Python定时任务框架APScheduler快速入门
Posted 以梦为马&不负韶华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python定时任务框架APScheduler快速入门相关的知识,希望对你有一定的参考价值。
文章目录
前言
常见定时任务:
Crontab:只能在linux环境下使用
Schedule:适合比较轻量级的一些调度任务,复杂场景下难以应用
APScheduler:提供了非常丰富而且方便易用的定时任务接口,灵活强大,还支持持久化存储。
Celery:很强,但本人应用于物联网设备端,硬件资源有限且该技术依赖较多
APScheduler优势:使用起来十分方便。提供了基于日期、固定时间间隔以及crontab 类型的任务,我们可以在主程序的运行过程中快速增加新作业或删除旧作业,如果需要持久化存储,可以把作业存储在数据库中,作业的状态会被保存,当调度器重启时,不必重新添加作业,作业会恢复原状态继续执行。
一、安装
pip install apscheduler
二、简单使用
1.代码如下(示例)
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
def my_clock():
print(f"Hello! The time is:{datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(my_clock, "interval", seconds=3)
scheduler.start()
说明:
本文章都基于:APSchedule(3.7.0)版本
- 第1行:导入调度器模块 BlockingScheduler,这是最简单的调度器,调用 start
方阻塞当前进程。(注:此为APScheduler四组件之schedulers (调度器))。 - 第2行:导入时间日期模块
- 第4-5行:定义my_clock函数,功能为打印出当前时间
- 第7行,为程序主入口
- 第8行:实例化一个 BlockingScheduler类,不带参数表明使用默认的作业存储器-内存(注:此为APScheduler四组件之jobstores (job存储)),默认的执行器是线程池执行器(注:此为APScheduler四组件之executors (执行器)),最大并发线程数默认为 10个(另一个是进程池执行器)
- 第9行: 将my_clock添加到任务调度中。然后看interval参数(注:此为APScheduler四组件之triggers(触发器)),这里用的是间隔的方式来调度,调度频率是seconds=3,也就是每3秒执行一次。
- 第10行:APScheduler 定时任务启动执行
2.APScheduler 的运行流程
1、设定调度器用以对任务的调度与安排进行全局统筹
2、对相应的函数或方法上设定相应的触发器,并添加到调度器中
3、如有任务持久化需要则需要设定对应的持久化层,否则默认使用内存存储任务
4、当触发器被触发时,就将任务交由执行器进行执行
三、APScheduler 四组件
上面的示例中已经引入APScheduler 四组件的概念,我们需要了解这四种组件的概念和用法,才能全局掌握APScheduler 定时任务框架。
1.调度器(schedulers)—不同程序引用
任务调度器是属于整个调度的总指挥官。他会合理安排作业存储器、执行器、触发器进行工作,并进行添加和删除任务等。应用程序开发人员通常不会直接处理作业存储库,执行程序或触发器。相反,调度程序提供了适当的接口来处理所有这些接口。配置作业存储和执行程序是通过计划程序完成的,添加,修改和删除作业也是如此
调度程序的选择主要取决于您的编程环境以及APScheduler的用途。
- BlockingScheduler:当调度程序是您的流程中唯一运行的东西时使用
from apscheduler.schedulers.background import BlockingScheduler
- BackgroundScheduler:在不使用以下任何框架且希望调度程序在应用程序内部的后台运行时使用
from apscheduler.schedulers.background import BackgroundScheduler
- Asyncioscheduler:如果您的应用程序使用asyncio模块,则使用
from apscheduler.schedulers.asyncio import AsyncIOScheduler
- GeventScheduler:如果您的应用程序使用gevent,则使用
from apscheduler.schedulers.gevent import GeventScheduler
- TornadoScheduler:在构建Tornado应用程序时使用 TwistedScheduler:在构建Twisted应用程序时使用
from apscheduler.schedulers.tornado import TornadoScheduler
- QtScheduler:在构建Qt应用程序时使用
from apscheduler.schedulers.qt import QtScheduler
2.任务存储器(job stores)—持久化存储
- 1.默认的任务存储器为内存,不需要配置和管理。如下:
from apscheduler.schedulers.blocking import BackgroundScheduler
scheduler = BackgroundScheduler()
此为选择BackgroundScheduler调度器,不会阻塞程序,使用内存任务存储器。
缺点:非持久化存储,如果调度器重启或应用程序崩溃时,原有的任务就会丢失。
- 2.使用数据库作为任务存储器,持久化存储。调度器重启或应用程序崩溃时,作业可以从中断时恢复正常运行,重新恢复有些作业可能错过时间,可以进行对应设置,比如
misfire_grace_time即作业运行的时间和当下时间的差值,在差值内可继续运行。- SQLAlchemy形式的数据库,这里就主要是指各种传统的关系型数据库,如mysql、PostgreSQL、SQLite 等。
- mongodb 非结构化的 Mongodb 数据库,该类型数据库经常用于对非结构化或版结构化数据的存储或操作,如 JSON。
- redis 内存数据库,通常用作数据缓存来使用,当然通过一些主从复制等方式也能实现当中数据的持久化或保存。
例:jobstores指定任务存储器为sqlite数据库,进行持久化存储。
需要安装sqlalchemy库
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
scheduler = BackgroundScheduler(jobstores=jobstores)
3.任务触发器(triggers)—不同定时模式
APScheduler 任务触发器提供了三种不同的定时模式:
- date:日期触发器。主要是指定时在某一日期时间点进行任务触发,通常适用于一次性任务火作业调度。
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_clock():
print(f"Hello! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(
my_clock,
trigger='date',
run_date=datetime.datetime(2021, 5, 15, 10, 30, 00),
# run_date='2021-05-15 10:30:00'
)
scheduler.start()
上例为trigger指定为date的任务,代表2021年5月15日10时30分00秒运行。
支持如果想立即运行 job ,则可以在添加 job 时省略 trigger 参数;
添加 job 时的日期设置参数支持:
字符串格式('2019-12-31' 或者 '2019-12-31 12:01:30')、datetime.date(datetime.date(2019, 12, 31)) 或者 datetime.datetime(datetime.datetime(2019, 12, 31, 16, 30, 1))
2.interval:间隔触发器。按照时、分、秒、天、周这几个部分进行周期性重复任务。
主要参数:
- start_date(date|datetime|str) - 开始时间,eg:‘2021-01-01 00:00:00’
- end_date(date|datetime|str) - 结束时间,eg:‘2021-12-01 00:00:00’
- weeks(int) - 表示等待时间的周数
- days(int) - 表示等待时间天数
- hours(int) - 表示等待时间小时数
- minutes(int) - 表示等待时间分钟数
- seconds(int) - 表示等待时间秒数
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_clock():
print(f"Hello! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(
my_clock,
trigger='interval',
start_date='2021-01-01 00:00:00',
end_date='2021-12-31 23:59:59',
minutes=2
)
scheduler.start()
上例为从2021年1月1日0时0分0秒到2021年12月31日23时59分59秒,每隔2分钟执行一次任务。
3.cron:cron 表达式触发器。支持cron 表达式,复杂场景下更强大,但APScheduler的cron表达式最多只支持到5位。如果要支持正常的6位或7位cron表达式,可以重写 from apscheduler.triggers.cron import CronTrigger类方法,具体可见我的另一篇博客APScheduler的cron触发器支持到秒级的cron表达式。
- start_date(date|datetime|str) - 开始时间
- end_date(date|datetime|str) - 结束时间
- year(int|str) - 年,4位数
- month(int|str) - 月,1-12
- day(int|str) - 日,1-31
- week(int|str) - 一年中的第多少周,1-53
- day_of_week(int|str) - 星期,0-6 或者 mon,tue,wed,thu,fri,sat,sun
- hour(int|str) - 小时,0-23
- minute(int|str) - 分,0-59
- second(int|str) - 秒,0-59
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def my_clock():
print(f"Hello! The time is:{datetime.datetime.now()}")
scheduler = BackgroundScheduler()
scheduler.start()
# 每天 10 点运行
scheduler.add_job(
my_clock,
trigger='cron',
hour=10
)
# 每天 10 点 30 分 30秒运行
scheduler.add_job(
my_clock,
trigger='cron',
second=10,
minute=30,
hour=30,
)
# 每 10 秒运行一次
scheduler.add_job(
my_clock,
trigger='cron',
second='*/10'
)
# 每天 10:00,11:00,12:00 运行
scheduler.add_job(
my_clock,
trigger='cron',
hour='10-12'
)
# 在 5.6,7,10,11 月的第二个周五 的 10:00,11:00,12:00 运行
scheduler.add_job(
my_clock,
trigger='cron',
month='5-7,10-11',
day='2rd fri',
hour='10-12'
)
# 在 2021-12-31 号之前的周一到周五 5 点 30 分运行
scheduler.add_job(
my_clock,
trigger='cron',
day_of_week='mon-fri',
hour=5,
minute=30,
end_date='2021-12-31'
)
* 匹配字段所有取值
*/a 匹配字段每递增 a 后的值, 从字段最小值开始,包括最小值,比如小时(hour)的 */5,则匹配0,5,10,15,20
a/b 匹配字段每递增 b 后的值, 从字段值 a 开始,包括 a,比如小时(hour)的 2/9,则匹配2,11,20
a-b 匹配字段 a 到 b 之间的取值,a 必须小于 b,包括 a 与 b,比如2-5,则匹配2,3,4,5
a-b/c 匹配 a 到 b 之间每递增 c 后的值,包括 a,不一定包括 b,比如1-20/5,则匹配1,6,11,16
xth y 匹配 y 在当月的第 x 次,比如 3rd fri 指当月的第三个周五
last x 匹配 x 在当月的最后一次,比如 last fri 指当月的最后一个周五
las 匹配当月的最后一天
x,y,z 匹配以 , 分割的多个表达式的组合
4.任务执行器(executors)—线程池、进程池
执行器就是执行任务的对象,在计算机内通常要么是 CPU 调度任务,要么是单独维护一个线程来运行任务。
所以 APScheduler 里的执行器通常就是 ThreadPoolExecutor 或 ProcessPoolExecutor 这样的线程池和进程池两种。
如果是和协程或异步相关的任务调度,还可以使用对应的 AsyncIOExecutor、TwistedExecutor 和 GeventExecutor 三种执行器。
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.executors.pool import ThreadPoolExecutor,ProcessPoolExecutor
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
def my_clock():
print(f"Hello! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler(executors=executors)
scheduler.add_job(my_clock,"interval",seconds=1)
scheduler.start()
配置名为“default”的ThreadPoolExecutor,最大线程数为20
配置名为“processpool”的ProcessPoolExecutor,最大进程数为5
如果不指定,默认为ThreadPoolExecutor为10
四、APScheduler 参数
1.定时任务传参–args、kwargs
使用 args=[参数1] 或 kwargs={“参数名1”: “参数1”} 传参
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
# 传参姓名
def my_clock(name):
print(f"Hello {name}! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler()
# 使用args=[参数1]传参
scheduler.add_job(my_clock, trigger="interval", seconds=1, args=["fmk"])
# 使用kwargs={"参数名1": "参数1"}传参
# scheduler.add_job(my_clock, trigger="interval", seconds=1, kwargs={"name": "fmk"})
scheduler.start()
2.定时任务命名–id,在数据库中查看
使用id给任务命名,方便对该任务进行操作,比如删除、修改等
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
# 传参姓名
def my_clock(name):
print(f"Hello {name}! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler(jobstores=jobstores)
# 使用id给任务命名
scheduler.add_job(my_clock, trigger="interval", seconds=1, args=["fmk"], id='my_clock')
scheduler.start()
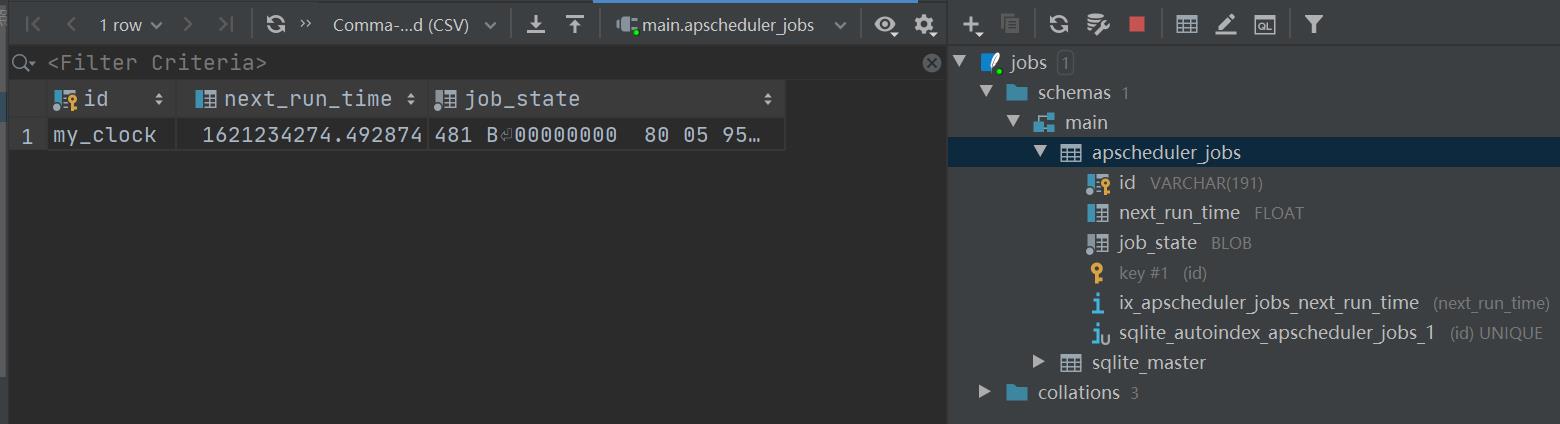
在当前文件统计下有sqlite数据库,apscheduler_jobs默认数据库中存储
数据库中可以看到配置的id,下次运行时间,以及任务状态
3.运行错过的作业—misfire_grace_time
比如每天8点执行的任务,八点整意外掉线,设置misfire_grace_time=60,可以在重新上线,当前时间与规定的时间相差在60s可以再次运行
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
# 传参姓名
def my_clock(name):
print(f"Hello {name}! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler(jobstores=jobstores)
# 使用misfire_grace_time给运行错过时间为60s
scheduler.add_job(my_clock, trigger="interval", hours=8, args=["fmk"], id='my_clock', misfire_grace_time=60)
scheduler.start()
默认为0
4.同一任务积攒提交—coalesce
最常见的情形是 scheduler 被 shutdown 后重启,某个任务会积攒了好几次没执行,如 510次,下次这个作业被提交给执行器时,执行 10次。设置 coalesce=True 后,只会执行一次。
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
# 传参姓名
def my_clock(name):
print(f"Hello {name}! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler(jobstores=jobstores)
# 使用coalesce=True设置同一任务积攒提交时,只提交一个
scheduler.add_job(my_clock, coalesce=True, trigger="interval", seconds=10, args=["fmk"], id='my_clock', misfire_grace_time=5)
scheduler.start()
默认coalesce=False
5.同一任务同一时间的实例最大运行数—max_instances
max_instances=5:同一个任务同一时间最多只能有5个实例在运行。比如一个耗时10分钟的job,被指定每分钟运行1次,如果我max_instance值5,那么在第6~10分钟上,新的运行实例不会被执行,因为已经有5个实例在跑了。
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
# 传参姓名
def my_clock(name):
print(f"Hello {name}! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler(jobstores=jobstores)
# max_instances=5
scheduler.add_job(my_clock, max_instances=5,coalesce=True, trigger="interval", seconds=10, args=["fmk"], id='my_clock', misfire_grace_time=5)
scheduler.start()
正常任务耗时小于任务创建时间间隔的,默认max_instances=1,如果报错 可以增大max_instances的值,也可以看执行的任务,是否发生阻塞,导致执行任务时间过长,实例一直阻塞在此。进而解决问题
6.避免已有作业重新添加到数据库—replace_existing
将定时任务添加到数据库中:代码如下
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
# 传参姓名
def my_clock(name):
print(f"Hello {name}! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler(jobstores=jobstores)
# replace_existing=True
scheduler.add_job(my_clock, max_instances=5,coalesce=True, trigger="interval", seconds=10, args=["fmk"], id='my_clock', misfire_grace_time=5)
scheduler.start()
此时数据库中已有数据,程序重新启动后,再次运行就会报错。原因为该任务已经添加至数据库,再次运行程序重新添加一次,产生冲突,报错。可以设置replace_existing=True,重新启动就没有问题。

设置replace_existing=True,即数据库中已有任务冲突,重启是也不会再有问题。
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
# 传参姓名
def my_clock(name):
print(f"Hello {name}! The time is:{datetime.datetime.now()}")
if __name__ == '__main__':
scheduler = BlockingScheduler(jobstores=jobstores)
# replace_existing=True
scheduler.add_job(my_clock, replace_existing=True, max_instances=5,coalesce=True, trigger="interval", seconds=10, args=["fmk"], id='my_clock', misfire_grace_time=5)
scheduler.start()
五、APScheduler 任务操作
1. 添加任务—add_job
scheduler.add_job(job_obj,args,id,trigger,**trigger_kwargs)
2. 删除任务—remove_job
scheduler.remove_job(job_id,jobstore=None)
3. 暂停任务—pause_job
scheduler.pause_job(job_id,jobstore=None)
4. 恢复任务—resume_job
scheduler.resume_job(job_id,jobstore=None)
5.修改某个任务属性信息—modify_job
scheduler.modify_job(job_id,jobstore=None,**changes)
6. 修改单个作业的触发器并更新下次运行时间—reschedule_job
scheduler.reschedule_job(job_id,jobstore=None,trigger=None,**trigger_args)
7.输出作业信息—print_jobs
scheduler.print_jobs(jobstore=None,out=sys.stdout)
六、APScheduler 事件监听(add_listener)及日志
使用add_listener进行事件监听:我们可以在第一时间知道,定时任务发生导常事件
在生产环境中,可以把出错信息换成发送一封邮件或者发送一个短信,这样定时任务出错就可以立马就知道。
加入日志记录和事件监听,如下所示。
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
import datetime
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='log.txt',
filemode='a')
# 模拟正常任务
def test1(x):
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
# 模拟任务出错
def test2(x):
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
a = 1 / 0
# 添加事件监听
def my_listener(event):
if event.exception:
print('任务出错!!!')
else:
print('任务正常运行...')
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(func=test2, args=('单次任务,会出错,来学习事件监听',),
next_run_time=datetime.datetime.now() + datetime.timedelta(seconds=5), id='date_task')
scheduler.add_job(func=test1, args=('循环任务',), trigger='interval', seconds=3, id='interval_task')
scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
scheduler._logger = logging
scheduler.start()
6-10行:配置日志记录信息,在当前文件的统计目录下
12-13行:模拟正常任务
15-17行:模拟任务出错
19-23行:定义一个事件监听,出现意外情况打印相关信息报警。
30行:启动监听器
31行:启动日志
运行结果如下:每次定时任务执行都会被add_listener指定的my_listener监听,模拟的单次任务会出错,就会报告出来
