分布式梯队下降
Posted kexinxin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式梯队下降相关的知识,希望对你有一定的参考价值。
分布式梯队下降
并行模型
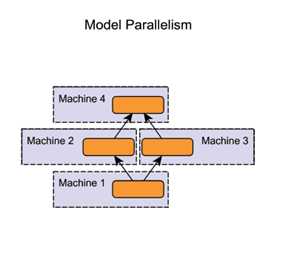
模型并行(model parallelism): 分布式系统中的不同机器(GPU/CPU等)负责网络模型的不同部分———例如,神经网络模型的不同网络层被分配到不同的机器,或者同一层内部道德不同参数被分配到不同机器。
数据并行(data parallelism): 不同的机器有同一个模型的多个副本,每个机器分配到不同的数据,然后将所有机器的计算结构按照某种方式合并。
并行方法
同步数据并行方法(Synchronous Data Parallel Methods)
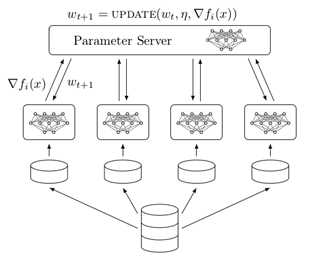
把数据切分很多小份,每一份训练数据扔到一个机器上,在该机器上即可根据本地数据来做训练,通过梯度下降更新神经网络。当每一个局部得到一些神经网络的更新之后,希望大家共同协作训练。大奖就会把自己学到的东西推送到一个公共的服务器上,服务器上就会看到所有的local machine送上来的东西,他会把他们做一个集成,集成了之后就会得到一个它认为考虑了所有的训练机器所有信息之后最好的模型的状态,然后再把最好的模型发送给每一个机器。然后每一个机器利用自己的局部参数去更新下一轮的数据。这样周而复始。这就是经典经典的参数服务器的架构。
同步的并行实现等价于某一个串行的梯度下降法,只不过min-batch的size变了。但是训练数据总是受限于最慢的机器。
参数平均(model averaging)
参数平均是最简单的一种数据并行化。若采用参数平均法,训练的过程如下所示:
- 基于模型的配置随机初始化网络模型的参数
- 将当前这组参数分发到各个工作节点
- 在每个工作节点,用数据集的一部分数据进行训练
- 将各个工作节点的参数的均值作为全局参数值
DASGD(Elastic Averaging SGD)
和参数平均方法过程相似,只不过不是将参数的均值作为全局参数值,而是每个worker服务器围绕着参数均值进行变化。
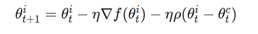
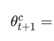
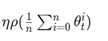
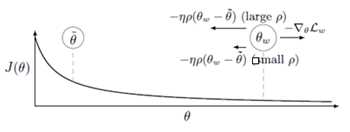
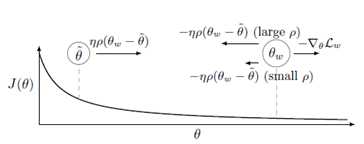
P值控制参数在最优模型之间浮动的大小。P值越大,说明在参数空间探索的范围越大,P值越接近中心参数。
异步数据并行方法
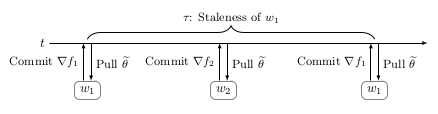
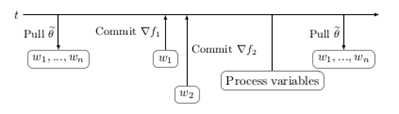
为了克服在同步数据并行中,由负载的worker引起的严重延迟问题,从而进一步减少训练时间,简单的方法就是去去除同步约束限制。但是,这又带来了一些影响,其中一些影响不是很明显。概念上最简单的是参数超时(Parameter staleness)。Parameter staleness是指当一个worker从central variable获取参数(pull)之后,再到下次提交参数到central variable之间的延迟的时间。直观地说,这意味着worker正在使用基于该模型的先前参数的梯度来更新模型参数。如上图所示,在时刻,从central variable获取参数到本地进行计算,当本地计算完成之后,在时刻把梯度提交到central variable进行参数更新,这之间的时间差称为的Parameter staleness。因为到之间,进行了一次梯度更新提交,所以时刻,的参数更新是延迟的,这样是不合理的。
异步EASGD
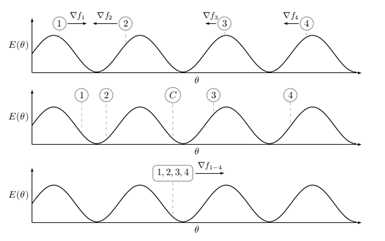
异步EASGD的更新方案与同步EASGD非常相似,但是也有一些重要的细节。在下面的描述中,我们将用向量表示弹性差(elastic different)。在同步版本中,该向量实际上用于实现对参数空间的探索的策略。这意味着,在方程
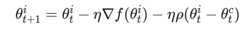
中,这个向量的任务是不让worker远离central variable。这正是,当将elastic different应用于worker时发生的情况。
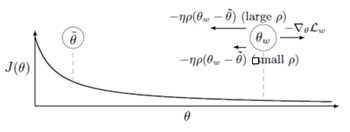
在异步版本中,elastic difference具有相同的功能。但是,它也被用来更新central variable。如上段所述,elastic different实际上用于参数空间的限制性探索。但是,如果我们否定elastic difference, 那就是,则elastic difference可以被用来优化所述central variable(图中的反向箭头),同时保持通行限制(communication constraint),这是EASGD正在努力解决的问题。
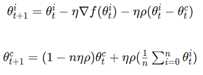
DOWNPOUR
在DOWNPOUR中,每当worker计算一个梯度(或梯度序列)时,梯队就与参数服务器通信。当参数服务器从worker那里接收到梯度更新请求时,它将把更新合并到central variable中,与EASGD相反,DOWNPOUR并不假设存在任何通信限制。更重要的是,如果与参数服务器的频繁通讯不发生(为了减少worker差异),DOWNPOUR并不假设存在任何通信限制。更重要的是,如果与参数服务器的频繁通讯不发生(为了减少worker差异),DOWNPUR将不会收敛(这也与由异步引起的动量问题有关)。这正与上面讨论的问题相同。如果我们允许worker探索"太多"的参数空间,那么所有的worker就不会一起努力去为了central variable找到一个好的解决方案。此外,DOWNPOUR没有任何固定有的机制来保持central variable的领域。因此,如果增加通讯窗口(communication window)大小,则会成比例地增加发送到参数服务器的梯度的长度。因此,为了使参数空间中worker的方差更"小",就需要积极更新central variable。
ADAG
我们注意到,一个大的communication windows与模型性能的下降有关。使用一些模型(如DOWNPOUR,如上所示),我们注意到,当使用communication window标准化累计梯度时,可以减轻这种影响。还有几个积极的影响,例如,对并行worker的数量,并没有进行标准化(normalizing),因此,也不会失去并行化梯度下降(收敛速度)带来的好处。这有一个副作用,即每个worker就central variable 产生的方差同样也会保持较小,因此,对central objective有积极作用!此外,由于规范化,模型对超参数也不太敏感,特别是communication window大小。然而,也就是说,大的communication window通常也会降低模型的性能,因为可以让worker基于数据分片(data shard)中的样本,探索更多的参数空间。在第一模型中,我们调整了DOWNPOUR来适应这个想法。我们观察到以下结果。首先,我们观察到模型性能显著提高,甚至于诸如Adam的顺序优化算法可比。其次,与DOWNPOUR相比,我们可以3倍大小增加communication window。因此,可以更有效地利用CPU资源,并且进一步减少总的训练时间。最后,归一化积累的梯度允许我们增大communication window。因此,我们能够匹配EASGD的训练时间,并且达到大致相同(有时更好,有时更差)的结果。
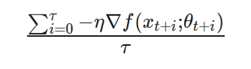
总之,ADAG或异步分布式自适应梯度算法的核心思想,可以应用与任何分布式优化的方案。使用我们的观察和直觉(特别是关于由异步引起的隐动量),我们可以猜测,归一化累计梯度的思想可以应用于任何分布式优化方案。
以上是关于分布式梯队下降的主要内容,如果未能解决你的问题,请参考以下文章
八一建军节阅兵,你最期待哪款战机梯队飞跃天安门,歼-20隐身战斗机如何
数据库流行度8月排行榜:Oracle 飙升 和 PostgreSQL 绝尘领跑第二梯队