马尔可夫决策过程
Posted kexinxin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了马尔可夫决策过程相关的知识,希望对你有一定的参考价值。
马尔可夫决策过程
- 概述
现在我们开始讨论增强学习(RL,reinforcement learning)和自适应控制( adaptive control)。在监督式学习中,我们的算法总是尝试着在训练集合中使预测输出尽可能的模仿(mimic)实际标签y(或者潜在标签)。在这样的设置下,标签明确的给出了每个输入x的正确答案。然而,对于许多序列决策和控制问题(sequential decision making and control problems),很难提供这样的明确的监督式学习。比如我们现在正在做一个四条腿的机器人,目前我们正在尝试编程让他能够行走,在最开始的时候,我们就无法定义什么是正确的行走,那么我们就无法提供一个明确的监督式学习算法来尝试模仿。
在增强学习框架下,我们的算法将仅包含回报函数(reward function),该函数能够表明学习主体(learning agent)什么时候做的好,什么时候做的不好。在四足机器人行走例子中,回报函数可以是在机器人向前移动时,给予机器人积极的回报,在机器人后退后者跌倒时给予消极的回报。那么我们的学习算法任务是如何随着时间的变化而选择一个能够让回报最大的行动。
目前增强学习已经能够成功的应用在不同的自主直升飞机驾驶、机器人步态运动、手机网络路由、市场策略选择、工厂控制和不同的网页检索等等。在这里,我们的增强学习将从马尔可夫决策过程(MDP, Markov decision processes)开始。
- 马尔可夫决策过程
一个马尔可夫决策过程是一个元组 (S, A, {Psa}, γ, R),其中(以自主直升飞机驾驶为例):
- S是状态(states)集合,例:直升飞机的所有可能的位置和方向的集合。
- A是动作(actions)集合,例:可以控制直升飞机方向的方向集合
- Psa是状态转移概率,例:对于每个状态s∈ S,动作a∈ A,Psa是在状态空间的一个分布。之后我们会详细介绍,简而言之Psa给出了在状态s下采取动作a,我们会转移到其他状态的概率分布情况。
- γ ∈ [0, 1),称之为折现因子(discount factor)
- R:S × A → R是回报函数。有些时候回报函数也可以仅仅是S的函数。
MDP动态过程如下:我们的学习体(agent)以某状态s0开始,之后选择了一些动作a0 ∈ A并执行,之后按照Psa概率随机转移到下一个状态s1,其中s1 ~ Ps0a0。之后再选择另一个动作a1 ∈ A并执行,状态转移后得到s2~ Ps1a1,之后不断的继续下去。即如下图所示:
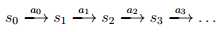
基于上面一系列的在状态s0,s1,…,伴随着动作a0,a1,…,我们最终的回报为: R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+…当我们仅以状态来定义回报,总回报为R(s0)+γR(s1)+γ2R(s2)+…,在多数情况下,尽管基于状态-动作的回报函数R(s,a)并不是很难给出,但是我们仍将会选择较为简单的基于状态的回报函数R(s)。
在增强学习中,我们的目标就是在时间过程中,选择合适的动作,使得最终的回报期望最大,其中回报期望为E[R(s0)+γR(s1)+γ2R(s2)+…]。注意在时间步t下的回报函数的折现因子为γt。为了使得期望最大,我们希望过程中尽可能的取得积极的回报(也尽可能的减少消极回报)。在经济学应用中,R(·)是赚取的钱的数量,而γ则可以解释为利率(即今天的一美元比明天的一美元更值钱)。
一个策略(policy)是对于任意函数π : S → A,即从状态到动作函数。无论什么时候,如果我们在状态s,那么我们就会执行一些策略π,使得我们的动作a=π(s)。对于策略π,我们定义值函数(value function)为:Vπ(s)=E[R(s0)+γR(s1)+γ2R(s2)+· · ·|s0=s,π],其中Vπ(s)是在状态为s下,采取基于策略π而选择行动a的各个折现回报总和的期望(the expected sum of discounted rewards)。
对于一个策略π,它的值函数Vπ满足贝尔曼等式(Bellman equations):
Vπ(s)= R(s) +γ
这说明折现回报总和的期望Vπ(s)包含两项:其一是即时汇报(immediate reward) R(s),即在开始状态s就可以直接得到的汇报。而第二项是未来折现回报总和的期望。进一步看第二项,求和项可以写成Es′~Psπ(s)[Vπ(s′)],这是在状态s‘下的折现回报总和的期望,这里的s‘满足Psπ(s)分布,而Psπ(s)是我们在MDP中状态s下采取动作a的转移概率。这样,第二项就可以看成是MDP第一步之后,观察到的折现回报总和的期望。
我们可以用贝尔曼等式求解Vπ,即在有限状态的MDP(|S|<∞),对于每一个状态s都可以得到Vπ(s),那么我们就得到了一系列关于 |S| 的线性等式(对于每个状态s,Vπ(s)未知)。此外,我们定义最优值方程为V?(s) = maxπVπ(s),即在所有的策略π中,寻找能够使得折现回报总和期望最大的最优策略。把该表达式转换成贝尔曼等式形式,即
V?(s) = R(s) + maxa∈A γ
这里的第一项就是之前说的即时回报,而第二项就是在行动a之后各个状态的折现回报总和的期望。
我们也定义最优策略π?:S → A,如下:
π?(s) = arg maxa∈A
注意是π?(s)给出了动作a,而动作a使得该式子最大化。
事实上,对于每一个状态s和策略π,我们都有V?(s) = Vπ?(s) ≥ Vπ(s),这里第一个等式说明对于最优策略π?的值等于最优值。而不等式说明,π?的值在所有的策略中是最优的。这里需要注意π?对于所有的s都是最优策略。也就是说,π?并不是对于某些状态的最优策略,而是对于所有状态而言的,换句话说无论我们MDP的初始状态是什么,都是最优的策略。
- 值迭代和策略迭代
我们讨论两个有效的算法用来求解有限状态下MDP。接下来,我们讨论的MDP是在状态空间和动作空间均是有限空间的情况下,即|S | <∞, |A| < ∞。
第一个方法是值迭代,如下:
-
对于每一个状态s,初始化V(s) := 0
-
循环直到收敛 {
对于每一个状态,更新V (s) := R(s) + maxa∈A γ }
该算法是根据贝尔曼等式不断的尝试更新值函数,以得到最优值函数。
在内循环中,有两种方法。第一种是,我们可以计算每一个状态s的新值V(s),然后用这些值更新旧的值(统一更新)。这称之为同步更新(synchronous update)。在这个例子中,算法可以被认为是Bellman backup operator的一个应用,即估计当前的值作为新值。此外,我们也可以采用异步更新(asynchronous updates),也就是在按照某个顺序循环所有状态,然后更新一次值。在同步更新中,第一次更新之后,V(s)=R(s),而对于异步更新,第一次更新之后大部分V(s)>R(s)。
无论是同步更新还是异步更新,值迭代都可以由V收敛到V*,在得到V* 之后,我们就可以根据π?(s)得到最优的策略。
另外一种求解算法是策略迭代(policy iteration),算法如下:
-
随机初始化策略π
-
循环直到收敛 {
a) 令 V := Vπ
b) 对于每一个状态s,取π(s) := maxa∈A γ}
这里的内循环不断重复的计算当前策略的值函数,然后使用当前的值函数更新策略(b)中更新的策略π也被称为对于V的贪婪策略)。注意步骤a)可以用求解贝尔曼方程来得到Vπ。在足够多的迭代下,V会收敛到V*,π会收敛到π*。
以上两种算法是求解MDP的标准算法,但并不是说没有更好的方法。对于小的MDP,策略迭代通常能够更快的收敛。而对于具有较大状态空间的MDP而言,求解V*是非常困难的(需要求解大量的线性等式),这时候一般选择值迭代。因此,在实际问题中值迭代通常多余策略迭代。
- MDP的一个学习模型
到目前为止,我们已经讨论了MDP以及在状态转移概率和回报已知的情况下求解MDP的算法。在许多现实的例子里,我们并不知道明确的状态转移概率和回报,因此必须从数据中提取(通常S,A,γ是已知的)。
举个例子,对于倒摆问题(inverted pendulum problem,倒摆是一个棒通过一个连接轴,其底端连接在一辆可推动的小车上,控制的目的是当倒摆出现偏角时,在水平方向上给小车以作用力,通过小车的水平运动,使倒摆保持在垂直的位置。),我们有多个路径(这里成为转移链)的状态转移路线如下:
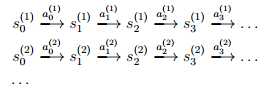
这里的s(j )i是在时间i转移链j下的状态,a(j )i是在那个状态之后采取的动作。实际上,每个转移路径中状态数是有限的,每个转移链要么进入终结状态,要么达到规定的步数就会终结。如果我们获得了很多上面类似的转移链(相当于有了样本),那么我们就可以使用最大似然估计来估计状态转移概率,Psa(s‘) = A/B,其中A是样本中在状态s采取动作a而到达s‘的总次数,B是在状态s下采取行动a的总次数。此外,如果A=B=0,就表明了在状态s下从来没有采取过动作a,这个时候可以令Psa(s‘) = 1/|S| (即转移到各个状态的概率相等)。
注意,如果我们在MDP中得到越多的经验(越多的转移链),那么我们有很有效的方法来更新我们的转移概率。也就是说我们只需要根据更多的观测样本,就可以很容易的更新分子分母,进而更新得到Psa。相似的,如果R是未知的,那么我们可以选择在状态s下的即时回报R(s)的期望为在所有样本观测到的状态s下回报的均值。
在此基础之上(使用转移链中估计到的转移概率和回报),我们可以选择使用值迭代或策略迭代求解MDP。以值迭代为例,把所有的放在一起,得到一个MDP学习算法,整体如下:
-
随机初始化策略π
-
循环{
-
统计执行了策略π的样本;
-
根据样本估计Psa (如果可以,则得到R);
-
根据估计的状态转移概率和回报,采用值迭代得到一个V新的估计值;
-
根据V的贪婪策略更新策略π }
-
我们注意到,对于该算法,有一个优化的方法使得他可以运行的更快。即在算法的内循环中,我们使用了值迭代,如果初始化V的时候不为0,而使用在上一次大循环中得到的V,那么在一个更好的初始化V值的情况下,该算法迭代的速度将会更快。
以上是关于马尔可夫决策过程的主要内容,如果未能解决你的问题,请参考以下文章