1.欠拟合与过拟合概念
Posted kexinxin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1.欠拟合与过拟合概念相关的知识,希望对你有一定的参考价值。
- 欠拟合与过拟合概念
- 欠拟合与过拟合概念
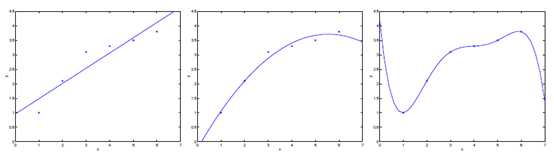
图3-1 欠拟合与过拟合概念演示
通常,你选择让交给学习算法处理的特征的方式对算法的工作过程有很大影响。如图3-1中左图所示,采用了y = θ0 + θ1x的假设来建立模型,我们发现较少的特征并不能很好的拟合数据,这种情况称之为欠拟合(underfitting)。而如果我们采用了y = θ0 + θ1x+ θ2x2的假设来建立模型,发现能够非常好的拟合数据(如中图所示);此外,如果我们采用了y = θ0 + θ1x+ θ2x2+ θ3x3 + θ4x4 + θ5x5,发现较多的特征导致了所有的训练数据都被完美的拟合上了,这种情况称之为过拟合(overfitting)。
这里,我们稍微谈一下过拟合问题,过拟合的标准定义(来自Mitchell的机器学习)标准定义:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h‘属于H,使得在训练样例上h的错误率比h‘小,但在整个实例分布上h‘比h的错误率小,那么就说假设h过度拟合训练数据。过拟合问题往往是由于训练数据少(无法覆盖所有的特征学习,换句话也可以认为是特征太多)等原因造成的。在以后的课程会具体讲解。
对于此类学习问题,一般使用特征选择算法(有一讲专门讲)或非参数学习算法,下面将要降到的局部加权线性回归就是属于该方法,以此缓解对于特征选取的需求。
- 局部加权线性回归
局部加权线性回归(locally weighted linear regression)属于非参数学习算法的一种,也称作Loess。
对于原始的回归分析,我们基本的算法思想是:
1) 寻找合适的θ使得 最小;2) 预测输出。
而对于局部加权线性回归算法的基本思想是:
1) 寻找合适的θ使得 最小;2) 预测输出。
这里,局部加权线性回归与原始回归分析不同在于,多了权重wi,该值是正的。对于特点的点,如果权重w较大,那么我们选择合适的θ使得最小;如果权重w较小,那么误差的平方方在拟合过程中将会被忽略掉。换言之,对于局部加权回归,当要处理x时,会检查数据集合,并且只考虑位于x周围的固定区域内的数据点(较远点不影响因权重较低而被忽略),对这个区域内的点做线性回归,拟合出一条直线,根据这条拟合直线对x的输出,作为算法返回的结果。
一个标准的且常用的权重选择如下:
wi = exp(-)
需要注意,这里的x是我们要预测的输入,而xi是训练样本数据。从公式看,离x越近的点,权重越大,而这里的权重公式虽然与高斯分布很像,但是没有任何关系,当然用户可以选择不同的函数作为权重函数。而τ决定了各个点权重随距离下降的速度,称之为波长。τ越大,即波长越大,权重下降速度越慢。如何选择合适的τ值,将会在模型选择一讲讲述。另外需要注意的是,如果x是多维特征数据的时候,那么权重是多维特征参与计算后的结果(结果为一维),即w(i) = exp(?(x(i)?x)T (x(i)?x)/())。(i表示样本下标,j表示特征下标)
对于回归问题,我们不禁要问为什么线性回归或者说为什么最小均方法是一个合理的选择呢?这里我们通过一系列的概率假设给出一个解释。
对于上式,最大化似然函数L(θ)就相当于最小化,即J(θ)。
需要注意的是,对于上面的讨论,最终的θ选择并不依赖于(我们假设的误差俯冲的分布方差)尽管值并不知道。当讨论到指数族和广义线性回归的时候,我们还会提到这些。
注意:我们用到的假设,第一残差项独立同分布且分布均值为0,样本之间相互独立,此外,要想有结果需要输入特征不存在多重共线性,即输入特征是满秩矩阵。
针对分类问题,我们可以暂时忽略y的离散性,而采用回归分析的方法进行分析。然而,我们很容易发现回归分析效果很差,尤其是不好解释预测值不等于{0,1}的情况。为此,我们需要更改我们假设:
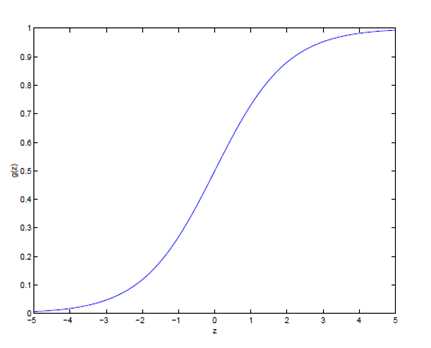
hθ(x) = g() = 这里的g(z) = ,被称之为logistic函数或sigmoid函数。函数图形如下:
我们假设:P(y=1 | x;θ) = hθ(x) P(y=0 | x;θ) = 1- hθ(x) 该假设可以归结为:
p(y | x;θ) = (hθ(x))y* (1- hθ(x))(1-y)
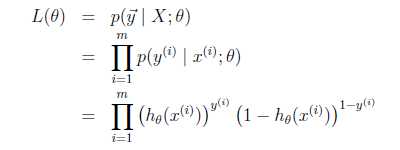
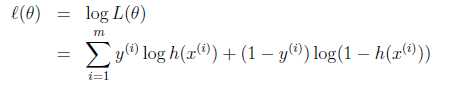
同样,我们采用梯度下降法来迭代求取参数值,即按照θj := θj? α*方式跟新参数值。
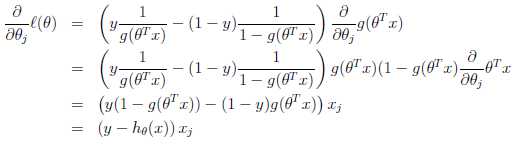
在推导过程中,我们使用g‘(z)=g(z)*(1-g(z))该特性。最终的更新结果如下:
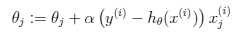
在logistic方法中,g(z)会生成[0,1]之间的小数,但如何是g(z)只生成0或1?这里我们重新定义g(z)函数如下:
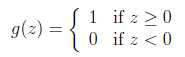
20世纪60年代,认为在神经网络模型采用"感知器学习"算法的神经元是较为粗糙的,但是他仍然能很好的表达学习算法理论。虽然从公式外形上来看,感知器学习与logistic回归和线性回归差不多,但是我们很难赋予感知器预测值的概率解释,或者使用最大似然估计推导出感知器模型。
以上是关于1.欠拟合与过拟合概念的主要内容,如果未能解决你的问题,请参考以下文章
机器学习之路:python 多项式特征生成PolynomialFeatures 欠拟合与过拟合