scrapy的介绍组件数据流
Posted hy123456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy的介绍组件数据流相关的知识,希望对你有一定的参考价值。
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。
scrapy使用了twisted异步网络框架来处理网络通讯,来加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求
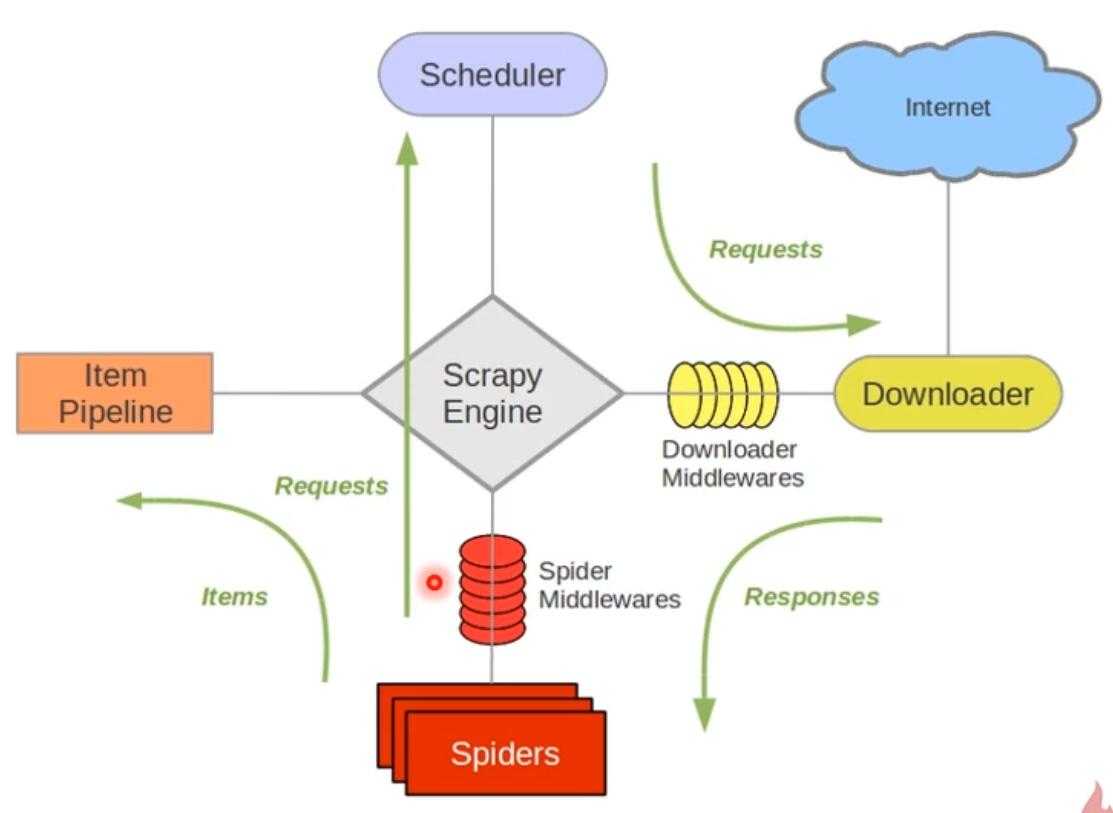
scrapy的工作流程:
1、首先spiders(爬虫)将需要发送请求的url(requests)经scrapyengine(引擎)交给scheduler(调度器)
2、scheduler(排序,入队)处理后,经scarpyengine,downloadermiddlewares交给downloader
3、downloader向互联网发送请求,并接受下载响应(response)。将响应(response)经scrapyengine,spidermiddlewares交给spiders
4、spiders处理response,提取数据并将数据经scrapyengine交给itempipeline保存(可以在本地,可以是数据库)
5、提取url重新经scrapyengine交给scheduler进行下一个循环。直到url请求程序停止结束

所以框架给我们了其他内容 我们要写的就是spider、 scrapy engine 、item pipeline 这三个内容
以上是关于scrapy的介绍组件数据流的主要内容,如果未能解决你的问题,请参考以下文章