现代机器学习算法的优缺点
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了现代机器学习算法的优缺点相关的知识,希望对你有一定的参考价值。
原文地址:https://elitedatascience.com/machine-learning-algorithms
在本指南中,我们将通过现代机器学习算法进行实用,简洁的介绍。虽然存在其他类似的指南列表,但它们并没有真正解释每种算法的实际权衡,这是我们希望在这里做的。 我们将根据自己的经验讨论每种算法的优缺点。
对机器学习算法进行分类是棘手的,有几种合理的方法; 机器学习算法可以分为生成/判别,参数/无参数,监督/非监督等分类。
例如,Scikit-Learn的文档页面按其学习机制对算法进行分组。 产生了如下类别:
l 通用线性模型
l 支持向量机
l 最近邻
l 决策树
l 神经网络
l 其他
但是,根据我们的经验,这并不总是最实用的分组算法。 那是因为对于应用机器学习,你通常不会想,“我今天想要训练一个支持向量机!”
相反,您通常会考虑最终目标,例如预测结果或对观察进行分类。
因此,我们想引入另一种方法区分机器学习算法,即通过机器学习算法适合什么任务来区分。
没有免费的午餐
在机器学习中,有一种称为“没有免费午餐”的定理。 简而言之,它表明没有一种算法能够最好地解决每个问题,并且它对于监督学习(即预测建模)尤其重要。
例如,您不能说神经网络总是比决策树更好,反之亦然。 有许多因素在起作用,例如数据集的大小和结构。
因此,您应该针对您的问题尝试许多不同的算法,同时使用数据的保留“测试集”来评估性能并选择获胜者。

当然,您尝试的算法必须适合您的问题,这是选择正确的机器学习任务的出发点。作为类比,如果您需要清理房屋,您可以使用真空吸尘器,扫帚或拖把 ,但你不会拿出铲子并开始挖地。
机器学习任务
这是本系列的第1篇文章。 在这一部分中,我们将介绍“三大”机器学习任务,这是迄今为止最常见的任务。 他们是:
1.回归问题
2.分类问题
3.聚类问题
在第2篇文章,我们将介绍降维技术,包括:
4.特征选择
5.特征提取
继续之前的两点说明:
l 我们不会介绍特定领域的变异算法,例如自然语言处理。
l 我们不会涵盖所有算法。 那会有太多需列出的内容,并且新的算法一直会冒出来。 但是,此列表将为您提供每个任务成功的当代算法的代表性概述。
1. 回归任务
回归是用于建模和预测连续数值变量的监督学习任务。 示例包括预测房地产价格,股票价格变动或学生考试成绩。
回归任务的特征在于具有数值型目标变量的标记数据集。 换句话说,每个观测对象有“基础事实”值用来监控您的算法。
1.1 正则化的线性回归
线性回归是回归任务中最常用的算法之一。 它以最简单的形式尝试将直/超平面拟合到数据集中(即只有2个变量时为直线,超过两个变量是多维超平面)。 正如您可能猜到的,当数据集中的变量之间存在线性关系时,它可以正常工作。
在实践中,简单的线性回归通常被其正则化的对应方程(LASSO,Ridge和Elastic-Net)所取代。 正则化是一种在模型损失函数中增加惩罚项以避免过度拟合的技术,并且应该允许调整惩罚的强度。
优点:线性回归很容易理解和解释,并且可以正则化以避免过度拟合。 此外,使用随机梯度下降可以使用新数据轻松更新线性模型。
缺点:当存在非线性关系时,线性回归表现不佳。 它们不够灵活,无法捕获更复杂的模式,添加正确的交叉特征或多项式可能非常棘手且耗时。
1.2 集成回归树
回归树(也叫决策树)通过反复将数据集拆分为单独的分支来分层学习,从而最大化每个分割的信息增益。 这种分支结构允许回归树自然地学习非线性关系。译者添加:例如分类回归树(CART),它既可以用来分类,又可以被用来进行回归。CART用作回归树时用平方误差最小化作为选择特征的准则;用作分类树时采用基尼指数最小化原则,进行特征选择,递归地生成二叉树。
集成方法,例如随机森林(RF)和梯度提升算法(GBM),结合了来自许多单独树木的预测。 我们不会在这里介绍它们的基础机制,但在实践中,RF通常表现非常好,而GBM更难调整,但往往具有更高的性能上限。译者添加:2014年出现XGBoost,被称为Kaggle神器,可用于回归,分类和排序。2017年1月出现微软开源的LightGBM,用于用于排序,分类。他针对XGBoost在性能上做了大量优化。2017年4月俄罗斯的Yandex开源了CatBoost,它可以很容易地与谷歌的TensorFlow和苹果公司的核心ML等深度学习框架相结合。俄国人的算法性能还是杠杠的。想想nginx.
优势:决策树可以学习非线性关系,并且对异常值非常稳健。 集成在实践中表现很好,赢得了许多经典(即非深度学习)机器学习比赛。
缺点:不受约束的单个回归树容易过度拟合,因为它们可以保持分支,直到它们记住所有训练数据。 但是,过拟合可以通过使用集成方法来缓解。
1.3深度学习
深度学习是指可以学习极其复杂模式的多层神经网络。 它们在输入和输出之间使用“隐藏层”,以模拟其他算法无法轻易学习的数据的中间表示。
它们有几个重要的机制,例如卷积和dropout,使它们能够有效地从高维数据中学习。 然而,与其他算法相比,深度学习仍然需要更多的数据来训练,因为模型需有更多的参数来估计。
优势:深度学习是某些领域的当前最新技术,例如计算机视觉和语音识别。 深度神经网络在图像,音频和文本数据上表现非常好,并且可以使用批量传播轻松更新新数据。 它们的架构(即层的数量和结构)可以适应许多类型的问题,并且它们的隐藏层减少了对特征工程的需求。
缺点:深度学习算法通常不适合作为通用算法,因为它们需要非常大量的数据。 实际上,对于经典机器学习问题,它们通常优于集成树。 但是,它们在训练时计算密集,并且它们需要更多的专业知识来调整(即设置架构和超参数)
1.4荣誉提名-最近邻
最近邻算法是“基于实例的”,这意味着保存每个训练对象。 然后,他们通过搜索最相似的训练观察并汇集其值来对新观察进行预测。
这些算法是存储密集型,对于高维数据执行不良,并且需要有意义的距离函数来计算相似性。 在实践中,训练正则化线性回归或集成树几乎总是更好地利用你的时间。
2. 分类任务
分类是用于建模和预测分类变量的监督学习任务。 示例包括预测员工流失,电子邮件垃圾邮件,财务欺诈或学生信函等级。
正如您将看到的,许多回归算法都有分类对应。 算法适用于预测类(或类概率)而不是实数。
2.1正则化的逻辑回归
Logistic回归是线性回归的分类对应物。 预测通过逻辑函数映射到0到1之间,这意味着预测可以解释为类概率。
模型本身仍然是“线性的”,因此当类可线性分离时它们可以很好地工作(即它们可以由单个决策表面分隔)。 逻辑回归也可以通过用可调惩罚强度惩罚系数来规则化。
译者添加:LR是一种广泛使用的技术,因为它解释的是概率而不是分类,它不需要缩放输入特征值,它不需要任何调优。当您删除与输出变量无关的属性或者彼此非常相似(相关)的属性时,逻辑回归确实更有效。因此,Logistic在特征选择方面也发挥着重要作用。
优点:输出具有良好的概率解释,并且算法可以被正则化以避免过度拟合。 使用随机梯度下降可以使用新数据轻松更新逻辑模型。
缺点:当存在多个或非线性决策边界时,逻辑回归往往表现不佳。 它们不够灵活,不能自然地捕捉更复杂的关系。
2.2 集成分类树
分类树是回归树的分类对应物。 它们通常被称为“决策树”或通过总称“分类和回归树(CART)”。
优势:与回归一样,分类树集成在实践中也表现得非常好。 它们对异常值具有鲁棒性,可扩展,并且由于其层次结构,能够自然地模拟非线性决策边界。
缺点:无约束的单个分类树容易过度拟合,但这可以通过集成方法得到缓解。
2.3深度学习
为了延续这一趋势,深度学习也很容易适应分类问题。 实际上,分类通常是深度学习的较常见用途,例如图像分类。
优点:深度学习在分类音频,文本和图像数据时表现良好。
缺点:与回归一样,深度神经网络需要非常大量的数据来训练,因此它不被视为通用算法。
2.4支持向量机
支持向量机(SVM)使用称为核函数的机制,它基本上计算两个观察之间的距离。 然后,SVM算法找到决策边界,该边界最大化单独类的距离决策边界最近成员之间的距离。
例如,具有线性核函数的SVM类似于逻辑回归。 因此,在实践中,SVM的好处通常来自使用非线性核函数来模拟非线性决策边界。
优势:SVM可以模拟非线性决策边界,并且有许多核函数可供选择。 它们对过度拟合也相当强大,特别是在高维空间。
缺点:然而,SVM是内存密集型的,由于选择正确核函数的重要性而难以调整,并且不能很好地扩展到更大的数据集。 目前在行业里,随机森林通常优于SVM。
2.5朴素贝叶斯
朴素贝叶斯(NB)是一种基于条件概率和计数的非常简单的算法。 从本质上讲,您的模型实际上是一个通过您的训练数据更新的概率表。 要预测新观察,您只需根据其特征值“查找”“概率表”中的类概率。
它被称为“朴素”,因为它的核心假设是条件独立的(即所有输入特征彼此独立)在现实世界中很少完全成立。
优势:尽管条件独立假设很少成立,但NB模型实际上在实践中表现出色,特别是它们的简单性。 它们易于实现,可以根据您的数据集进行扩展。
缺点:由于非常简单,NB模型经常被经过适当训练的其他分类模型打败,并使用之前列出的算法进行调优。
3. 聚类任务
聚类是一种无监督的学习任务,用于根据数据集中的固有结构查找自然的观察分组(即聚类)。 示例包括客户细分,在电子商务中对类似项目进行分组以及社交网络分析。
由于聚类是无监督的(即没有“正确答案”),因此通常使用数据可视化来评估结果。 如果存在“正确答案”(即您在训练集中预先标记了群集),则分类算法通常更合适。
译者添加:高纬度数据集的可视化分类,还没有搜集齐,不知道是不是简单的降维就可以。
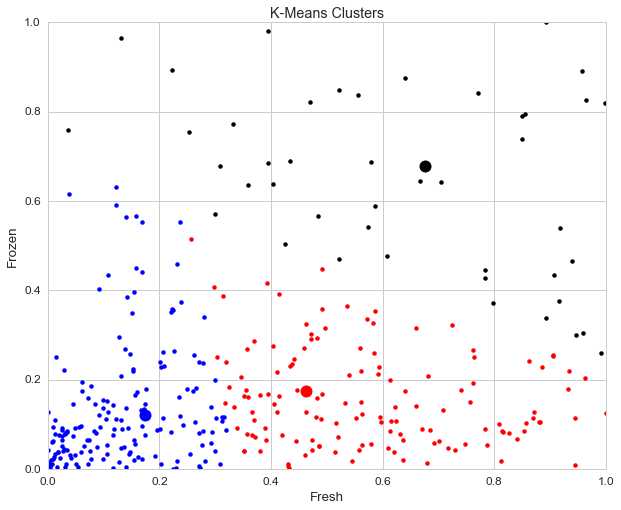
3.1 K-Means
K-Means是一种通用算法,它基于点之间的几何距离(即坐标平面上的距离)来制作聚类。 聚类围绕质心分组,使它们呈球状并具有相似的大小。
这是我们推荐的初学者算法,因为它简单,但足够灵活,可以为大多数问题获得合理的结果。
优势:K-Means是最受欢迎的聚类算法,因为它可以快速,简单,并且如果您预处理数据并设计有用的功能,则会非常灵活。
缺点:用户必须指定群集的数量,这并不总是容易做到的。 此外,如果数据中真正的基础聚类不是球状的,那么K-Means将产生较差的聚类。
3.2分层聚类
分层聚类,即a.k.a.凝聚聚类,是基于相同思想的一套算法:(1)从它自己的聚类中的每个点开始。 (2)对于每个集群,根据某些标准将其与另一个集群合并。 (3)重复直到只剩下一个簇,并留下簇的层次结构。
优势:分层聚类的主要优点是不假设聚类是球状的。 此外,它可以很好地扩展到更大的数据集。
缺点:与K-Means非常相似,用户必须选择簇的数量(即算法完成后最底层次结构数量)。
3.4 DBSCAN
DBSCAN是一种基于密度的算法,可以为密集的点区域创建聚类。 最近还有一个名为HDBSCAN的新开发项目,它允许不同密度的簇。
优势:DBSCAN不假设球状星团,其性能可扩展。 此外,它不需要将每个点分配给集群,从而降低集群的噪声(这可能是一个弱点,具体取决于您的用例)。
缺点:用户必须调整超参数‘epsilon‘和‘min_samples‘,它们定义了簇的密度。 DBSCAN对这些超参数非常敏感。
离别的话
我们刚刚旋风式探索了“三大”机器学习任务:回归,分类和聚类。
在第2篇文章中,我们将研究降维的算法,包括特征选择和特征提取。
但是,我们希望根据自己的经验给您一些建议:
- 首先......练习,练习,练习。 阅读算法可以帮助您在一开始就找到自己的立足点,但真正的掌握来自于练习。 当您完成项目和/或竞赛时,您将培养实用的直觉,这使您能够获得几乎任何算法并有效地应用它。
- 第二......掌握基础知识。 我们无法在此列出许多算法,其中一些算法在特定情况下非常有效。 但是,几乎所有这些都是对此列表中算法的一些改编,这将为应用机器学习提供坚实的基础。
- 最后,请记住,更好的数据优于更高级的算法。 在应用机器学习中,算法是商品,因为您可以根据问题轻松切换它们。 但是,有效的探索性分析,数据清理和特征工程可以显着提高您的结果。
如果您想了解有关应用机器学习工作流程以及如何有效培训专业级模型的更多信息,我们邀请您查看我们的数据科学入门。
对于更多的细致指导,我们还提供了一个全面的大师课程,进一步解释了许多这些算法背后的直觉,并教你如何将它们应用于现实世界的问题。
以上是关于现代机器学习算法的优缺点的主要内容,如果未能解决你的问题,请参考以下文章