爬取页面和审查元素获取的内容不一致
Posted yuantup
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取页面和审查元素获取的内容不一致相关的知识,希望对你有一定的参考价值。
今天看书看到 图片爬虫实战之爬取京东手机图片 这一节,想着自己动手练习一下,因为以前看过视频所以思路还是比较清晰,主要是为了复习巩固刚刚学的正则表达式。
打开京东手机页面,
https://list.jd.com/list.html?cat=9987,653,655&page=1&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main
审查元素发现手机图片有两种格式:
1.每一页的前十是这样的

2.第十一个开始是这样的

仔细看了看区别就是多了一个 data-lazy-img 和 title
心想简单啊我写两个正则表达式匹配一下不就行了,于是:

为了求稳,先测试了一下能否正确获取我需要的地址:结果只有10个地址。心想是不是"."不能匹配换行符的原因啊,于是
各种百度查资料保证"."可以匹配换行符。。。emmmm,还是不行
于是我就看书上是咋写的 ,书上写的是:

我一看不对啊,这和说好的不一样啊啊
我用他的试了试,确实找到了50张图片的地址(一页共有60个手机信息,前十个是可以正常爬取地址的)
下载下来的图片:
为了验证我的正则表达式哪里出错了,我把下载下来的地址复制到浏览器F12打开的界面中去查找:
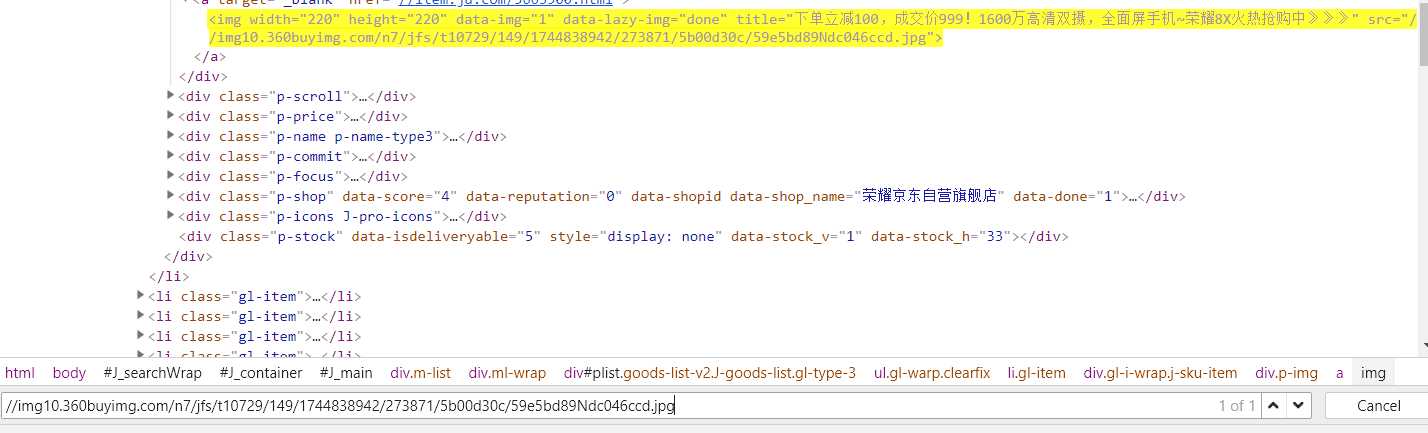
这和他给的正则表达式不一样把!!!怎么匹配上的
我还尝试了将下图中title中的内容复制到源代码中查找,也没有!

这个时候我发现不对劲了,因为我re能匹配到东西,所以我请求的网页中是有这个内容的,但是网页源代码中没有,说明
我请求到的网页代码和浏览器审查元素显示的代码不一致
找到问题之后,一通百度,啥有用的都没看到。
突然想到以前在一本爬虫书上看到过有一章叫做——动态网站抓取(这本书只看了基础知识介绍就没看了,因为它使用的是python2的版本,我看书之前喜欢先看大纲和目录,有个大概的印象)
翻出来一看,知道了。
所谓查看网页源代码,就是别人服务器发送到浏览器的原封不动的代码。这是爬虫获得的代码
你那些在源码中找不到的代码(元素),那是在浏览器执行js动态生成的,这些能在审查元素中看到
通过审查元素就 看到就是浏览器处理过的最终的html代码。
解决办法:一种是直接从javascript中采集加载的数据,用json模块处理;
另一种方式是直接采集浏览器中已经加载好的数据,借助工具--PhantomJS
最后,这个问题圆满解决了
附上代码和运行结果截图:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/10/8 15:11 # @Author : yuantup # @Site : # @File : jdshouji_image.py # @Software: PyCharm import urllib.request import re import os def open_url(url): head = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/5‘ ‘37.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘} req = urllib.request.Request(url, headers=head) response = urllib.request.urlopen(req) # print(response.getcode()) html = response.read() return html def get_img_addr(html): html_str = html.decode(‘utf-8‘) # print(html_str) img_addrs =[] pattern1 = ‘<img width="220" height="220" data-img="1" src="(.+?[.jpg|.png])"‘ pattern2 = ‘<img width="220" height="220" data-img="1" data-lazy-img="done" title=.+? src="(.+?[.jpg|.png])"‘ pattern2 = ‘<img width="220" height="220" data-img="1" data-lazy-img="(.+?[.jpg|.png])"‘ img_addrs1 = re.compile(pattern1).findall(html_str) # print(img_addrs) img_addrs2 = re.compile(pattern2).findall(html_str) # print(len(img_addrs)) img_addrs.extend(img_addrs1) img_addrs.extend(img_addrs2) print(img_addrs) return img_addrs def save_img(img_addrs): i = 0 for each in img_addrs: i = i+1 img_name = each.split("/")[-1] with open(img_name, ‘wb‘) as f: correct_url = ‘http:‘ + each img = open_url(correct_url) f.write(img) return i def main(): path = ‘E:spiser_sonsshouji_img‘ a = os.getcwd() print(a) if os.path.exists(path): os.chdir(path) print(os.getcwd()) else: os.mkdir(path) # os.chdir(path) for i in range(1, 11): url = ‘https://list.jd.com/list.html?cat=9987,653,655&page=‘ + str(i) html = open_url(url) img_addrs = get_img_addr(html) print(url) save_img(img_addrs) if __name__ == ‘__main__‘: main()
以上是关于爬取页面和审查元素获取的内容不一致的主要内容,如果未能解决你的问题,请参考以下文章