20155317《信息安全系统设计基础》第十四周学习总结
教材学习内容总结
第6章学习要点:
- 了解常见的存储技术(RAM、ROM、磁盘、固态硬盘等)
- 理解局部性原理
- 理解缓存思想
- 理解局部性原理和缓存思想在存储层次结构中的应用
- 高速缓存的原理和应用
一、概述
虚拟存储器的三个重要能力:
- 它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,高效的使用了主存
- 它为每个进程提供了一致的地址空间,从而简化了存储器管理
- 它保护了每个进程的地址空间不被其他进程破坏
虚拟存储器是中心的、强大的、危险的。
二、虚拟存储器
2.1、非易失性存储器 ROM(只读存储器)
实际上ROM中有的类型既可以读也可以写,仍称之为“只读存储器”是历史原因。存在ROM中的程序称为固件,当一个计算机系统通电以后,它会运行存储在ROM中的固件。一些系统在固件中提供了少量基本的输入输出函数。
ROM可按照它们能够被重编程的次数和对它们进行重编程所用的机制分类为:
PROM(可编程ROM),EPROM(可擦写可编程ROM),闪存(基于EEPROM),固态硬盘(SSD,基于闪存)
2.2、易失性存储器 SRAM和DRAM
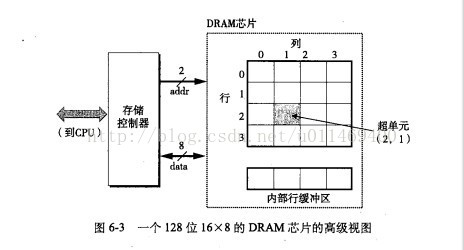
每个方块代表由w位(一般为8位,这样一个超单元就表示一个字节)bit组成的超单元,整个DRAM由d个超单元组织成二维阵列构成。DRAM中的数据以超单元为单位访问。通过地址引脚传入的RAS(行访问选通脉冲)和CAS(列访问选通脉冲)访问某个超单元,然后加载目标所在行到内部行缓冲区,通过8位的数据引脚输出目标。
之所以将超单元组织成二维阵列而非线性数组,是为了减少地址的位数,尽管需要付出增加一个传入地址的代价。
三、缓存
1、概念
第k+1层的存储器被划分成连续的数据对象片,称为块。每个块都有唯一的地址或名字以区别于其他块。数据总以块大小为传送单元在第k层和第k+1层之间来回拷贝。虽然在层析结构中任何一对相邻的层次之间块大小是固定的,但是其他的层次对之间可以有不同的块大小。第k层存储的块集合是第k+1层的子集的拷贝。
2、缓存不命中
类别:冷不命中,冲突不命中,容量不命中。
策略:替换(或称驱逐)一个现存块,替换策略有随机替换策略、最近最少被使用替换策略等。
3、通用的高速缓存存储器结构(层次对间地址空间“多对少”的映射策略)可用(S,E,B,m)来描述一个高速缓存的结构。如下图,右图每种不同色代表一个块,且块映射到不同组。
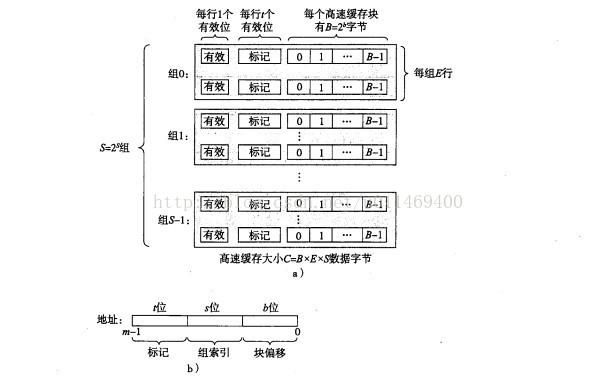

3.1.、分类:直接映射高速缓存、全相联高速缓存、组相联高速缓存(前两者的折中)
3.2、访问某个存储器地址的过程:逐级访问各存储器层次,进行三步——组选择,行匹配,字抽取(若命中)——直到命中
4、关于写操作
直写与非写分配:直写是指命中后立即将目标字所在命中块写回到紧接着低一层中;非写分配是指不命中时直接将目标字写到低一层中。
写回与写分配:写回是指命中后延迟更新低一层直到命中块被驱逐;写分配是指不命中时加载响应的低一层中的块到高速缓存中,然后更新这一高速缓存块(试图利用写的空间局部性)。
5、高速缓存参数的性能影响:
与性能相关的一些量化指标:不命中率、命中率、命中时间、不命中处罚。
高速缓存参数对性能的影响:缓存大小的影响,块大小的影响,相联度的影响,写策略的影响。
四、存储器层次结构
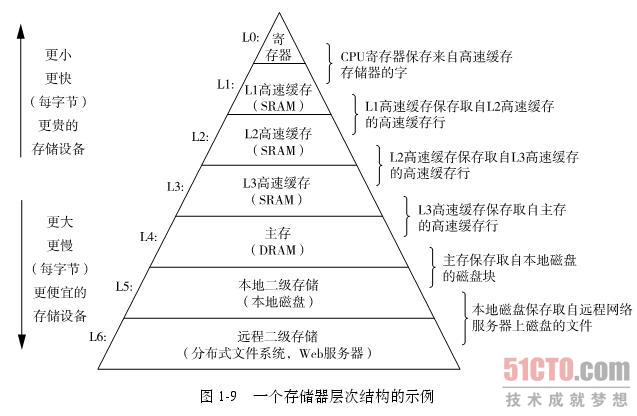
五、局部性:
在存储器层次结构的基础之上引出了一个很重要的思想,也是计算机程序里面一个很基本的属性”局部性“。局部性又分为两个方面:
- 时间局部性:有良好的时间局部性程序中,被引用过一次的存储器很有可能在不久的将来再被多次调用
- 空间局部 性:有良好空间局部性程序中,被引用过一次的存储器,很有可能在不久的将来引用其附近临近的存储器。
- 由此可以给出量化评价 一个程序局部性的简单原则:
- 1、重复引用一个变量的程序有良好的时间局部性;
- 2、对于步长为k的引用模式的程序,步长越小, 程序的空间局部性越好;
- 3、对于取指令来说,循环有好的时间和空间局部性。
家庭作业
6.22
假设磁道沿半径均匀分布,即总磁道数和(1-x)r成正比,设磁道数为(1-x)rk;
由题单个磁道的位数和周长成正比,即和半径xr成正比,设单个磁道的位数为xrz;
其中r、k、z均为常数。
所以C = (1-x)rk * xrz = (-x^2 + x) * r^2 * kz,即需要-x^2 + x最大,得到x = 0.5
6.36
A.
cache共有32个block,分别位于32个set中,每个block可以放下4个int类型的变量,所以所有的block可以放下x数组中的一行。由映射关系,x[0][i]和x[1][i]对应的set是一样的。所以每一次的运算都会发生miss的情况,所以miss rate = 100%。
B.
cache共有64个block,分别位于64个set中,每个block可以放下4个int类型的变量,所以所有的block可以放下x数组中的两行,即全部放入。每四次读取中的第一次会发生miss,所以miss rate = 25%。
C.
cache共有32个block,分别位于16个set中,每个block可以放下4个int类型的变量,每个set可以放下8个int类型的变量,所有的block可以放下x数组中的一行。由映射关系,x[0][i]和x[1][i]对应的set是一样的,x[y][i]和x[y][i+64]对应的set也是一样的。
对于x[0][0] * x[1][0] ~ x[0][63] * x[1][63] ,每四次运算会有第一次miss。
对于x[0][64] * x[1][64] ~ x[0][127] * x[1][127] ,每四次运算会有第一次miss(擦去前面warm up的cache)。
综上,miss rate = 25%。
D.
不会,因为此时block大小是限制因素(每四次读取第一次miss)。
E.
会,更大的block会降低miss rate,因为miss只发生在第一次读入block的时候,所以更大的block会使得miss占总读取的比例降低。
6.37
cache共有256个block,分别位于256个set中,每个block可以放下4个int类型的变量,所有的block可以放下1024个int类型的变量。
当N = 64:
映射关系:a[0][0] ~ a[15][63]、a[16][0] ~ a[31][63]、a[32][0] ~ a[47][63]、a[48][0] ~ a[63][63] 互相重叠。
sumA按照行来读取,所以每四次读取第一次都会miss,即miss rate = 25%。
sumB按照列来读取,所以每一次读取都会发生miss(读取后的block又会被覆盖),即miss rate = 100%。
sumC按照列来读取,但是每次读取后都会按照行再读取一次,所以每四次读取会有两次miss,即miss rate = 50%。
当N = 60
映射关系:a[0][0] ~ a[17][3]、a[17][4] ~ a[34][7]、a[34][8] ~ a[51][11]、a[51][12] ~ a[59][59]互相重叠,其中最后的a[51][12] ~ a[59][59]没有到达cache的尾部。
sumA按照行来读取,所以每四次读取第一次都会miss,即miss rate = 25%。
6.38
这个cache有64个block,每个block可以放4个int类型的变量,也就是一个point_color的结构体,即cache总共可以放置64个结构体。
映射关系为:square[0][0] ~ square[3][15]、square[4][0] ~ square[7][15]、square[8][0] ~ square[11][15]、square[12][0] ~ square[15][15] 互相重叠。
A.
16 * 16 * 4 = 1024
B.
这个程序是按照行来写的,所以每四次写入只有第一次miss,即miss的次数为1024 / 4 = 256
C.
25%
6.39
这个cache有64个block,每个block可以放4个int类型的变量,也就是一个point_color的结构体,即cache总共可以放置64个结构体。
映射关系为:square[0][0] ~ square[3][15]、square[4][0] ~ square[7][15]、square[8][0] ~ square[11][15]、square[12][0] ~ square[15][15] 互相重叠。
A.
16 * 16 * 4 = 1024
B.
这个程序是按照列来写的,每四次写入只有第一次miss(每次都完整利用了一个block,没有读入block的浪费,此时miss rate只取决于block的大小),即miss的次数为1024 / 4 = 256
C.
25%
6.40
这个cache有64个block,每个block可以放4个int类型的变量,也就是一个point_color的结构体,即cache总共可以放置64个结构体。
映射关系为:square[0][0] ~ square[3][15]、square[4][0] ~ square[7][15]、square[8][0] ~ square[11][15]、square[12][0] ~ square[15][15] 互相重叠。
A.
16 * 16 + 3 * 16 * 16 = 1024
B.
对于第一个循环,每一次写入都会发生miss的情况,最后cache中保存的是square[12][0] ~ square[15][15],而第二个循环又从头开始写入,所以每三次写入的第一次都会发生miss。总的miss次数就是16 * 16 * 2 = 512。
C.
50%
6.44
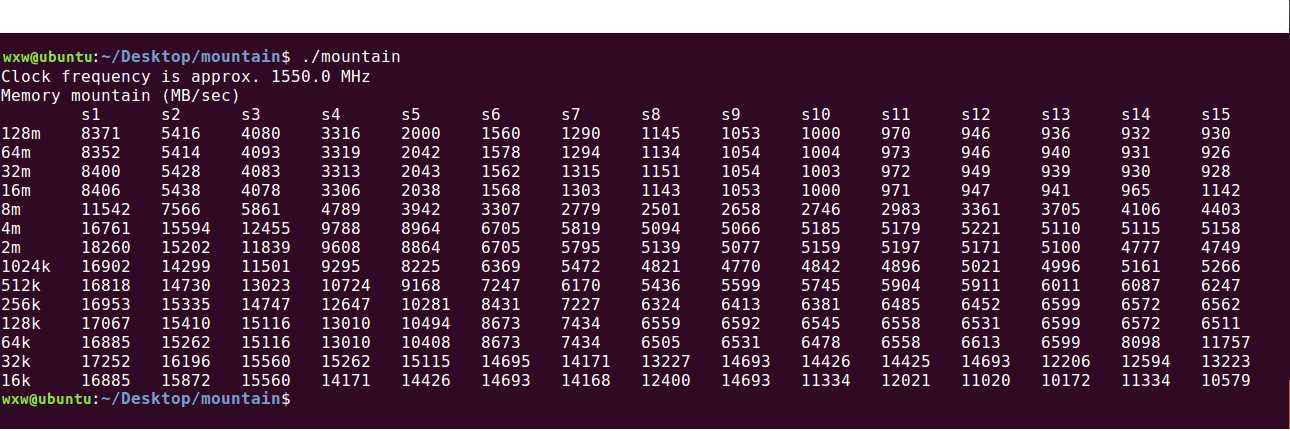
为了辨识缓存的大小,选取中间的列(例如S8)来判断——避免CPU的prefetching带来干扰。可以看出,在32K和512K以及8M的地方有明显的落差,所以判断L1:32k、L2:512k、L3:8M。
代码托管
(statistics.sh脚本的运行结果截图)
上周考试错题总结
- 错题1及原因,理解情况
- 错题2及原因,理解情况
- ...
点评模板:
- 博客中值得学习的或问题:
- xxx
- xxx
- ...
- 代码中值得学习的或问题:
- xxx
- xxx
- ...
- 其他
本周结对学习情况
- [结对同学学号1](博客链接)
- 结对照片
- 结对学习内容
- XXXX
- XXXX
- ...学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:XX小时
-
实际学习时间:XX小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)
参考资料