APScheduler简介
在平常的工作中几乎有一半的功能模块都需要定时任务来推动,例如项目中有一个定时统计程序,定时爬出网站的URL程序,定时检测钓鱼网站的程序等等,都涉及到了关于定时任务的问题,第一时间想到的是利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,虽然这样也可以,但是总觉得不是那么的专业,^_^所以就找到了python的定时任务模块APScheduler:
APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个python定时任务系统。
安装
1、利用pip进行安装
|
1
|
$ pip install apscheduler |
2、源码安装(https://pypi.python.org/pypi/APScheduler/)
|
1
|
$ python setup.py install |
APScheduler有四种组成部分:
触发器(trigger)包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。
作业存储(job store)存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。
执行器(executor)处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
调度器(scheduler)是其他的组成部分。你通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。
简单应用:
|
1
2
3
4
5
6
7
8
9
|
import timefrom apscheduler.schedulers.blocking import BlockingSchedulerdef my_job(): print time.strftime(‘%Y-%m-%d %H:%M:%S‘, time.localtime(time.time()))sched = BlockingScheduler()sched.add_job(my_job, ‘interval‘, seconds=5)sched.start() |
上面的例子表示每隔5s执行一次my_job函数,输出当前时间信息
操作作业
1. 添加作业
上面是通过add_job()来添加作业,另外还有一种方式是通过scheduled_job()修饰器来修饰函数
|
1
2
3
4
5
6
7
8
9
10
|
import timefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()@sched.scheduled_job(‘interval‘, seconds=5)def my_job(): print time.strftime(‘%Y-%m-%d %H:%M:%S‘, time.localtime(time.time()))sched.start() |
2. 移除作业
|
1
2
3
4
5
|
job = scheduler.add_job(myfunc, ‘interval‘, minutes=2)job.remove()#如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效sched.add_job(myfunc, ‘interval‘, minutes=2, id=‘my_job_id‘)sched.remove_job(‘my_job_id‘) |
3. 暂停和恢复作业
暂停作业:
|
1
2
|
apsched.job.Job.pause()apsched.schedulers.base.BaseScheduler.pause_job() |
恢复作业:
|
1
2
|
apsched.job.Job.resume()apsched.schedulers.base.BaseScheduler.resume_job() |
4. 获得job列表
获得调度作业的列表,可以使用get_jobs()来完成,它会返回所有的job实例。或者使用print_jobs()来输出所有格式化的作业列表。也可以利用get_job(任务ID)获取指定任务的作业列表
|
1
2
3
|
job = sched.add_job(my_job, ‘interval‘, seconds=2 ,id=‘123‘)print sched.get_job(job_id=‘123‘)print sched.get_jobs() |
5. 关闭调度器
默认情况下调度器会等待所有正在运行的作业完成后,关闭所有的调度器和作业存储。如果你不想等待,可以将wait选项设置为False。
|
1
2
|
sched.shutdown()sched.shutdown(wait=False) |
作业运行的控制(trigger)
add_job的第二个参数是trigger,它管理着作业的调度方式。它可以为date, interval或者cron。对于不同的trigger,对应的参数也相同。
(1). cron定时调度(某一定时时刻执行)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
(int|str) 表示参数既可以是int类型,也可以是str类型(datetime | str) 表示参数既可以是datetime类型,也可以是str类型year (int|str) – 4-digit year -(表示四位数的年份,如2008年)month (int|str) – month (1-12) -(表示取值范围为1-12月)day (int|str) – day of the (1-31) -(表示取值范围为1-31日)week (int|str) – ISO week (1-53) -(格里历2006年12月31日可以写成2006年-W52-7(扩展形式)或2006W527(紧凑形式))day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun) - (表示一周中的第几天,既可以用0-6表示也可以用其英语缩写表示)hour (int|str) – hour (0-23) - (表示取值范围为0-23时)minute (int|str) – minute (0-59) - (表示取值范围为0-59分)second (int|str) – second (0-59) - (表示取值范围为0-59秒)start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) - (表示开始时间)end_date (datetime|str) – latest possible date/time to trigger on (inclusive) - (表示结束时间)timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) -(表示时区取值) |
参数的取值格式:
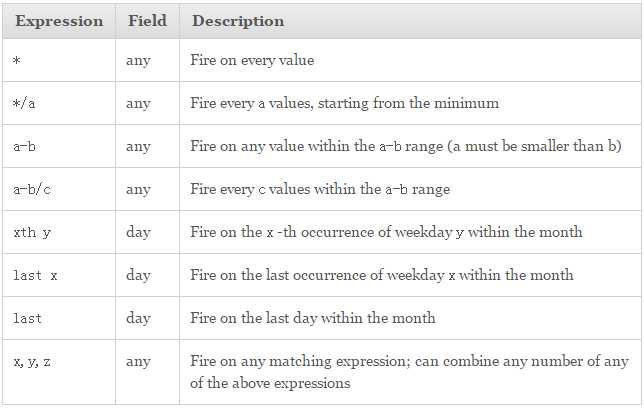
例子:
|
1
2
3
4
5
6
7
8
9
10
11
|
#表示2017年3月22日17时19分07秒执行该程序sched.add_job(my_job, ‘cron‘, year=2017,month = 03,day = 22,hour = 17,minute = 19,second = 07)#表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序sched.add_job(my_job, ‘cron‘, month=‘6-8,11-12‘, day=‘3rd fri‘, hour=‘0-3‘)#表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00sched.add_job(my_job(), ‘cron‘, day_of_week=‘mon-fri‘, hour=5, minute=30,end_date=‘2014-05-30‘)#表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5sched.add_job(my_job, ‘cron‘,second = ‘*/5‘) |
(2). interval 间隔调度(每隔多久执行)
|
1
2
3
4
5
6
7
8
|
weeks (int) – number of weeks to waitdays (int) – number of days to waithours (int) – number of hours to waitminutes (int) – number of minutes to waitseconds (int) – number of seconds to waitstart_date (datetime|str) – starting point for the interval calculationend_date (datetime|str) – latest possible date/time to trigger ontimezone (datetime.tzinfo|str) – time zone to use for the date/time calculations |
例子:
|
1
2
|
#表示每隔3天17时19分07秒执行一次任务sched.add_job(my_job, ‘interval‘,days = 03,hours = 17,minutes = 19,seconds = 07) |
(3). date 定时调度(作业只会执行一次)
|
1
2
|
run_date (datetime|str) – the date/time to run the job at -(任务开始的时间)timezone (datetime.tzinfo|str) – time zone for run_date if it doesn’t have one already |
例子:
|
1
2
3
4
|
# The job will be executed on November 6th, 2009sched.add_job(my_job, ‘date‘, run_date=date(2009, 11, 6), args=[‘text‘])# The job will be executed on November 6th, 2009 at 16:30:05sched.add_job(my_job, ‘date‘, run_date=datetime(2009, 11, 6, 16, 30, 5), args=[‘text‘]) |