机器学习常见算法优缺点总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习常见算法优缺点总结相关的知识,希望对你有一定的参考价值。
机器学习常见算法优缺点总结
K近邻:算法采用测量不同特征值之间的距离的方法进行分类。
优点:
1.简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归;
2.可用于数值型数据和离散型数据;
3.训练时间复杂度为O(n);无数据输入假定;
4.对异常值不敏感
缺点:
1.计算复杂性高;空间复杂性高;
2.样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
3.一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少 否则容易发生误分。
4.最大的缺点是无法给出数据的内在含义。
朴素贝叶斯
优点:
1.生成式模型,通过计算概率来进行分类,可以用来处理多分类问题,
2.对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法也比较简单。
缺点:
1.对输入数据的表达形式很敏感,
2.由于朴素贝叶斯的“朴素”特点,所以会带来一些准确率上的损失。
3.需要计算先验概率,分类决策存在错误率。
决策树
优点:
1.概念简单,计算复杂度不高,可解释性强,输出结果易于理解;
2.数据的准备工作简单, 能够同时处理数据型和常规型属性,其他的技术往往要求数据属性的单一。
3.对中间值得确实不敏感,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
4.应用范围广,可以对很多属性的数据集构造决策树,可扩展性强。决策树可以用于不熟悉的数据集合,并从中提取出一些列规则 这一点强于KNN。
缺点:
1.容易出现过拟合;
2.对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
3. 信息缺失时处理起来比较困难。 忽略数据集中属性之间的相关性。
SVM
优点:
1.可用于线性/非线性分类,也可以用于回归,泛化错误率低,计算开销不大,结果容易解释;
2.可以解决小样本情况下的机器学习问题,可以解决高维问题 可以避免神经网络结构选择和局部极小点问题。
3.SVM是最好的现成的分类器,现成是指不加修改可直接使用。并且能够得到较低的错误率,SVM可以对训练集之外的数据点做很好的分类决策。
缺点:对参数调节和和函数的选择敏感,原始分类器不加修改仅适用于处理二分类问题。
Logistic回归:根据现有数据对分类边界线建立回归公式,依次进行分类。
优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低;
缺点:容易欠拟合,分类精度可能不高
EM 期望最大化算法-上帝算法 只要有一些训练数据,再定义一个最大化函数,采用EM算法,利用计算机经过若干次迭代,就可以得到所需的模型。EM算法是自收敛的分类算法,既不需要事先设定类别也不需要数据见的两两比较合并等操作。缺点是当所要优化的函数不是凸函数时,EM算法容易给出局部最佳解,而不是最优解。
【参考文献】
机器学习–判别式模型与生成式模型
http://www.cnblogs.com/fanyabo/p/4067295.html
数据挖掘十大算法—-EM算法(最大期望算法)
http://www.tuicool.com/articles/Av6NVzy
各种分类算法的优缺点 - 学习笔记1.0 - 经管之家(原人大经济论坛)
http://bbs.pinggu.org/thread-2604496-1-1.html
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
http://www.cnblogs.com/tornadomeet/p/3395593.html
吴军.数学之美[M].北京:人民邮电出版社,2014.
Peter Harrington,李锐,李鹏,曲亚东,王斌.机器学习实战[M].北京:人民邮电出版社2013.
李航.统计学习方法[M].北京:清华大学出版社 2012.
杉山将,许永伟.图解机器学习[M].北京:人民邮电出版社2015.
斯坦福大学公开课 :机器学习课程
LEARNING REPRESENTATIONS FROM EEG WITH DEEP RCNN读书笔记
论文:《LEARNING REPRESENTATIONS FROM EEG WITH DEEP RECURRENT-CONVOLUTIONAL NEURAL NETWORKS》
文章来源:arXiv 2016
原文链接已附上。
一、论文简介
这篇文章是将脑电信号经过一系列处理之后做成image然后用ConvNet 、LSTM等方法来进行特征提取,最后得出分类结果。
二、论文创新点
本文主要是提出了一种新的脑电特征表达方法。一般脑电处理方法只包含了时域特征和频域特征并未包含空域特征,本文增加了空域特征来对脑电进行分析。
三、 数据集介绍
这是一个记录记忆容量的脑电实验。实验步骤如下:黑纸白字给出一些列英文字母为时0.5S让被试来记忆,然后间隔三秒开始测试,每次出现一个字母,被试做出选择是否出现在刚才的数据集中。我们分别识别包含2个,4个,6个,8个字符的每个条件分别为负载1,2,3,4。共13个被试,每个被试做240次实验。每次实验记录前3.5秒的脑电数据。分类任务是从EEG记录中识别对应于设置大小(呈现给主题的字符数)的负载水平。
四、本文主要工作
1) Fast Fourier Transform(FFT) is performed on the time seriesfor each trial to estimate the power spectrum of the signal.
2) Sumof squared absolute values within each of the three frequency bands wascomputed and used as separate measurement for each electrode.
3) we propose to transform the measurementsinto a 2-D image to preserve the spatial structure and use multiple colorchannels to represent the spectral dimension.
4) Finally,we use the sequence of images derived from consecutive time windows to account fortemporal evolutions in brain activity.
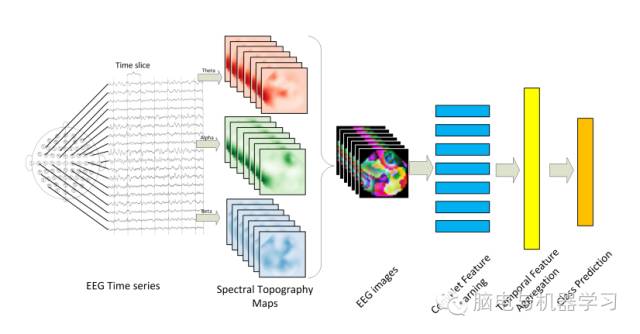
首先在脑电的时序序列上进行快速傅里叶变换对每一次试验预测功率谱.然后用平方和绝对值方法计算每一导脑电信号中三个频率的度量值。三个频率分别是:theta (4-7Hz), alpha(8-13Hz),beta (13-30Hz)。
接着,用本文提出的方法将计算出的度量值转换成2-D图像。
最后用这些图像序列来表示大脑活动,即作为输入输进分类器。
五、分类器
这篇文章将图片做了两种格式的转换,一种是单图方法,一种是多图方法。单图方法是对于一次实验只生成一张图片,然后输入到ConvNet网络中。这种做法是为了选择出用来提取特征的最佳卷积结构。另外一种多图方法是将3.5S的数据每0.5S做成一张图每个通道得七张图,然后将三通道图片结合在一起成为七张图片序列输入到分类器。这里的最佳卷积结构作为分类器得一部分存在,再分别加上max-pooling、LSTM和1-D卷积网络等做成一个分类器。
采用的结构示意图:
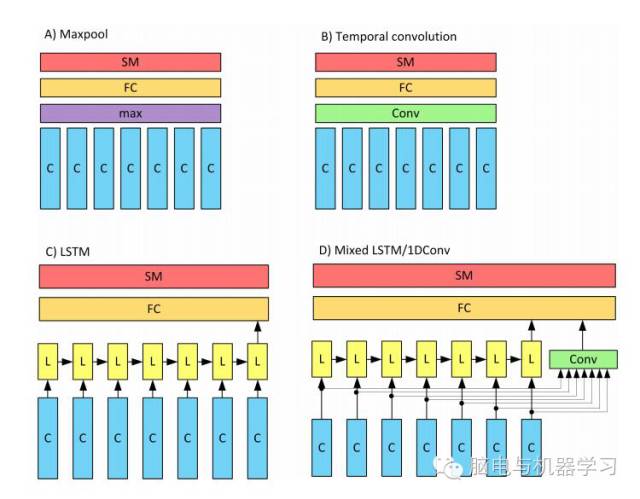
其中蓝条C即先前选出的最佳卷积结构,此处是下图D的七层结构:

六、结果讨论
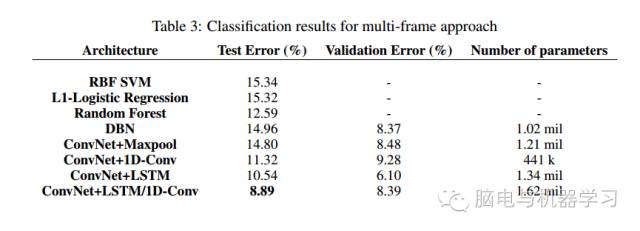
这里可以看出效果还是不错的,提升了许多 错误率从15.34%降到8.9%。此外文章中还有单幅图分类效果和多幅图的分类效果比较本文中未再贴出,只给出最终的结构和分类效果的分析。本文中的方法效果显著提出的加入空域特征的创新点在脑电处理方面值得借鉴。
以上是关于机器学习常见算法优缺点总结的主要内容,如果未能解决你的问题,请参考以下文章