陆,以及为后续 ssh 无密码登录做准备。
1.5 绑定 IP 和修改计算机名
1.5.1 修改/etc/hosts,添加 IP 绑定注释 127.0.1.1 绑定(不注释会影响 hadoop 集群)
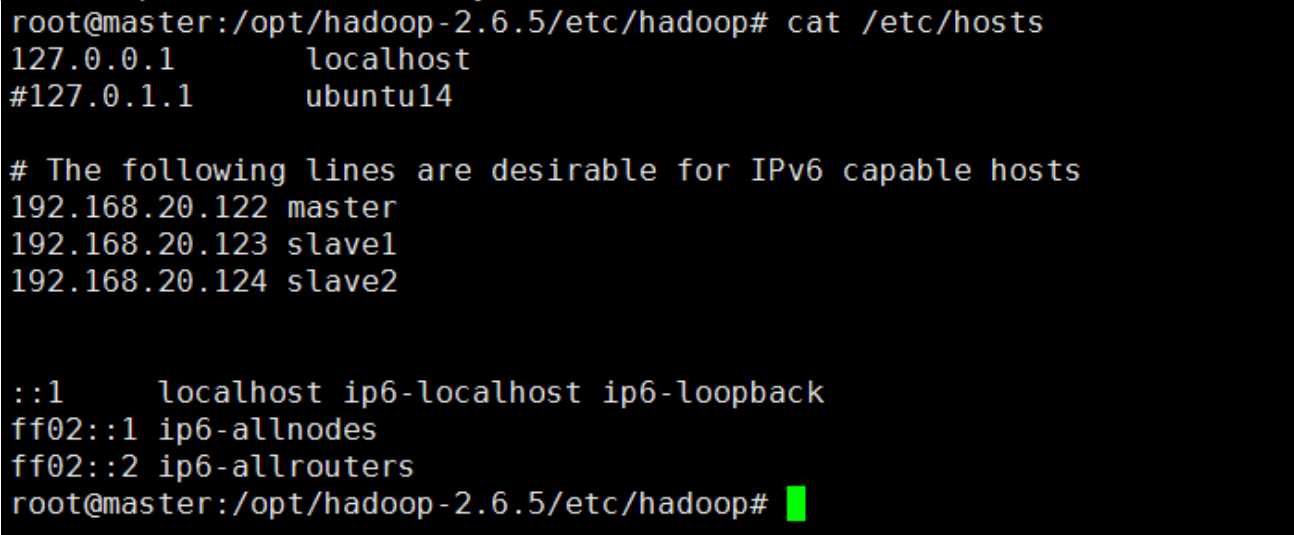
1.5.2 修改/etc/hostname,为绑定计算机名。(计算机名和上面 hosts 绑定名必须一致)
1.6 SSH 无密码登陆(需提前安装 ssh)
1、ssh-keygen -t rsa #用 rsa 生成密钥,一路回车。
2、cd ~/.ssh #进到当前用户的隐藏目录(.ssh)。
3、本机装有 ssh-copy-id 命令,可以通过
ssh-copy-id [email protected]第二台机器名然后输入密码,在此之后在登陆第二台机器,可以直接 ssh[空格]第二台机器名 进行访问,首次设置需要输入密码,第二次之后不再需要输入密码。
1.7 JDK 安装(三台机器可同步进行)
下载:jdk-8u131-linux-x64.tar.gz 包,放到/opt 下解压
1.7.1 将解压后的文件夹重命名
mv jdk1.8.0_131 jdk1.7.1 将 JDK 环境变量配置到/etc/profile 中
export JAVA_HOME=/opt/jdk
export JRE_HOME=/opt/jdk/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH1.7.2 检查 JDK 是否配置好
source /etc/profile
java -version
1.8 其他配置(三台机器每台单独配置)
1.8.1 网络配置
修改为固定 IP ,/etc/network/interfaces
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
# iface eth0 inet dhcp
iface eth0 inet static
address 192.168.20.122
netmask 255.255.255.0
gateway 192.168.20.1重启网络
service networking restart1.8.2 DNS 配置
第一种方法,永久改
修改/etc/resolvconf/resolv.conf.d/base(这个文件默认是空的)
nameserver 119.6.6.6保存后执行
resolvconf -u查看 resolv.conf 文件就可以看到我们的设置已经加上
cat /etc/resolv.conf重启 resolv
/etc/init.d/resolvconf restart第二种方法,临时 改
修改 /etc/resolv.conf 文件,增加
nameserver 119.6.6.6重启 resolv
/etc/init.d/resolvconf restart二、Hadoop 部署
2.1 Hadoop 安装(三台机器可同步进行)
- 下载 hadoop2.6.5(hadoop-2.6.5.tar.gz)
- 解压 tar -zxvf hadoop-2.6.5.tar.gz ,并在主目录下创建 tmp、dfs、dfs/name、dfs/node、dfs/data
[email protected]:/opt/hadoop-2.6.5# mkdir tmp
[email protected]:/opt/hadoop-2.6.5# mkdir dfs
[email protected]:/opt/hadoop-2.6.5# mkdir dfs/name
[email protected]:/opt/hadoop-2.6.5# mkdir dfs/node
[email protected]:/opt/hadoop-2.6.5# mkdir dfs/data2.2 Hadoop 配置
以下操作都在 hadoop-2.6.5/etc/hadoop 下进行
2.2.1 编辑 hadoop-env.sh 文件,修改 JAVA_HOME 配置项为 JDK 安装目录
export JAVA_HOME=/opt/jdk2.2.2 编辑 core-site.xml 文件,添加以下内容,其中 master 为计算机名,/opt/hadoop-2.6.5/tmp 为手动创建的目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.6.5/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>2.2.3 编辑hdfs-site.xml文件,添加以下内容
其中master为计算机名,file:/opt/hadoop-2.6.5/dfs/name和file:/opt/hadoop-2.6.5/dfs/data为手动创建目录
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.6.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.6.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>复制mapred-site.xml.template并重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml2.2.4 编辑mapred-site.xml文件,添加以下内容
其中master为计算机名
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>2.2.5 编辑yarn-site.xml文件,添加以下内容
其中master为计算机名
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>2.2.6 修改slaves文件,添加本机作为集群节点

2.2.7 Hadoop集群搭建
hadoop配置集群,可以将配置文件etc/hadoop下内容同步到其他机器上,既2.2.1-2.2.6无需在一个个配置。
cd /opt/hadoop-2.6.5/etc
scp -r hadoop [email protected]另一台机器名:/opt/hadoop-2.6.5/etc2.3 Hadoop启动
1.格式化一个新的文件系统,进入到hadoop-2.6.5/bin下执行:
./hadoop namenode -format2.启动hadoop,进入到hadoop-2.6.5/sbin下执行:
./start-all.sh看到如下内容说明启动成功

2.4 Hadoop集群检查
检查hadoop集群,进入hadoop-2.6.5/bin下执行
./hdfs dfsadmin -report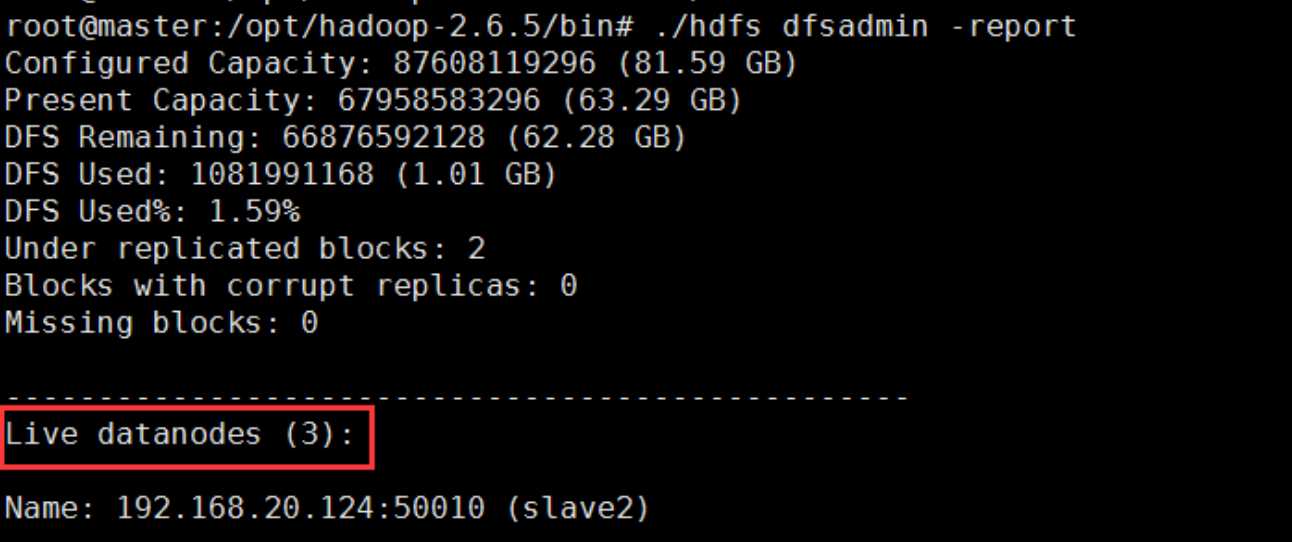
三、ZooKeeper集群部署
3.1 ZooKeeper安装(三台机器可同步进行)
- 下载ZooKeeper(zookeeper-3.4.10.tar.gz),放到opt目录下
- 解压zookeeper-3.4.10.tar.gz,并将解压后的目录名进行修改
tar -zxvf zookeeper-3.4.10.tar.gz
mv zookeeper-3.4.10 zookeeper3.2 ZooKeeper配置(三台机器可同步进行)
1.进入解压后的的zookeeper目录,创建存储数据目录zkdata
cd /opt/zookeeper
mkdir zkdata2.进入zookeeper/conf目录,复制zoo_sample.cfg并重命名为zoo.cfg
cd /opt/zookeeper/conf
cp zoo_sample.cfg zoo.cfg3.修改zoo.cfg文件,修改dataDir为我们新创建地址,并增加其他zookeeper节点
dataDir=/opt/zookeeper/zkdata
server.1=192.168.20.122:2888:3888
server.2=192.168.20.123:2888:3888
server.3=192.168.20.124:2888:3888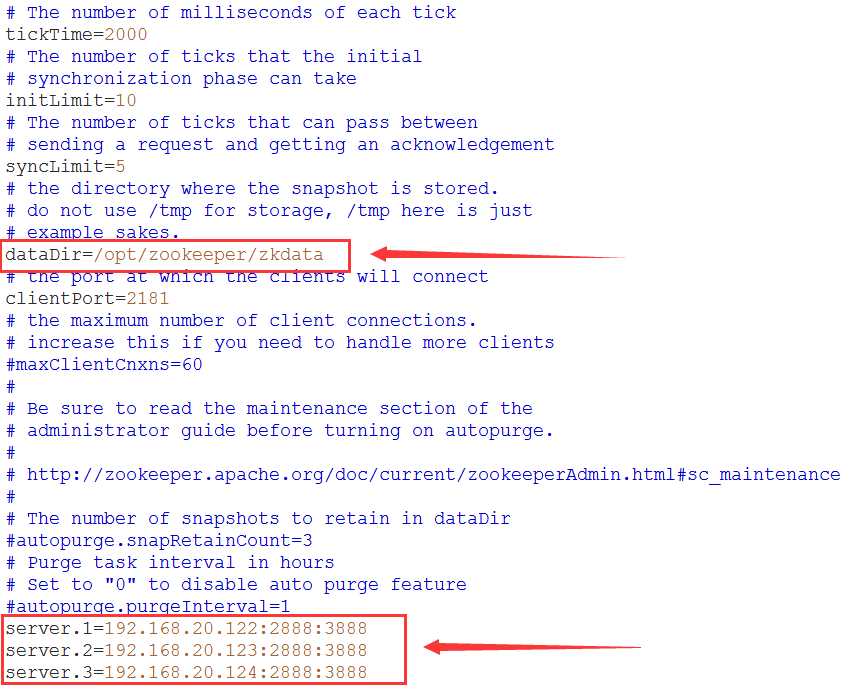
4.进入zkdata目录,新建一个文件myid文件,写入标识ID即可,ID与上面server.X相匹配
cd /opt/zookeeper-3.4.10/zkdata
vi myid注意:
比如我配置的三个server,myid里面写的X就是server.X=ip:2888:3888 中ip所对应的X
server.1=192.168.20.122:2888:3888【192.168.20.122服务器上面的myid填写1】
server.2=192.168.20.123:2888:3888【192.168.20.123服务器上面的myid填写2】
server.3=192.168.20.124:2888:3888【192.168.20.124服务器上面的myid填写3】
3.3 ZooKeeper启动
在三台机器上分别手动一个个启动ZooKeeper,进入/opt/zookeeper-3.4.10/bin目录
cd /opt/zookeeper/bin
./zkServer.sh start是否启动成功,执行以下命令
./zkServer.sh status122机器输出
[email protected]:/opt/zookeeper/bin# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower123机器输出
[email protected]:/opt/zookeeper/bin# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: leader124机器输出
[email protected]:/opt/zookeeper/bin# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower启动过程命令:./zkServer.sh start-foreground
四、HBase部署
4.1 HBase安装
- 下载HBase(hbase-1.3.1-bin.tar.gz),放到opt目录下
- 解压hbase-1.3.1-bin.tar.gz
tar -zxvf hbase-1.3.1-bin.tar.gz4.2 HBase配置
1.进入habase的conf目录
/opt/hbase-1.3.1/conf2.编辑hbase-env.sh文件,添加Java环境变量并关闭HBase自带的Zookeeper
export JAVA_HOME=/opt/jdk/
export HBASE_MANAGES_ZK=false3.编辑hbase-site.xml 文件,添加配置
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>master:60000</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>100</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hbase.zoopkeeper.property.dataDir</name>
<value>/opt/zookeeper/zkdata</value>
</property>
</configuration>4.编辑regionservers文件,将三台机器名添加其中
[email protected]:/opt/hbase-1.3.1/conf# cat regionservers
master
slave1
slave24.3 第三方包导入
第三方包,我们只需要geomesa-hbase中的一个jar文件,将该jar包复制到hbase中的lib目录。
geomesa-hbase下载地址:https://github.com/locationtech/geomesa/releases
此次我们使用2.11-2.0.1版本,下载后完整包名为:geomesa-hbase_2.11-2.0.1-bin.tar.gz
所使用的jar包位于geomesa-hbase_2.11-2.0.1/dist/hbase/geomesa-hbase-distributed-runtime_2.11-2.0.1.jar
cd /opt/hbase-1.3.1/lib
cp /opt/geomesa-hbase-distributed-runtime_2.11-2.0.1.jar .4.4 其它2个节点也进行同步进行上述操作
可以使用scp方式进行同步,也可以将第三方复制到其它节点,将修改的几个配置文件进行替换
#scp命令
cd /opt
scp -r hbase-1.3.1 [email protected]:/opt
scp -r hbase-1.3.1 [email protected]:/opt4.5 HBase启动
进入HBase中bin目录下,执行以下命令,完成HBase集群启动
./start-hbase.sh 4.6 检查HBase集群
浏览器访问http://192.168.20.122:16010/ (其中192.168.20.122为master节点IP)
能看到三个节点,则表示HBase集群搭建成功
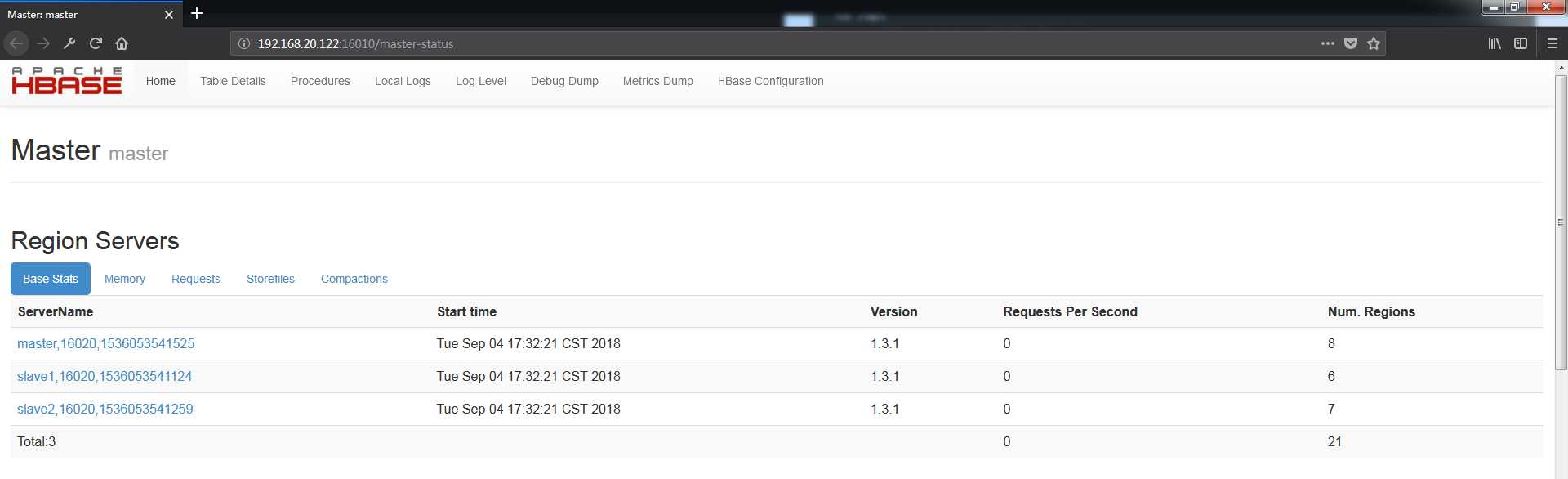
(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)
以上是关于HBase集群环境搭建的主要内容,如果未能解决你的问题,请参考以下文章
学习搭建Hadoop+HBase+ZooKeeper分布式集群环境